Congratulations! VIPL's 7 papers are accepted by CVPR(theIEEE / CVF Computer Vision and Pattern Recognition Conference) 2023! CVPR is a top-tier international conference on computer vision and pattern recognition. In this year, CVPR will be held in Vancouver Canada on Jun 18th through the 22nd.
The accepted papers are summarized as follows :
1. Source-free Adaptive Gaze Estimation by Uncertainty Reduction (Xin Cai, Jiabei Zeng, Shiguang Shan, Xilin Chen)
Gaze estimation across domains has been explored recently because the training data are usually collected under controlled conditions but the trained gaze estimators are used in real and different environments. However, it is challenging that we might fail to simultaneously access the annotated source data and the to-be-predicted target data due to privacy and efficiency. To this end, we formulate gaze estimation as an unsupervised source-free domain adaptation problem, which adapts a source-trained gaze estimator to unlabelled target domains without knowing the source data. To solve the problem, we propose an Uncertainty Reduction Gaze Adaptation (UnReGA) framework that accomplishes the adaptation by reducing both the sample and model uncertainty. The former is reduced by improving the images' quality and making them gaze-estimation-friendly.The latter is reduced by minimizing the variance of predictions on the same inputs. Extensive experiments demonstrate the effectiveness of UnReGA and its components. Through experiments on six cross-domain tasks, UnReGA outperforms other state-of-the-art cross-domain gaze estimation methods under both protocols with and without source data.
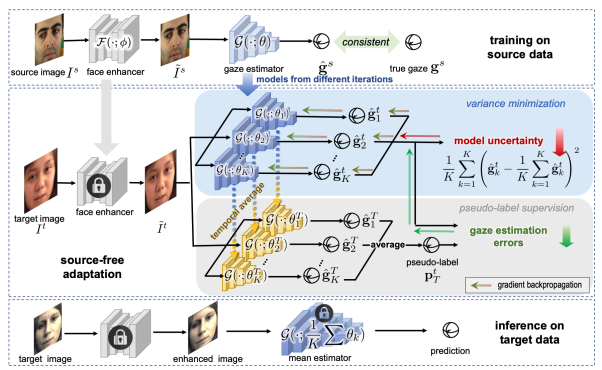
Figure 1. Framework for unsupervised source-free adaptive gaze estimation
2. DISC: Learning from Noisy Labels via Dynamic Instance-Specific Selection and Correction (Yifan Li, Hu Han, Shiguang Shan, Xilin Chen)
Existing studies show that deep neural networks are prone to fitting label noise in the training set, which leads to a decrease in model performance on the test set. Additionally, if there is label noise in the training set, the model selected using the validation set is often suboptimal and not conducive to generalization. To address the problem of label noise in the training set for computer vision classification tasks, we propose a novel noisy label learning (NLL) method: dynamic instance-specific selection and correction (DISC). DISC first uses a two-view backbone network constructed by strong and weak augmentations for image classification, obtaining confidence from two views for each image. Then, we propose a dynamic threshold strategy for each instance to select and correct reliable samples based on the confidence momentum obtained by each instance in previous training. Benefiting from this dynamic threshold strategy and dual-view learning method, we can effectively divide each instance into three subsets based on prediction consistency and divergence: clean set, hard set, and purified set. Finally, we use different regularization techniques to process subsets with different noise levels to improve the model's robustness and generalization ability. We conducted experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet, and used three types of controllable noise (sym., asym., inst.). The results show that the DISC outperforms the current best methods in most cases. Additionally, we also conducted experiments on datasets with natural label noise (Animals-10N, Food-101N, WebVision, Clothing1M), and achieved the SOTA results to date on most of the datasets.
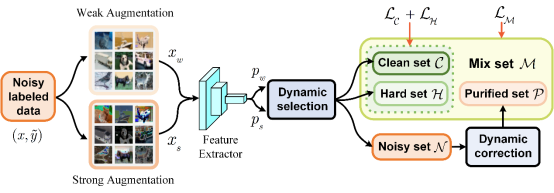
Figure 2. Dynamic label selection and correction for noisy label learning
3. KERM: Knowledge Enhanced Reasoning for Vision-and-Language Navigation (Xiangyang Li, Zihan Wang, Jiahao Yang, Yaowei Wang, Shuqiang Jiang)
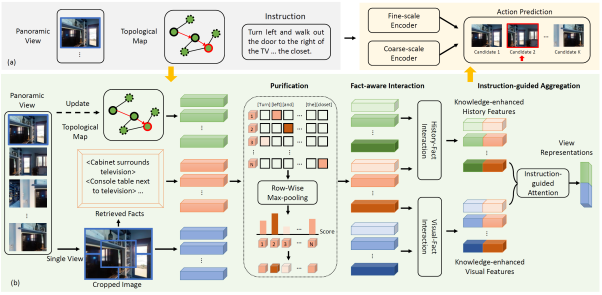
Vision-and-language navigation (VLN) is the task to enable an embodied agent to navigate to a remote location following the natural language instruction in real scenes. Most of the previous approaches utilize the entire features or object-centric features to represent navigable candidates. However, these representations are not efficient enough for an agent to navigate to the target location. As knowledge provides crucial information which is complementary to visible content, in this paper, we propose a knowledge enhanced reasoning model (KERM) to leverage knowledge to improve agent navigation ability. Specifically, we first retrieve facts for the navigation views from the constructed knowledge base. And we build a knowledge enhanced reasoning network, containing purification, fact-aware interaction, and instruction-guided aggregation modules, to integrate the visual features, history features, instruction features, and fact features for action prediction. Extensive experiments are conducted on the REVERIE, R2R, and SOON datasets. Experimental results demonstrate the effectiveness of the proposed method.
4. Layout-based Causal Inference for Object Navigation (Sixian Zhang, Xinhang Song, Weijie Li, Yubing Bai, Xinyao Yu, Shuqiang Jiang)
The object-goal navigation aims at navigating to the expected objects based on the visual information in the unseen environments. Since the object layout of unseen environments is unknown, when the goal is invisible, the agent can hardly make wise decisions. To this end, previous works attempt to construct the association (e.g. relation graph) between the visual inputs and the goal during training. Such association contains the prior knowledge of navigating in training environments, which is denoted as the experience. The experience performs a positive effect on helping the agent infer the likely location of the goal conditioned on the layout consistency assumption: the layout gap between the unseen environments and the prior knowledge is minor. However, when the layout gap is significant, the experience exerts a negative effect on navigation. Motivated by keeping the positive effect and removing the negative effect of the experience, we propose the layout-based soft Total Direct Effect (L-sTDE) framework based on the causal inference to adjust the prediction of the navigation policy. In particular, we propose to calculate the layout gap which is defined as the KL divergence between the posterior and the prior distribution of the object layout. Then the sTDE is proposed to appropriately control the effect of the experience based on the layout gap. Experimental results on AI2THOR, RoboTHOR, and Habitat demonstrate the effectiveness of our method.

5. Bi-level Meta-learning for Few-shot Domain Generalization (Xiaorong Qin, Xinhang Song, Shuqiang Jiang)
The goal of few-shot learning is to learn the generalizability from seen to unseen data with only a few samples. Most previous few-shot learning focus on learning generalizability within particular domains. However, the more practical scenarios may also require generalizability across domains. In this paper, we study the problem of Few-shot domain generalization (FSDG), which is a more challenging variant of few-shot classification. FSDG requires additional generalization with larger gap from seen domains to unseen domains. We address FSDG problem by meta-learning two levels of meta-knowledge, where the lower-level meta-knowledge are domain-specific embedding spaces as subspaces of a base space for intra-domain generalization, and the upper-level meta-knowledge is the base space and a prior subspace over domain-specific spaces for inter-domain generalization. We formulate the two levels of meta-knowledge learning problem with bilevel optimization, and further develop an optimization algorithm without higher-order partial derivatives computing to solve it. We demonstrate our method is significantly superior to the previous works by evaluating it on the widely used benchmark Meta-Dataset.

6. Data-Free Knowledge Distillation via Feature Exchange and Activation Region Constraint (Shikang Yu, Jiachen Chen, Hu Han, and Shuqiang Jiang)
Due to privacy issue with medical data and portrait data, and copyright and privateness of large data volume, sometimes only a trained teacher model is available, and the data used to train the teacher model is not available, making traditional distillation methods that rely on training data inapplicable. Therefore, the problem of "knowledge distillation without data" has been raised. The common solution to this problem is to use the synthetic data to guide the knowledge distillation from teacher to student networks. We propose channel-wise feature exchange (CFE) to enhance the diversity of the synthetic training samples: when training the generative network, features from intermediate layer are saved and stored in the feature pool. After that we randomly sample the saved features from the feature pool and perform channel-wise feature exchange. Then we obtain the synthetic training images for knowledge distillation by passing the exchanged features through the generative network. While channel-wise feature exchange enhances diversity, it also brings noise to the synthetic training images and hinders the subsequent distillation learning. Hence, we propose a multi-scale spatial activation region consistency (mSARC) to induce the student network to pay attention to the same spatial regions as the teacher network, thus suppressing the negative impact of these noise. The method achieves SOTA results on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet subsets.
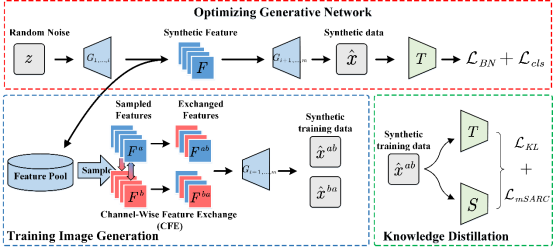
Figure 3. The framework of DFKD uisng channel-wise feature exchange and multi-scale spatial activation region consistency
7. Diversity-Measurable Anomaly Detection (Wenrui Liu, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen)
Reconstruction-based anomaly detection models achieve their purpose by suppressing the generalization ability for anomaly. However, diverse normal patterns are consequently not well reconstructed as well. Although some efforts have been made to alleviate this problem by modeling sample diversity, they suffer from shortcut learning due to undesired transmission of abnormal information. In this paper, to better handle the tradeoff problem, we propose Diversity-Measurable Anomaly Detection (DMAD) framework to enhance reconstruction diversity while avoid the undesired generalization on anomalies. To this end, we design Pyramid Deformation Module (PDM), which models diverse normals and measures the severity of anomaly by estimating multi-scale deformation fields from reconstructed reference to original input. Integrated with an information compression module, PDM essentially decouples deformation from prototypical embedding and makes the final anomaly score more reliable. Experimental results on both surveillance videos and industrial images demonstrate the effectiveness of our method. In addition, DMAD works equally well in front of contaminated data and anomaly-like normal samples.
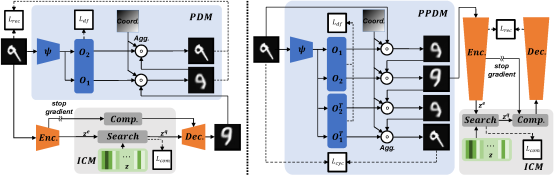
Figure 4. PDM and PPDM
Download: