Congratulations! VIPL's 7 papers are accepted by CVPR(IEEE/CVF Computer Vision and Pattern Recognition Conference) 2024! CVPR is a top-tier international conference on computer vision and pattern recognition. In this year, CVPR will be held in Seattle, USA on Jun 17th through the 21st.
The accepted papers are summarized as follows :
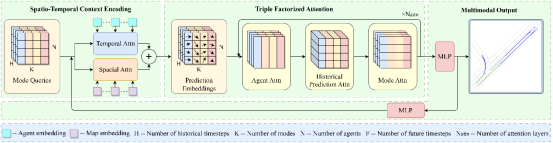
1. HPNet: Dynamic Trajectory Forecasting with Historical Prediction Attention (Xiaolong Tang, Meina Kan, Shiguang Shan, Zhilong Ji, Jinfeng Bai, Xilin Chen)
Predicting the trajectories of road agents is essential for autonomous driving systems. The recent mainstream methods follow a static paradigm, which predicts the future trajectory by using a fixed duration of historical frames. These methods make the predictions independently even at adjacent time steps, which leads to potential instability and temporal inconsistency. As successive time steps have largely overlapping historical frames, their forecasting should have intrinsic correlation, such as overlapping predicted trajectories should be consistent, or be different but share the same motion goal depending on the road situation. Motivated by this, in this work, we introduce HPNet, a novel dynamic trajectory forecasting method. Aiming for stable and accurate trajectory forecasting, our method leverages not only historical frames including maps and agent states, but also historical predictions. Specifically, we newly design a Historical Prediction Attention module to automatically encode the dynamic relationship between successive predictions. Besides, it also extends the attention range beyond the currently visible window benefitting from the use of historical predictions. The proposed Historical Prediction Attention together with the Agent Attention and Mode Attention is further formulated as a kind of triple factorized attention module, serving as the core design of HPNet. Experiments on the Argoverse motion prediction benchmark show that HPNet achieves state-of-the-art performance, and generates accurate and stable future trajectories.
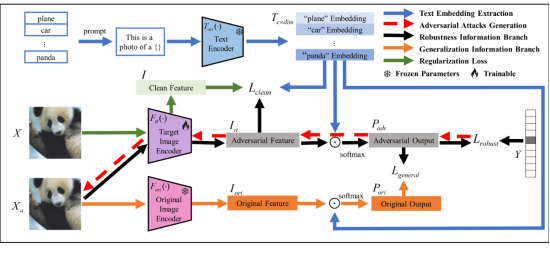
2. Pre-trained Model Guided Fine-Tuning for Zero-Shot Adversarial Robustness (SiboWang, Jie Zhang, Zheng Yuan, Shiguang Shan)
In recent years, large-scale pre-trained vision-language models like CLIP have demonstrated superior performance and significant zero-shot generalization abilities across various tasks. However, they are also susceptible to imperceptible adversarial examples. As more of these large models are deployed in security-related downstream tasks, enhancing their robustness becomes crucial. Contemporary research primarily focuses on performance enhancement, with comparatively less attention given to their robustness issues. Existing work typically adopts adversarial training (fine-tuning) as a defense against adversarial examples. However, directly applying it to the CLIP model could lead to overfitting and compromise the model's generalization capabilities. Inspired by the original pre-trained model's good generalization, we propose a Pre-trained Model Guided Adversarial Fine-Tuning (PMG-AFT) method. This method utilizes supervision from the original pre-trained model through a designed auxiliary branch to enhance the model's zero-shot adversarial robustness. Specifically, PMG-AFT minimizes the distance between the features of adversarial examples in the target model and the features in the pre-trained model, aiming to preserve the generalization features already captured by the pre-trained model. Extensive experiments conducted on 15 zero-shot datasets show that PMG-AFT significantly outperforms state-of-the-art methods, improving the average top-1 robust accuracy by 4.99% and consistently enhancing performance across the majority of datasets. Additionally, our method consistently increased the average accuracy on clean samples by 8.72%.
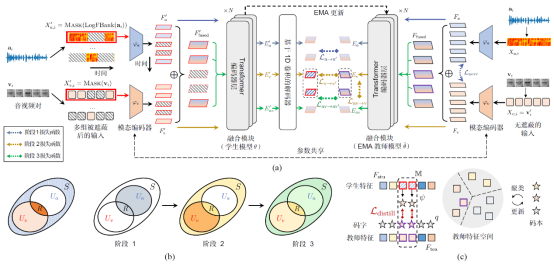
3. ES³: Evolving Self-Supervised Learning of Robust Audio-Visual Speech Representations (Yuanhang Zhang, Shuang Yang, Shiguang Shan, Xilin Chen)
Over the past few years, the task of audio-visual speech representation learning has received increasing attention due to its potential to support applications such as lip reading, audio-visual speech recognition (AVSR), and speech enhancement etc. Recent approaches for this task (e.g. AV-HuBERT) rely on guiding the learning process using the audio modality alone to capture information shared between audio and video. In this paper, we propose a novel strategy, ES³ for self-supervised learning of robust audio-visual speech representations. We reframe the problem as the acquisition of shared, unique (modality-specific) and synergistic speech information to address the inherent asymmetry between the modalities, and adopt an evolving approach to progressively build robust uni-modal and joint audio-visual speech representations. Specifically, we first leverage the more easily learnable audio modality to capture audio-unique and shared speech information. On top of this, we incorporate video-unique speech information and bootstrap the audio-visual speech representations. Finally, we maximize the total audio-visual speech information, including synergistic information. We implement ES³ as a simple Siamese framework and experiments on both English benchmarks (LRS2-BBC & LRS3-TED) and a newly contributed large-scale sentence-level Mandarin dataset, CAS-VSR-S101 show its effectiveness. In particular, on LRS2-BBC, our smallest model is on par with SoTA self-supervised models with only 1/2 parameters and 1/8 unlabeled data (223h).
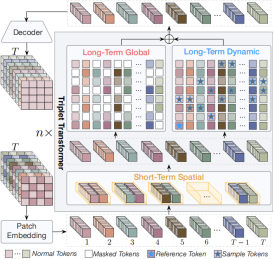
4. Video Harmonization with Triplet Spatio-Temporal Variation Patterns(Zonghui Guo, Xinyu Han, Jie Zhang, Shiguang Shan, Haiyong Zheng)
Video harmonization is an important and challenging task that aims to obtain visually realistic composite videos by automatically adjusting the foreground's appearance to harmonize with the background. Inspired by the short-term and long-term gradual adjustment process of manual harmonization, we present a Video Triplet Transformer framework to model three spatio-temporal variation patterns within videos, \ie, short-term spatial as well as long-term global and dynamic, for video-to-video tasks like video harmonization. Specifically, for short-term harmonization, we adjust foreground appearance to consist with background in spatial dimension based on the neighbor frames; for long-term harmonization, we not only explore global appearance variations to enhance temporal consistency but also alleviate motion offset constraints to align similar contextual appearances dynamically. Extensive experiments and ablation studies demonstrate the effectiveness of our method, achieving state-of-the-art performance in video harmonization, video enhancement, and video demoireing tasks. We also propose a temporal consistency metric to better evaluate the harmonized videos.
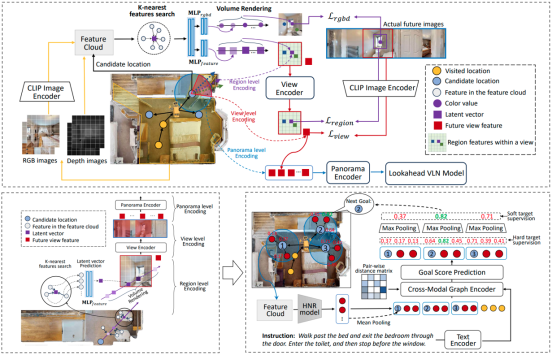
5. Lookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation (Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, Junjie Hu, Ming Jiang, Shuqiang Jiang)
Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. At each navigation step, the agent selects from possible candidate locations and then makes the move. For better navigation planning, the lookahead exploration strategy aims to effectively evaluate the agent's next action by accurately anticipating the future environment of candidate locations. To this end, some existing works predict RGB images for future environments, while this strategy suffers from image distortion and high computational cost. To address these issues, we propose the pre-trained hierarchical neural radiance representation model (HNR) to produce multi-level semantic features for future environments, which are more robust and efficient than pixel-wise RGB reconstruction. Furthermore, with the predicted future environmental representations, our lookahead VLN model is able to construct the navigable future path tree and select the optimal path branch via efficient parallel evaluation. Extensive experiments on the VLN-CE datasets confirm the effectiveness of our proposed method.
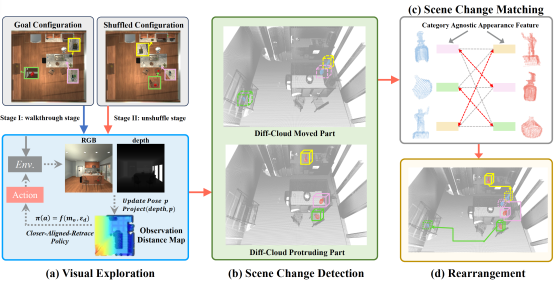
6. A Category Agnostic Model for Visual Rearrangement (Yuyi Liu, Xinhang Song, Weijie Li, Xiaohan Wang, Shuqiang Jiang)
This paper presents a novel category agnostic model for visual rearrangement task, which can help an embodied agent to physically recover the shuffled scene configuration without any category concepts to the goal configuration.Previous methods usually follow a similar architecture, completing the rearrangement task by aligning the scene changes of the goal and shuffled configuration, according to the semantic scene graphs. However, constructing scene graphs requires the inference of category labels, which not only causes the accuracy drop of the entire task but also limits the application in real world scenario. In this paper, we delve deep into the essence of visual rearrangement task and focus on the two most essential issues, scene change detection and scene change matching. We utilize the movement and the protrusion of point cloud to accurately identify the scene changes and match these changes depending on the similarity of category agnostic appearance feature. Moreover, to assist the agent to explore the environment more efficiently and comprehensively, we propose a closer-aligned-retrace exploration policy, aiming to observe more details of the scene at a closer distance. We conduct extensive experiments on AI2THOR Rearrangement Challenge based on RoomR dataset and a new multi-room multi-instance dataset MrMiR collected by us. The experimental results demonstrate the effectiveness of our proposed method.
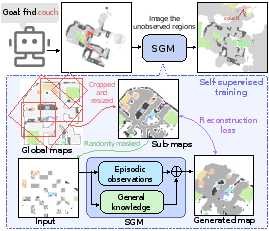
7. Imagine Before Go: Self-Supervised Generative Map for Object Goal Navigation (Sixian Zhang, Xinyao Yu, Xinhang Song, Xiaohan Wang, Shuqiang Jiang)
The Object Goal navigation (ObjectNav) task requires the agent to navigate to a specified target in an unseen environment. Since the environment layout is unknown, the agent needs to infer the unknown contextual objects from partially observations, thereby deducing the likely location of the target. Previous end-to-endRL methods learn the contextual relation with implicit representations while they lack notion of geometry. Alternatively, modular methods construct a local map for recording the observed geometric structure of unseen environment, however, lacking the reasoning of contextual relation limits the exploration efficiency. In this work, we propose the self-supervised generative map (SGM), a modular method that learns the explicit context relation via self-supervised learning. The SGM is trained to leverage both episodic observations and general knowledge to reconstruct the masked pixels of a cropped global map. During navigation, the agent maintains an incomplete local semantic map, meanwhile, the unknown regions of the local map are generated by the pre-trained SGM. Based on the scaled-up local map, the agent sets the predicted location of the target as the goal and moves towards it. Experiments on Gibson, MP3D and HM3D demonstrate the effectiveness and efficiency of our method.
Download: