实验室近日发布目前最大规模的中文词级唇读数据集LRW-1000(链接:http://vipl.ict.ac.cn/view_database.php id=14)。该数据集总计包含1000个中文词汇,总计大约718,018个样本。据我们所知,这是目前唇语识别领域规模最大的词级公开数据集,也是唯一公开的大规模中文唇语识别数据集。该数据集中视频序列均来源于电视节目,因此包含了复杂的变化条件,包括光照、说话人姿态、语速、视频分辨率等,是分布自然而极具挑战的唇读数据集。具体来说,LRW-1000具有以下特点:

1. 关于说话人(Speakers):总计大约超过2000个不同的说话人,说话人的性别、姿态、年龄、化妆与否等均无限定,同时说话时的语速也未做严格限制,基本覆盖了自然场景下的说话情况。
2. 关于数据样本(Word Samples):总计包含大约718,018个序列片段,每个序列片段对应于一个中文词汇,平均每个样本约0.3秒。在实际应用中大量存在的短词汇也正是研究的难点所在。
3. 关于分辨率(Lip Region Resolution):该数据集取自各类电视节目,覆盖了较大的人脸分辨率范围,唇部区域分辨率从20*20到300*300不等,与实际应用情况基本相符。
注:其它详细信息请参考我们的论文:《LRW-1000: A Naturally-Distributed Large-Scale Benchmark for Lip Reading in the Wild》()
考虑到数据集的难度,为方便进行唇语识别技术的对比与测试,我们分别依照说话人的姿态、唇部区域分辨率的大小以及每个中文词汇的长短,将数据划分为了不同难度的三个等级,如下:
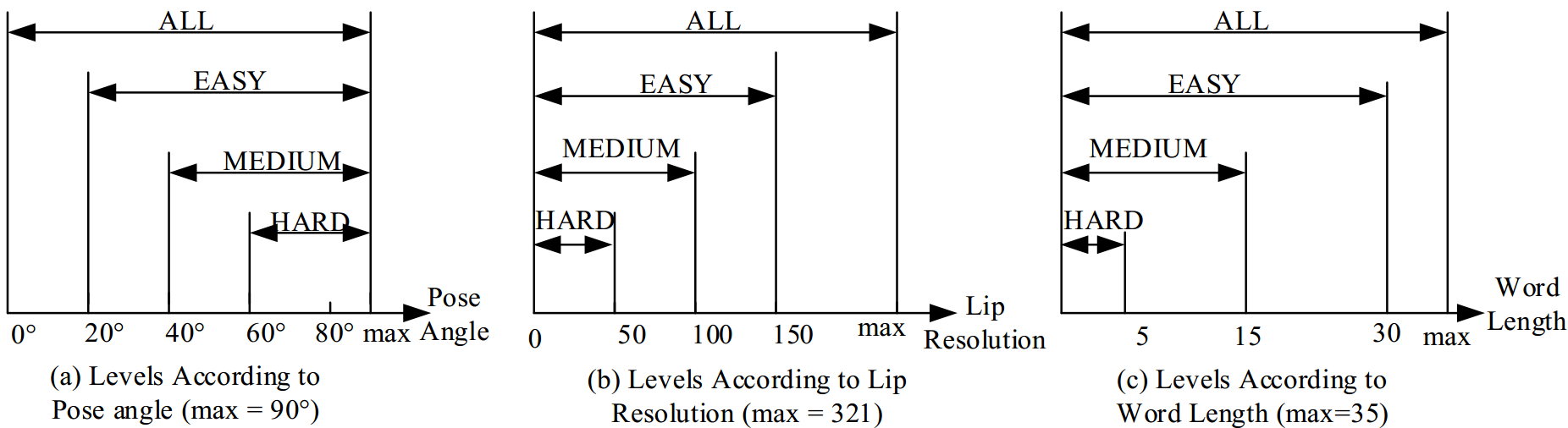
综合来说,LRW-1000是目前最大的词级唇语识别数据集,也是目前唯一公开的大规模中文唇语识别数据集,欢迎各位同行申请使用。(联系邮箱:dalu.feng@vipl.ict.ac.cn; shuang.yang@ict.ac.cn)
附件下载: