Congratulations! VIPL's 2 papers are accepted by ACL 2026(The 64nd Annual Meeting of the Association for Computational Linguistics)! ACL is a top-tier international conference on computational Linguistics and natural language processing. In this year, ACL will be take place in San Diego, California, USA from July 2nd to June 7th. The accepted papers are summarized as follows.
1. From Prediction to Intervention: Personalized Meal-Level Glucose Regulation via an LLM Agent (Mingyu Huang, Weiqing Min, Ying Jin, Yilin Wang, Shuqiang Jiang)
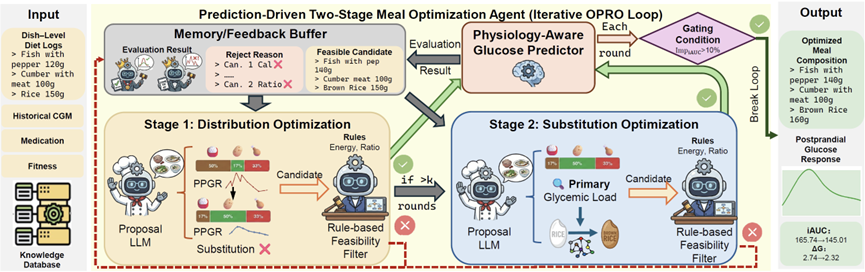
Personalized glucose regulation remains a central yet unresolved challenge in precision nutrition, as postprandial glucose response varies substantially across individuals. Existing approaches based on glycemic indices fail to adequately account for such heterogeneity and lack the mechanism to dynamically adjust meals based on personal physiological feedback. In this context, recent advances in LLM-based agents offer a promising direction, as they enable context-aware reasoning and iterative refinement. Inspired by this, we propose a physio-feedback agentic loop, a unified system that integrates individualized absorption modeling with dietary intervention to regulate glucose response. Specifically, we develop a Physiology-Aware Glucose Predictor to model individualized absorption dynamics through a learnable Temporal Physiological Absorption Decay Module. We then construct a Prediction-Driven Two-Stage Meal Optimization Agent that iteratively refines real-world meals using predicted outcomes as explicit feedback. Through extensive experiments on multiple public datasets, we demonstrate that our method not only improves prediction accuracy but also effectively reduces glucose excursions. To the best of our knowledge, this paper marks the first step in integrating physiological learning with an LLM-based agent for personalized glucose regulation.
2. INFACT: A Diagnostic Benchmark for Induced Faithfulness and Factuality Hallucinations in Video-LLMs (Junqi Yang, Yuecong Min, Jie Zhang, Shiguang Shan, Xilin Chen)
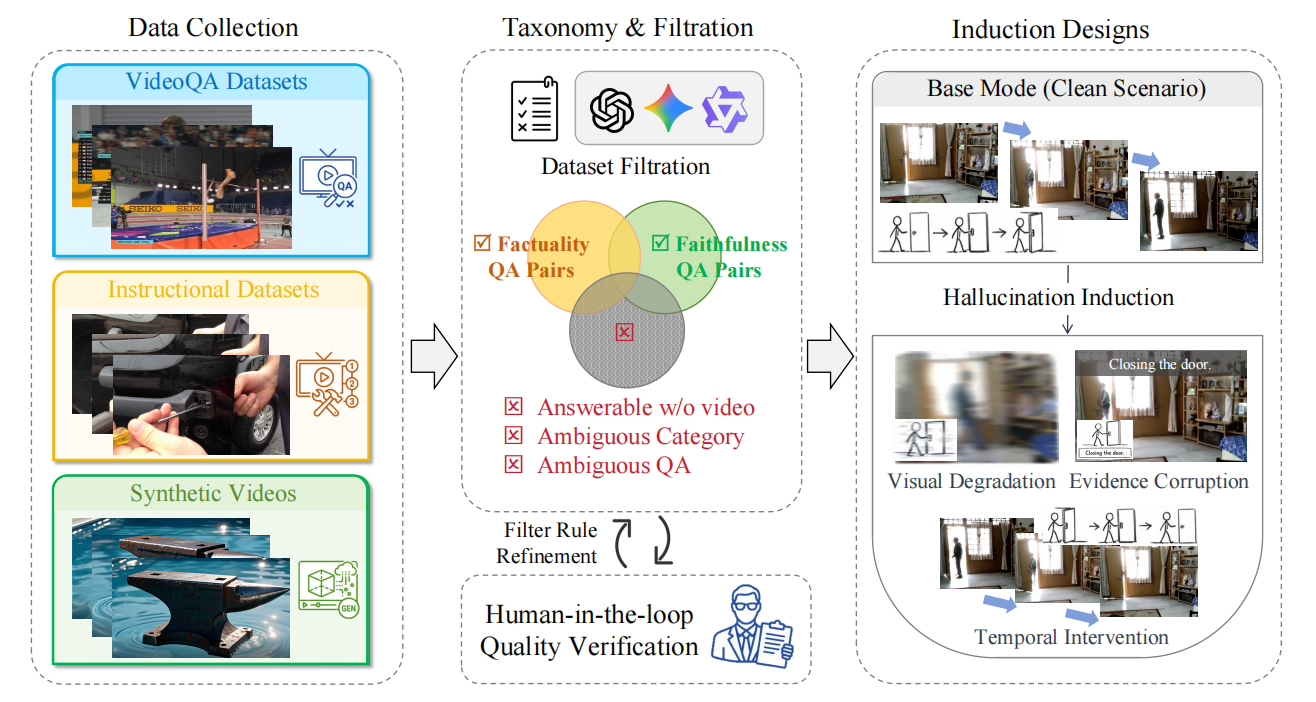
Despite rapid progress, Video Large Language Models (Video-LLMs) remain unreliable due to hallucinations, which are outputs that contradict either video evidence (faithfulness) or verifiable world knowledge (factuality). Existing benchmarks provide limited coverage of factuality hallucinations and predominantly evaluate models only in clean settings. We introduce INFACT, a diagnostic benchmark comprising 9,800 QA instances with fine-grained taxonomies for faithfulness and factuality, spanning real and synthetic videos. INFACT evaluates models in four modes: Base (clean), Visual Degradation, Evidence Corruption, and Temporal Intervention for order-sensitive items. Reliability under induced modes is quantified using Resist Rate (RR) and Temporal Sensitivity Score (TSS). Experiments on 14 representative Video-LLMs reveal that higher Base-mode accuracy does not reliably translate to higher reliability in the induced modes, with evidence corruption reducing stability and temporal intervention yielding the largest degradation. Notably, many open-source baselines exhibit near-zero TSS on factuality, indicating pronounced temporal inertia on order-sensitive questions.
Paper link: https://arxiv.org/pdf/2603.11481
Download: