Congratulations! VIPL's four papers are accepted by ICCV ( IEEE / CVF International Conference on Computer Vision) 2023! ICCV is a top-tier international conference on computer vision. This year, ICCV will be held in Paris France on Oct the 2nd through the 6th.
The accepted papers are summarized as follows:
1. DandelionNet: Domain Composition with Instance Adaptive Classification for Domain Generalization(Lanqing Hu, Meina Kan, Shiguang Shan, Xilin Chen)
Domain generalization (DG) attempts to learn a model on source domains that can well generalize to unseen but different domains. The multiple source domains are innately different in distribution but intrinsically related to each other, e.g., from the same label space. To achieve a generalizable feature, most existing methods attempt to reduce the domain discrepancy by either learning domain-invariant feature, or additionally mining domain-specific feature. In the space of these features, the multiple source domains are either tightly aligned or not aligned at all, which both cannot fully take the advantage of complementary information from multiple domains. In order to preserve more complementary information from multiple domains at the meantime of reducing their domain gap, we propose that the multiple domains should not be tightly aligned but composite together, where all domains are pulled closer but still preserve their individuality respectively. This is achieved by using instance-adaptive classifier specified for each instance’s classification, where the instance-adaptive classifier is slightly deviated from a universal classifier shared by samples from all domains. This adaptive classifier deviation allows all instances from the same category but different domains to be dispersed around the class center rather than squeezed tightly, leading to better generalization for unseen domain samples. In result, the multiple domains are harmoniously composite centered on a universal core, like a dandelion, so this work is referred to as DandelionNet. Experiments on multiple DG benchmarks demonstrate that the proposed method can learn a model with better generalization and experiments on source free domain adaption also indicate the versatility.

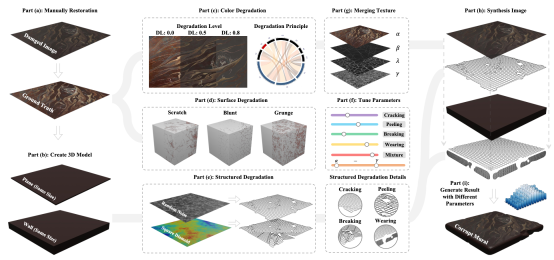
2. Building Bridge Across the Time: Disruption and Restoration of Murals In the Wild(Huiyang Shao, Qianqian Xu, Peisong Wen, Gao Peifeng, Zhiyong Yang, Qingming Huang)
As an art form of recording ancient civilization's culture, murals describe people's life scenes and society's landscape, which have great scientific, historical, and artistic significance. However, with constant exposure to the terrible environment, ancient murals are inevitably destroyed by light, winds, bacteria, and human activities. However, currently there is a lack of data sets and related algorithms for mural restoration, and the field still lacks a standard baseline. Therefore, In this paper, we focus on the mural-restoration task, which aims to detect damaged regions in the mural and repaint them automatically. Different from traditional image restoration tasks like in/out/blind-painting and image renovation, the corrupted mural suffers from more complicated degradation. However, existing mural-restoration methods and datasets still focus on simple degradation like masking. Such a significant gap prevents mural-restoration from being applied to real scenarios. To fill this gap, in this work, we propose a systematic framework to simulate the physical process for damaged murals and provide a new benchmark dataset for mural-restoration. Limited by the simplification of the data synthesis process, the previous mural-restoration methods suffer from poor performance in our proposed dataset. To handle this problem, we propose the Attention Diffusion Framework (ADF) for this challenging task. Within the framework, a damage attention map module is proposed to estimate the damage extent. Facing the diversity of defects, we propose a series of loss functions to choose repair strategies adaptively. Finally, experimental results support the effectiveness of the proposed framework in terms of both mural synthesis and restoration.
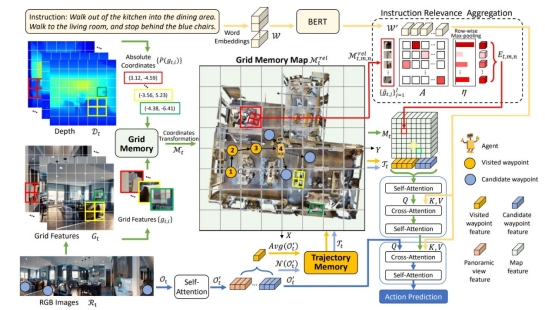
3. GridMM: Grid Memory Map for Vision-and-Language Navigation (Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, Shuqiang Jiang)
Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. To represent the previously visited environment, most approaches for VLN implement memory using recurrent states, topological maps, or top-down semantic maps. In contrast to these approaches, we build the top-down egocentric and dynamically growing Grid Memory Map (i.e., GridMM) to structure the visited environment. From a global perspective, historical observations are projected into a unified grid map in a top-down view, which can better represent the spatial relations of the environment. From a local perspective, we further propose an instruction relevance aggregation method to capture fine-grained visual clues in each grid region. Extensive experiments are conducted on both the REVERIE, R2R, SOON datasets in the discrete environments, and the R2R-CE dataset in the continuous environments, showing the superiority of our proposed method.
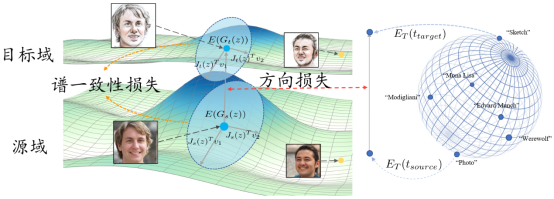
4.Text-Driven Generative Domain Adaptation with Spectral Consistency Regularization (Zhenhuan Liu, Liang Li, Jiayu Xiao, Zhengjun Zha, Qingming Huang
Combined with the generative prior of pre-trained models and the flexibility of text, text-driven generative domain adaptation can generate images from a wide range of target domains. However, current methods still suffer from overfitting and the mode collapse problem. In this paper, we analyze the mode collapse from the geometric point of view and reveal its relationship to the Hessian matrix of generator. To alleviate it, we propose the spectral consistency regularization to preserve the diversity of source domain without restricting the semantic adaptation to target domain. We also design granularity adaptive regularization to flexibly control the balance between diversity and stylization for target model. We conduct experiments for broad target domains compared with state-of-the-art methods and extensive ablation studies. The experiments demonstrate the effectiveness of our method to preserve the diversity of source domain and generate high fidelity target images.
Download: