Congratulations! VIPL's 9 papers are accepted by NeurIPS 2025. NeurIPS, officially known as Annual Conference on Neural Information Processing Systems, is a top-tier conference in the field of artificial intelligence. The conference will be held in San Diego, USA from December 2nd to December 7th.
The accepted papers are summarized as follows.
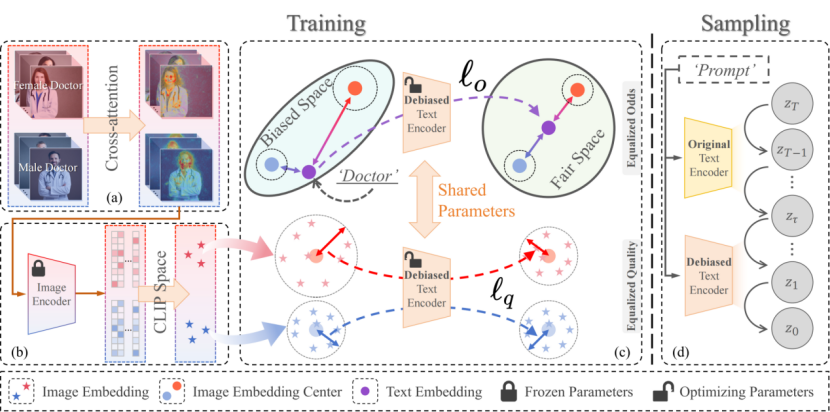
1. LightFair: Towards an Efficient Alternative for Fair T2I Diffusion via Debiasing Pre-trained Text Encoders (Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Kangli Zi, Qingming Huang)
Current text-to-image diffusion models (T2I DMs) generally suffer from imbalanced output distributions and latent biases. This paper explores a novel lightweight approach LightFair to achieve fair T2I DMs by addressing the adverse effects of the text encoder. Most existing methods either couple different parts of the diffusion model for full-parameter training or rely on auxiliary networks for correction. They incur heavy training or sampling burden and unsatisfactory performance. Since T2I DMs consist of multiple components, with the text encoder being the most fine-tunable and front-end module, this paper focuses on mitigating bias by fine-tuning text embeddings. To validate feasibility, we observe that the text encoder’s neutral embedding output shows substantial skewness across image embeddings of various attributes in the CLIP space. More importantly, the noise prediction network further amplifies this imbalance. To finetune the text embedding, we propose a collaborative distance-constrained debiasing strategy that balances embedding distances to improve fairness without auxiliary references. However, mitigating bias can compromise the original generation quality. To address this, we introduce a two-stage text-guided sampling strategy to limit when the debiased text encoder intervenes. Extensive experiments demonstrate that LightFair is effective and efficient. Notably, on Stable Diffusion v1.5, our method achieves SOTA debiasing at just 1/4 of the training burden, with virtually no increase in sampling burden.
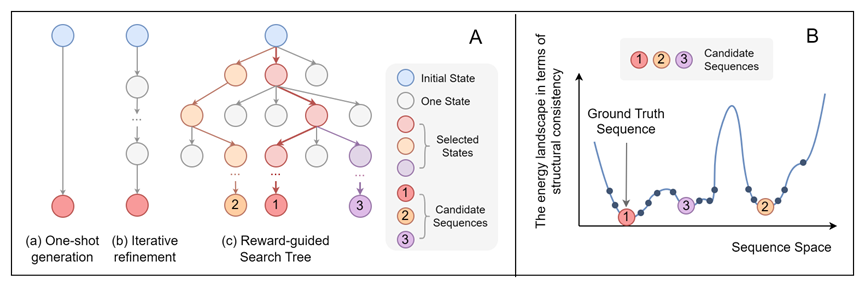
2. ProtInvTree: Deliberate Protein Inverse Folding with Reward-guided Tree Search (Mengdi Liu, Xiaoxue Cheng, Zhangyang Gao, Hong Chang, Cheng Tan, Shiguang Shan, Xilin Chen)
Designing protein sequences that fold into a target 3D structure—known as protein inverse folding—is a fundamental challenge in protein engineering. While recent deep learning methods have achieved impressive performance by recovering native sequences, they often overlook the one-to-many nature of the problem: multiple diverse sequences can fold into the same structure. This motivates the need for a generative model capable of designing diverse sequences while preserving structural consistency. To address this trade-off, we introduce ProtInvTree, the first reward-guided tree-search framework for protein inverse folding. ProtInvTree reformulates sequence generation as a deliberate, step-wise decision-making process, enabling the exploration of multiple design paths and exploitation of promising candidates through self-evaluation, lookahead, and backtracking. We propose a two-stage focus-and-grounding action mechanism that decouples position selection and residue generation. To efficiently evaluate intermediate states, we introduce a jumpy denoising strategy that avoids full rollouts. Built upon pretrained protein language models, ProtInvTree supports flexible test-time scaling by expanding the search depth and breadth without retraining. Empirically, ProtInvTree outperforms state-of-the-art baselines across multiple benchmarks, generating structurally consistent yet diverse sequences, including those far from the native ground truth.
3. un2CLIP: Improving CLIP's Visual Detail Capturing Ability via Inverting unCLIP (Yinqi Li, Jiahe Zhao, Hong Chang, Ruibing Hou, Shiguang Shan, Xilin Chen)
Contrastive Language-Image Pre-training (CLIP) has become a foundation model and has been applied to various vision and multimodal tasks. However, recent works indicate that CLIP falls short in distinguishing detailed differences in images and shows suboptimal performance on dense-prediction and vision-centric multimodal tasks. Therefore, this work focuses on improving existing CLIP models, aiming to capture as many visual details in images as possible. We find that a specific type of generative models, unCLIP, provides a suitable framework for achieving our goal. Specifically, as illustrated in Figure (a), unCLIP trains an image generator conditioned on the CLIP image embedding. In other words, it inverts the CLIP image encoder. Compared to discriminative models like CLIP, generative models are better at capturing image details because they are trained to learn the data distribution of images. Additionally, the conditional input space of unCLIP aligns with CLIP's original image-text embedding space. Therefore, we propose to invert unCLIP (dubbed un2CLIP) to improve the CLIP model, as illustrated in Figure (c). In this way, the improved image encoder can gain unCLIP's visual detail capturing ability while preserving its alignment with the original text encoder simultaneously. We evaluate our improved CLIP across various tasks to which CLIP has been applied, including the challenging MMVP-VLM benchmark, the dense-prediction open-vocabulary segmentation task, and multimodal large language model tasks. Experiments show that un2CLIP significantly improves the original CLIP and previous CLIP improvement methods. For more details, please refer to our paper https://arxiv.org/abs/2505.24517.
Code link:https://github.com/LiYinqi/un2CLIP

4. Revisiting Logit Distributions for Reliable Out-of-Distribution Detection (Jiachen Liang, Ruibing Hou, Minyang Hu, Hong Chang, Shiguang Shan, Xilin Chen)
Out-of-distribution (OOD) detection is critical for ensuring the reliability of deep learning models in open-world applications. While post-hoc methods are favored for their efficiency and ease of deployment, existing approaches often underexploit the rich information embedded in the model’s logits space. In this paper, we propose LogitGap, a novel post-hoc OOD detection method that explicitly exploits the relationship between the maximum logit and the remaining logits to enhance the separability between in-distribution (ID) and OOD samples. To further improve its effectiveness, we refine LogitGap by focusing on a more compact and informative subset of the logit space. Specifically, we introduce a training-free strategy that automatically identifies the most informative logits for scoring. We provide both theoretical analysis and empirical evidence to validate the effectiveness of our approach. Extensive experiments on both vision-language and vision-only models demonstrate that LogitGap consistently achieves state-of-the-art performance across diverse OOD detection scenarios and benchmarks.
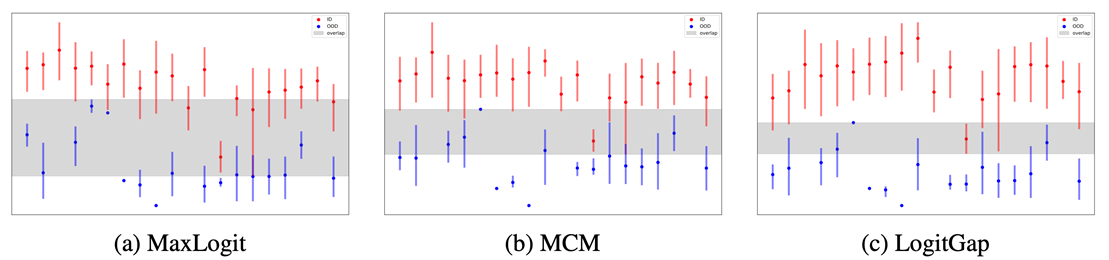
Figure: OOD score distributions for ID and OOD samples across scoring functions.
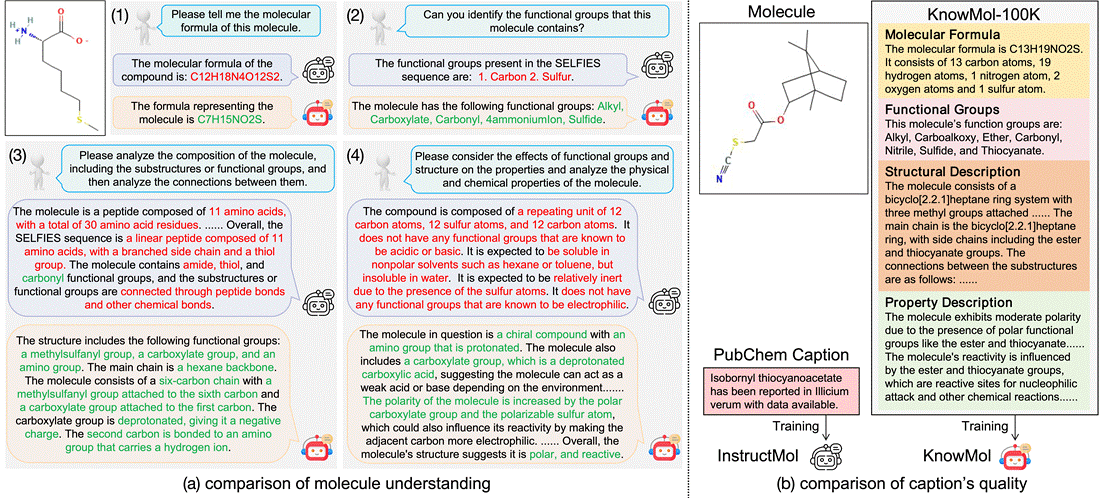
5. KnowMol: Advancing Molecular Large Language Models with Multi-Level Chemical Knowledge (Zaifei Yang, Hong Chang, RuiBing Hou, Shiguang Shan, Xilin Chen)
The molecular large language models have garnered widespread attention due to their promising potential on molecular applications. However, current molecular large language models face significant limitations in understanding molecules due to inadequate textual descriptions and suboptimal molecular representation strategies during pretraining. To address these challenges, we introduce KnowMol-100K, a large-scale dataset with 100K fine-grained molecular annotations across multiple levels, bridging the gap between molecules and textual descriptions. Additionally, we propose chemically-informative molecular representation, effectively addressing limitations in existing molecular representation strategies. Building upon these innovations, we develop KnowMol, a state-of-the-art multi-modal molecular large language model. Extensive experiments demonstrate that KnowMol achieves superior performance across molecular understanding and generation tasks.
GitHub: https://github.com/yzf-code/KnowMol
Huggingface: https://hf.co/datasets/yzf1102/KnowMol-100K
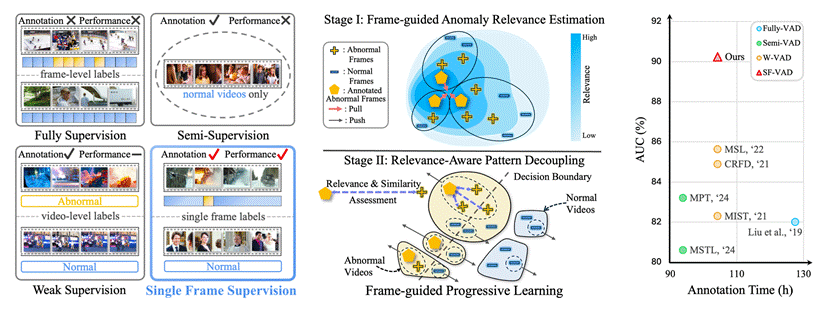
6. Generalizing Single-Frame Supervision to Event-Level Understanding for Video Anomaly Detection (Junxi Chen, Liang Li, Yunbin Tu, Li Su, Zhe Xue, Qingming Huang)
Video Anomaly Detection (VAD) aims to identify abnormal frames from discrete events within video sequences. Existing VAD methods suffer from heavy annotation burdens in fully-supervised paradigm, omission of subtle anomalies in semi-supervised paradigm, and vulnerability to noise in weakly-supervised paradigm. To address these limitations, we propose a novel paradigm: Single-Frame supervised VAD (SF-VAD), which uses a single annotated abnormal frame per abnormal video. SF-VAD ensures annotation efficiency while offering precise anomaly reference, facilitating robust anomaly modeling, and enhancing the detection of subtle anomalies in complex visual contexts. To validate its effectiveness, we construct three SF-VAD benchmarks by manually re-annotating the ShanghaiTech, UCF-Crime, and XD-Violence datasets in a practical procedure. Further, we devise Frame-guided Progressive Learning (FPL), to generalize sparse frame supervision to event-level anomaly understanding. FPL first leverages evidential learning to estimate anomaly relevance guided by annotated frames. Then it extends anomaly supervision by mining discrete abnormal events based on anomaly relevance and feature similarity. Meanwhile, FPL decouples normal patterns by isolating distinct normal frames outside abnormal events, reducing false alarms. Extensive experiments show SF-VAD achieves state-of-the-art detection results while offering a favorable trade-off between performance and annotation cost.
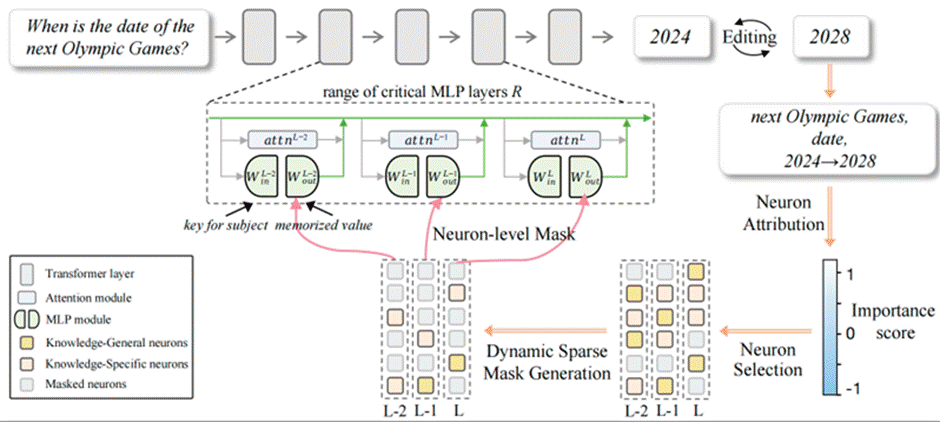
7. Edit Less, Achieve More: Dynamic Sparse Neuron Masking for Lifelong Knowledge Editing in LLMs (Jinzhe Liu, Junshu Sun, Shufan Shen, Chenxue Yang, Shuhui Wang)
The continual updating and maintenance of large language models (LLMs) has become a critical demand in artificial intelligence, such as updating “the next Olympic Games year” from 2024 to 2028. However, existing knowledge editing methods often suffer from cumulative interference in lifelong usage: external parameter approaches offer a degree of generalization but face rapidly growing storage overhead and routing conflicts as the number of edits increases, while internal parameter approaches rely on coarse layer- or block-level modifications that may inadvertently disrupt irrelevant neurons, leading to memory collapse and a decline in general capabilities. To address these challenges, we propose Neuron-Specific Masked Knowledge Editing (NMKE), which operates at the neuron level by distinguishing knowledge-general and knowledge-specific neurons through attribution analysis, and employs an entropy-guided dynamic sparse masking strategy to adaptively select the subset of neurons most relevant to the target knowledge for precise updates. This enables accurate knowledge injection while minimizing disruption to the overall model. Extensive experiments show that NMKE maintains high editing success rates and strong general capabilities across thousands of sequential edits on models such as LLaMA3-8B-Instruct. Furthermore, parameter distribution visualizations demonstrate that NMKE effectively suppresses weight drift and preserves stable internal representations, providing a precise, efficient, and scalable paradigm for lifelong knowledge editing in LLMs.
Code Link: https://github.com/LiuJinzhe-Keepgoing/NMKE
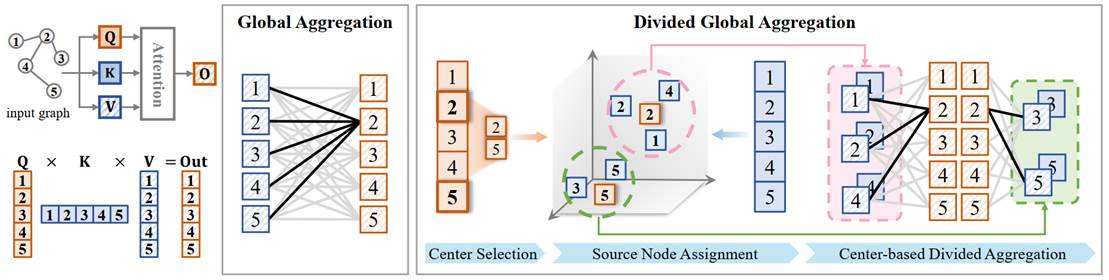
8. Relieving the Over-aggregating Effect in Graph Transformers (Junshu Sun, Wanxing Chang, Chenxue Yang, Qingming Huang, Shuhui Wang)
Graph attention has demonstrated superior performance in graph learning tasks. However, learning from global interactions can be challenging due to the large number of nodes. In this paper, we discover a new phenomenon termed over-aggregating. Over-aggregating arises when a large volume of messages is aggregated into a single node with less discrimination, leading to the dilution of the key messages and potential information loss. To address this, we propose Wideformer, a plug-and-play method for graph attention. Wideformer divides the aggregation of all nodes into parallel processes and guides the model to focus on specific subsets of these processes. The division can limit the input volume per aggregation, avoiding message dilution and reducing information loss. The guiding step sorts and weights the aggregation outputs, prioritizing the informative messages. Evaluations show that Wideformer can effectively mitigate over-aggregating. As a result, the backbone methods can focus on the informative messages, achieving superior performance compared to baseline methods. For more details, please refer to our paper https://neurips.cc/virtual/2025/poster/117062
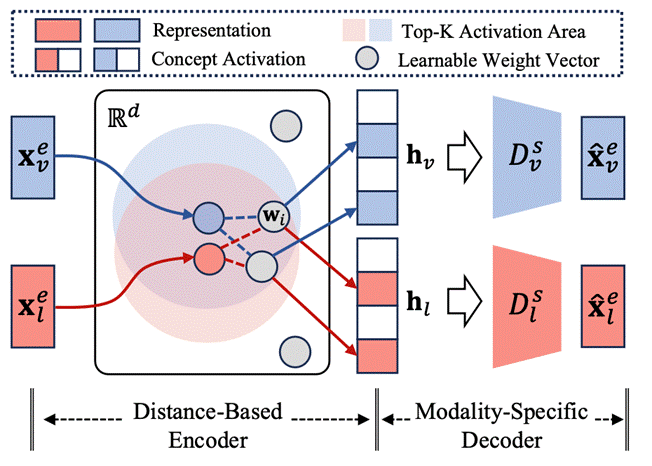
9. VL-SAE: Interpreting and Enhancing Vision-Language Alignment with a Unified Concept Set (Shufan Shen, Junshu Sun, Qingming Huang, Shuhui Wang)
To address the limited understanding of the multimodal representation alignment mechanism in current vision-language models, this paper proposes the VL-SAE, a sparse autoencoder for vision-language representations. The proposed framework decouples vision and language representations into a unified concept space through self-supervised training, enabling a systematic analysis of how these modalities align within that space. Specifically, to overcome the limitation of existing sparse autoencoders in handling multi-distribution input data, this paper propose a novel architecture by introducing a distance-based encoder and modality-specific decoders. This design enables the autoencoder to effectively disentangle cross-modal representations into a shared concept space in a self-supervised manner. The trained VL-SAE can not only interpret but also enhance the vision-language alignment in pre-trained models. First, it maps representations during model inference into the concept space, allowing for explicit observation of the semantic interpretation of both visual and textual inputs and revealing the underlying alignment mechanisms. Second, by transforming raw representations into concept-level representations, VL-SAE facilitates representation editing in the concept space to actively improve modality alignment. Experimental results demonstrate that the proposed method successfully decouples the multimodal representations of state-of-the-art vision-language models, including CLIP and LLaVA, into a shared concept space for interpretability. Furthermore, it enhances model performance on downstream tasks through alignment in concept sparse, including improving CLIP’s accuracy in zero-shot image classification and reducing hallucinations in LLaVA’s generative outputs.
Code Link: https://github.com/ssfgunner/VL-SAE
Download: