Recent advancements in computer vision have significantly propelled the progress of VSR technology, resulting in impressive achievements. However, much of the current research in this field has been conducted on high-quality datasets, often overlooking practical challenges encountered in real-world scenarios, such as low resolution, large poses, poor lighting, and unclear captures. To bridge this gap, our proposed competition aims to stimulate researchers’ attention tackling these real-world scenarios by introducing two distinct tracks: Track 1 - Visual Speech Recognition under Low-Quality Conditions, and Track 2 Chinese Visual Keyword Spotting. We will provide baseline systems for both tracks, aiming to establish a common ground for benchmarking.
Through this competition, we hope to inspire the research community to push the boundaries of VSR technology, fostering the development of more robust and practical solutions that can be deployed effectively in diverse real-world environments. The results of the competition will be announced and awards presented at the FG 2025 conference. We look forward to your participation.
Challenge Tracks
Track 1:Visual Speech Recognition under Low-Quality Conditions
This track is dedicated to the development of Visual Speech Recognition (VSR) systems capable of accurately recognizing speech from visual cues (lip movements) under challenging conditions, such as low resolution, poor lighting, and extreme poses. Participants will be provided with an evaluation dataset consisting of lip movement sequences extracted from movie clips, which represent a range of real-world visual conditions. The objective is to design algorithms that can infer the spoken content solely from these visual sequences, without relying on audio input.
Track 2:Visual Keyword Spotting
This track aims to assess the performance of visual speech analysis systems in detecting whether a specific keyword is spoken by the speaker. Participants will be provided with training and validation datasets that include lip movement sequences along with corresponding text transcriptions. The test data will contain only lip movement sequences without text annotations. To ensure fairness, we will also provide a specified keyword list for the test. The final evaluation will involve testing the systems on unseen data to determine their ability to spot keywords in visual speech sequences where full recognition cannot be achieved.
Evaluation
Track 1: Visual Speech Recognition under Low-Quality Conditions
For Track1, the evaluation metric is the Character Error Rate (CER). CER is calculated by:
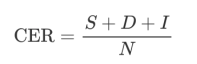
where S, D, I are the character error number of Substitutions, Deletions, Insertions, and N is the total number of characters in the reference text.
Track 2: Visual Keyword Spotting
For Track2, the evaluation metric is the Mean Average Precision (mAP), which is calculated by:
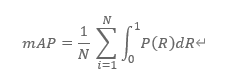
where P(R) represents the precision at a given recall value R on the Precision-Recall curve for the i-th keyword and N is the total number of keywords being evaluated.
Note: The two metrics used in this competition are objective and quantitative, with no subjective evaluation involved.
Data
Track1: Visual Speech Recognition under Low-Quality Conditions
We have provided a new dataset for valuation and test: MOV20-Val and MOV20-Test.(https://github.com/Physicsmile/MOV20)
The dataset consists of video clips sourced from publicly available platforms such as YouTube, specifically from 20 movies. Each segment is no longer than 3 minutes and covers a variety of visual and speaking conditions, including diverse lighting environments, different resolutions, and significant variations in pose, as shown in Figure 1.
Approximately one hour of evaluation data was provided, with half used as MOV20-Val for preliminary validation and the other half as MOV20-Test for the final testing. For both MOV20-Val and MOV20-Test, only lip movement sequences are provided. Additional data is allowed for training in this track.
We only release the MOV20-val at the first stage (before March 2025), and the MOV20-test will be released later for the final test in March 2025.
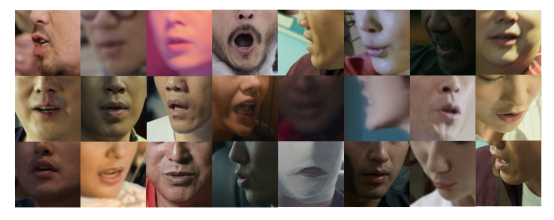
Fig.1. Samples in MOV20
Track 2: Visual Keyword Spotting
Each sample in the training and validation set is provided with corresponding lip sequences and labels that identify the spoken content. These annotations facilitate the development of accurate keyword spotting systems and allow for the quantitative assessment of model performance. In the final evaluation phase, only lip sequences of each sample will be provided, and there will be no annotations. We will also provide a fixed keyword list for evaluation. Similar to Track 1, each sample has had personal identifiers such as facial features or acoustic features removed, ensuring that only the lip area is visible.
Please note: Unlike Track 1, Track 2 prohibits the use of any external resources beyond the provided data for training, in order to ensure a fair comparison of different methods and techniques.
To access the CAS-VSR-S101 dataset, please scan the signed agreement (https://github.com/VIPL-Audio-Visual-Speech-Understanding/AVSU-VIPL/blob/master/CAS-VSR-S101-Release%20Agreement.pdf) and send it to lipreading@vipl.ict.ac.cn. Note that the agreement should be signed by a full-time staff member (usually your tutor).

Fig.2. Samples in CAS-VSR-S101
Baseline Model
Welcome each participant to use baseline models as the beginning model if you can’t find a proper one.
For the competition, we are pleased to offer participants a range of baselines and resources to facilitate their entry into the competition and to provide a benchmark for their solutions. For both tracks, we will provide baselines.
Track 1: Visual Speech Recognition under Low-Quality Conditions
We have released the baseline code on https://github.com/Physicsmile/MAVSR2025-Track1,
with its architecture shown in Fig. 3.
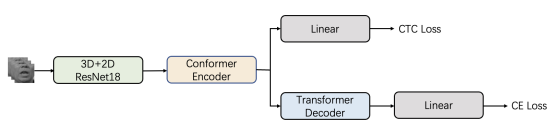
Fig.3. Baseline architecture
Track 2: Visual Keyword Spotting
We will provide a baseline system based on the commonly used sequence-to-sequence architecture, as illustrated in Figure 4.
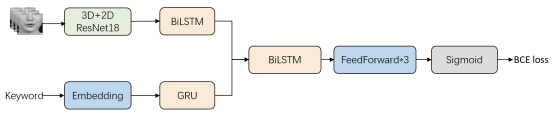
Fig.4. Baseline architecture
To help participants get started, we will offer a starting kit that includes our baseline code. This kit will be accessible via GitHub (https://github.com/Leona-Fan/MAVSR2025-Track2) and will contain the necessary libraries, pre-trained models, and example scripts to train and evaluate models on the provided datasets.
Meanwhile, we will provide comprehensive tutorial materials and documentation to ensure that participants gain a comprehensive understanding of the visual speech analysis problem space and the tools available to them. Our tutorial resources will be designed to guide participants through all stages of the competition, from understanding the data and baselines to submitting solutions.
Submission
Participants are free to perform one, or two of the tracks, but are encouraged to contribute in more than one track.
Ranking List:
Ranking on validation-set: Each team could submit their results once the validation set has been released. The ranking list will be updated before the release of the final test data.
Ranking on test-set: Each team has up to 5 submission attempts on the final test set for each sub-challenge. The results on the final test-set would be used to decide the final prize.
* The Track 1 will be ranked by the CER measure.
* The Track 2 will be ranked by the mAP measure.
Results Submission:
A participating team should submit the corresponding test results in a zip file by sending an email to lipreading@vipl.ict.ac.cn (mail to:lipreading@vipl.ict.ac.cn).
The name of the zip file containing the results should be the team-name together with the task name, such as “win_lr@task1” where ”win_lr” is the team name and “task1” is the submitted task. The test results should be submitted in the following format:
For Track 1, the result’s format should be as follows:{video_id}\t{predicted sentence}.
For Track 2,all predictions for words in each video should be submitted in the following format:
{word}\t{video_id}\t{prediction_score}
Paper submission
A paper submission and at least one upload on the test set are mandatory for the participation in the challenge.
The paper should be submitted in PDF format.
All submissions will be rigorously assessed by a double-blind peer review process.
Schedule Arrangement

All deadlines are set in Pacific Standard Time (PST) and should be submitted before 23:59 on the specified date.
Organizers
The organization of the competition is led by the team from the Institute of Computing Technology, Chinese Academy of Sciences, with the key members being Dr. Shuang Yang, Associate Researcher, Dr. Shiguang Shan, Researcher, and Dr. Xilin Chen, Researcher.
Download: