Congratulations! VIPL's 4 papers are accepted by AAAI (AAAI Conference on Artificial Intelligence) 2025! AAAI is a top-tier international conference on artificial intelligence. In this year, AAAI will be held in Philadelphia, USA on Feb. 25th through Mar. 4th, 2025. The accepted papers are summarized as follows:
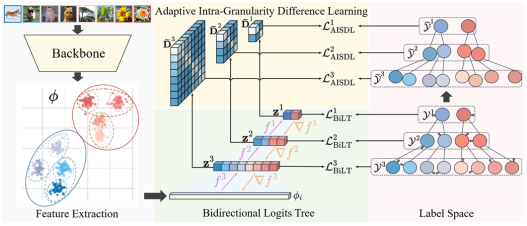
1. Bidirectional Logits Tree: Pursuing Granularity Reconcilement in Fine-Grained Classification (Zhiguang Lu, Qianqian Xu, Shilong Bao, Zhiyong Yang, Qingming Huang)
In the process of image classification with multi-granularity hierarchical labels, existing methods typically develop independent hierarchical-aware models based on shared features extracted from general feature extractors. However, since coarse-grained features are inherently easier to learn than fine-grained features, feature extractors tend to prioritize the learning of coarse-grained features, often neglecting fine-grained feature learning. This results in poor performance when the model learns fine-grained features. This paper proposes a method based on a Bidirectional Logical Tree (BiLT) and Adaptive Intra-Granularity Difference Learning (AIGDL), utilizing a backward propagation flow from coarse-grained to fine-grained features. By combining Logit losses across different levels, this approach ensures that fine-grained learning benefits from its coarse-grained ancestors, while dynamically adjusting the preset inter-class distances through inter-class relationship learning and label smoothing techniques. Experimental results verify that this method alleviates the Granularity Competition issue while improving fine-grained classification performance.
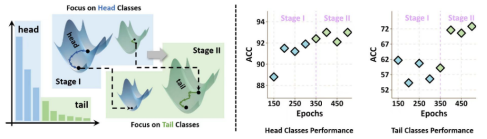
2. SSE-SAM: Balancing Head and Tail Classes Gradually through Stage-Wise SAM (Xingyu Lyu, Qianqian Xu, Zhiyong Yang, Shaojie Lyu, Qingming Huang)
Real-world datasets often exhibit a long-tailed distribution, where vast majority of classes known as tail classes have only few samples. Traditional methods tend to overfit on these tail classes. Recently, a new approach called Imbalanced SAM (ImbSAM) is proposed to leverage the generalization benefits of Sharpness-Aware Minimization (SAM) for long-tailed distributions. The main strategy is to merely enhance the smoothness of the loss function for tail classes. However, we argue that improving generalization in long-tail scenarios requires a careful balance between head and tail classes. We show that neither SAM nor ImbSAM alone can fully achieve this balance. For SAM, we prove that although it enhances the model's generalization ability by escaping saddle point in the overall loss landscape, it does not effectively address this for tail-class losses. Conversely, while ImbSAM is more effective at avoiding saddle points in tail classes, the head classes are trained insufficiently, resulting in significant performance drops. Based on these insights, we propose Stage-wise Saddle Escaping SAM (SSE-SAM), which uses complementary strengths of ImbSAM and SAM in a phased approach. Initially, SSE-SAM follows the majority sample to avoid saddle points of the head-class loss. During the later phase, it focuses on tail-classes to help them escape saddle points. Our experiments confirm that SSE-SAM has better ability in escaping saddles both on head and tail classes, and shows performance improvements.
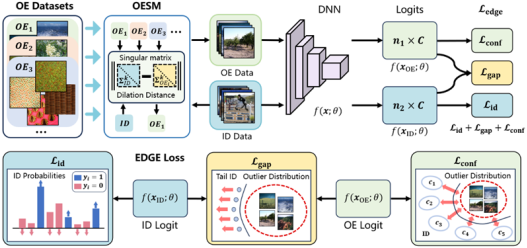
3. EDGE: Unknown-aware Multi-label Learning by Energy Distribution Gap Expansion (Yuchen Sun, Qianqian Xu, Zitai Wang, Zhiyong Yang, Junwei He)
Multi-label Out-Of-Distribution (OOD) detection aims to discriminate the OOD samples from the multi-label In-Distribution (ID) ones. Compared with its multiclass counterpart, it is crucial to model the joint information among classes. To this end, JointEnergy, which is a representative multi-label OOD inference criterion, summarizes the logits of all the classes. However, we find that JointEnergy can produce an imbalance problem in OOD detection, especially when the model lacks enough discrimination ability. Specifically, we find that the samples only related to minority classes tend to be classified as OOD samples due to the ambiguous energy decision boundary. Besides, imbalanced multi-label learning methods, originally designed for ID ones, would not be suitable for OOD detection scenarios, even producing a serious negative transfer effect. In this paper, we resort to auxiliary outlier exposure (OE) and propose an unknown-aware multi-label learning framework to reshape the uncertainty energy space layout. In this framework, the energy score is separately optimized for tail ID samples and unknown samples, and the energy distribution gap between them is expanded, such that the tail ID samples can have a significantly larger energy score than the OOD ones. What's more, a simple yet effective measure is designed to select more informative OE datasets. Finally, comprehensive experimental results on multiple multi-label and OOD datasets reveal the effectiveness of the proposed method.
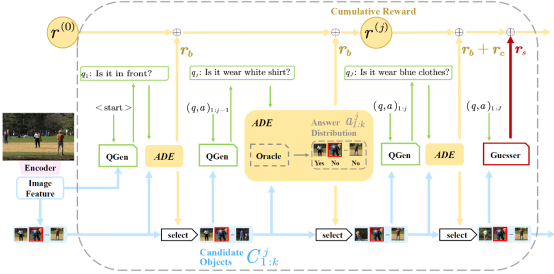
4. Divide-and-Conquer: Tree-structured Strategy with Answer Distribution Estimator for Goal-Oriented Visual Dialogue (Shuo Cai, Xinzhe Han, Shuhui Wang)
Goal-oriented visual dialogue involves multi-round interaction between artificial agents, which has been of remarkable attention due to its wide applications. Given a visual scene, this task occurs when a Questioner asks an action-oriented question and an Answerer responds with the intent of letting the Questioner know the correct action to take. The quality of questions affects the accuracy and efficiency of the target search progress. However, existing methods lack a clear strategy to guide the generation of questions, resulting in the randomness in the search process and unconverged results. We propose a Tree-Structured Strategy with Answer Distribution Estimator (TSADE) which guides the question generation by excluding half of the current candidate objects in each round. The above process is implemented by maximizing a binary reward inspired by the ``divide-and-conquer'' paradigm. We further design a candidate-minimization reward which encourages the model to narrow down the scope of candidate objects toward the end of the dialogue. We experimentally demonstrate that our method can enable the agents to achieve high task-oriented accuracy with fewer repeating questions and rounds compared to traditional ergodic question generation approaches. Qualitative results further show that TSADE facilitates agents to generate higher-quality questions.
Download: