Congratulations! VIPL's 12 papers are accepted by ICCV ( IEEE / CVF International Conference on Computer Vision) 2025! ICCV is is a top conference in the computer vision area. In this year, ICCV will be held in Hawaii, USA from October 19th to October 23rd.
The accepted papers are summarized as follows:
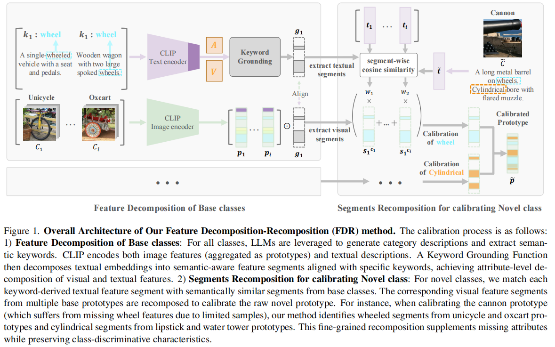
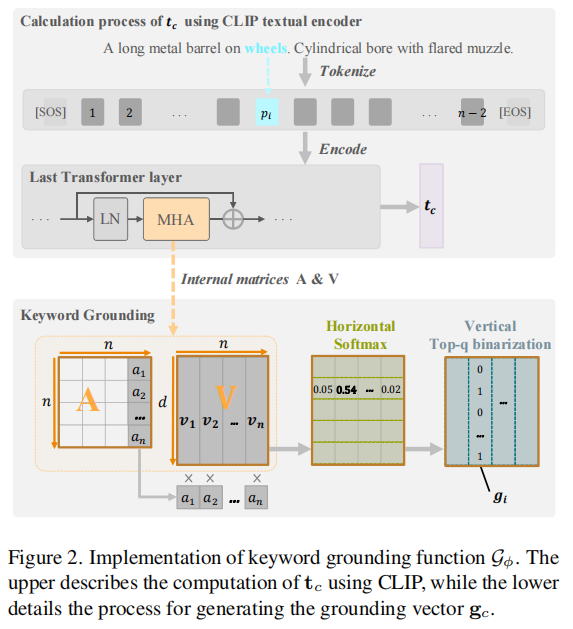
1. Feature Decomposition-Recomposition in Large Vision-Language Model for Few-Shot Class-Incremental Learning (Zongyao Xue, Meina Kan, Shiguang Shan, Xilin Chen)
Few-Shot Class-Incremental Learning (FSCIL) focuses on incrementally learning novel classes using only a limited number of samples from novel classes, which faces dual challenges: catastrophic forgetting of previously learned classes and over-fitting to novel classes with few available samples. Recent advances in large pre-trained vision-language models (VLMs), such as CLIP, provide rich feature representations that generalize well across diverse classes. Therefore, freezing the pre-trained backbone and aggregating class features as prototypes becomes an intuitive and effective way to mitigate catastrophic forgetting.However, this strategy fails to address the overfitting challenge, and the prototypes of novel classes exhibit semantic bias due to the few samples per class. To address these limitations, we propose a semantic Feature Decomposition-Recomposition (FDR) method based on VLMs. Firstly, we decompose the CLIP features into semantically distinct segments guided by text keywords from base classes. Then, these segments are adaptively recomposed at the attribute level given text descriptions, forming calibrated prototypes for novel classes. The recomposition process operates linearly at the attribute level but induces nonlinear adjustments across the entire prototype. This fine-grained and non-linear recomposition inherits the generalization capabilities of VLMs and the adaptive recomposition ability of base classes, leading to enhanced performance in FSCIL. Extensive experiments demonstrate our method's effectiveness, particularly in 1-shot scenarios where it achieves improvements between 6.70%~19.66% for novel classes over state-of-the-art baselines on CUB200.
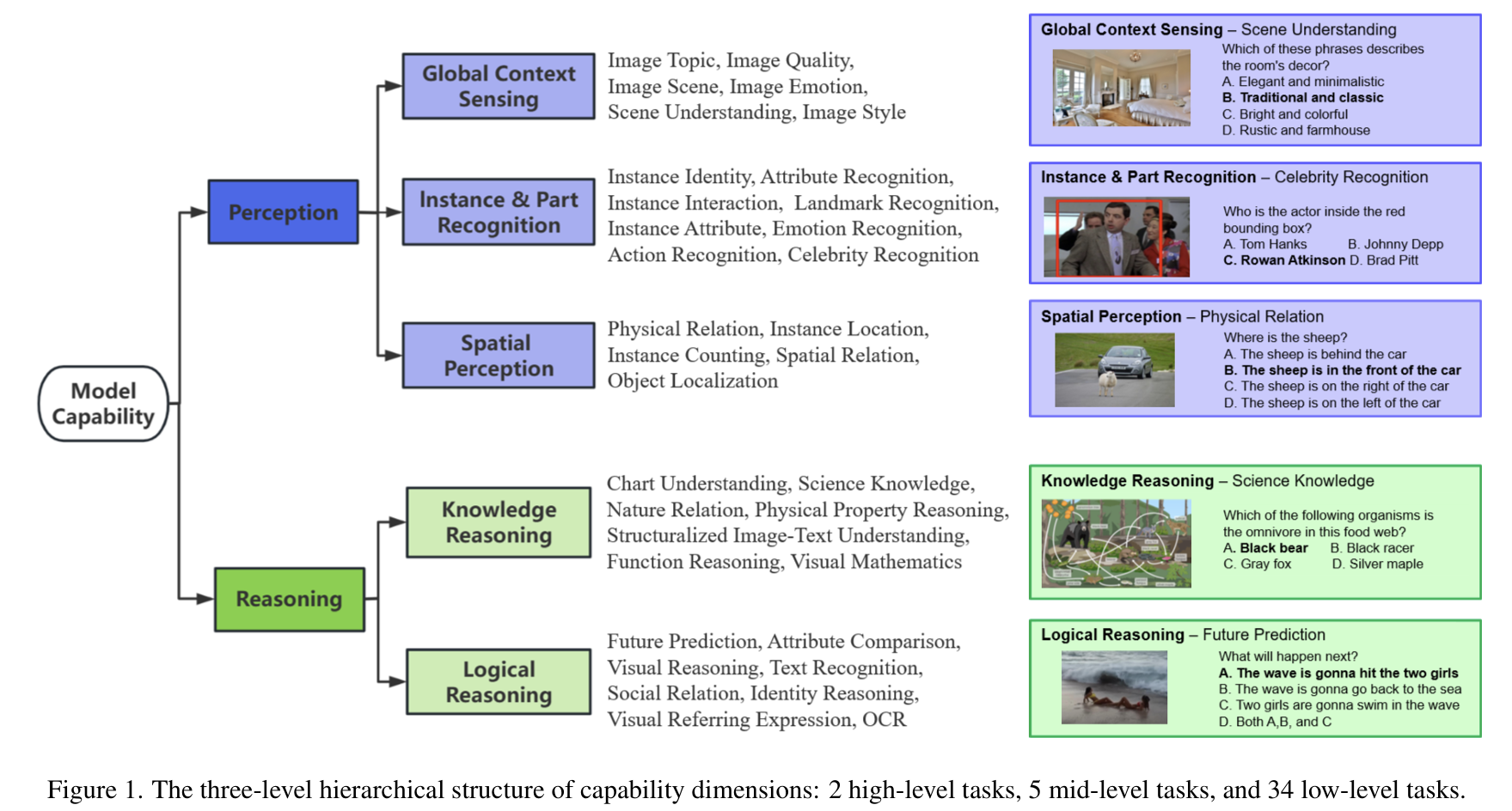
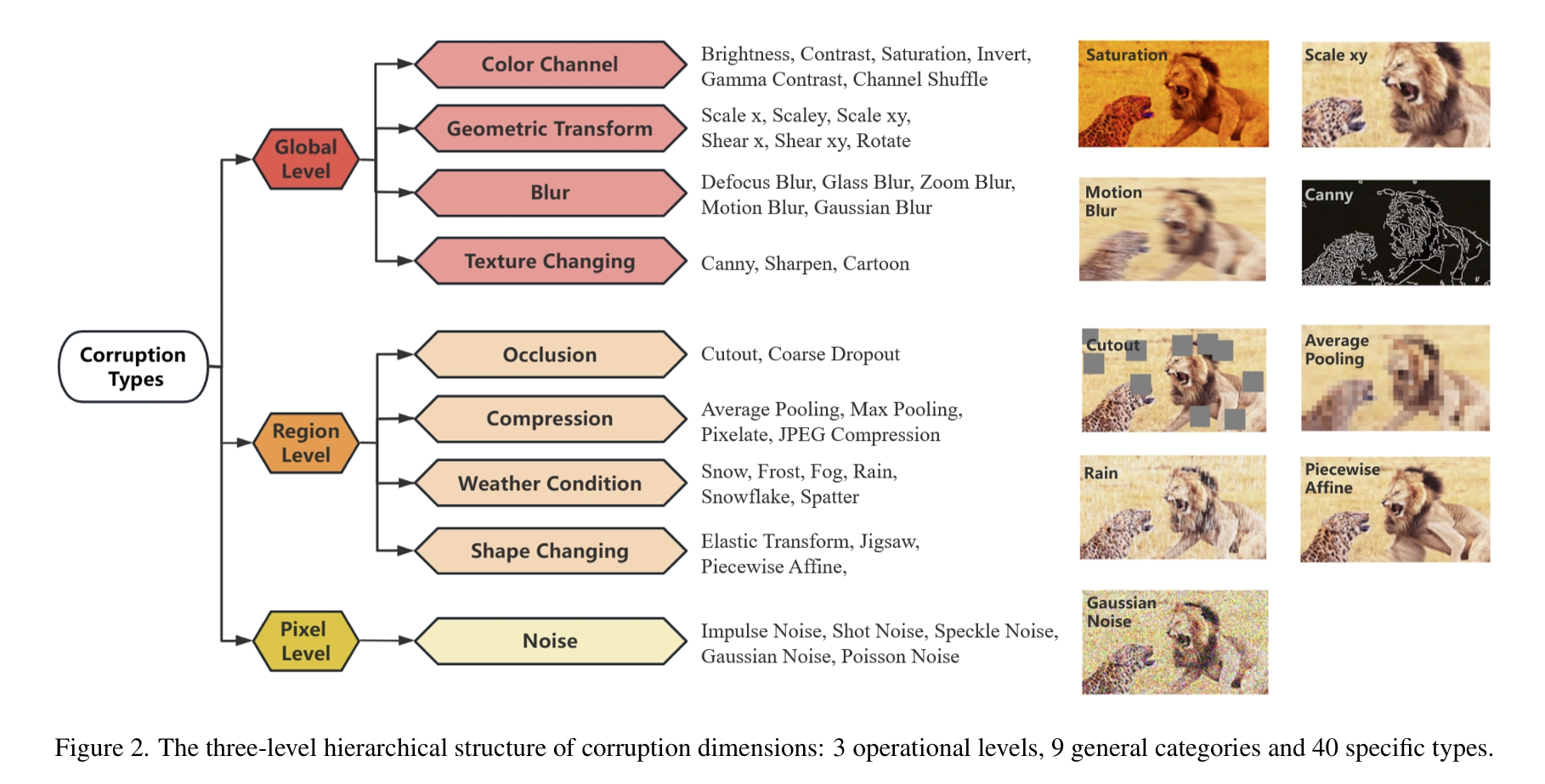
2. Benchmarking Multimodal Large Language Models Against Image Corruptions (Xinkuan Qiu, Meina Kan, Yongbin Zhou, Shiguang Shan)
Multimodal Large Language Models (MLLMs) have made significant strides in visual and language tasks. However, despite their impressive performance on standard datasets, these models encounter considerable robustness challenges when processing corrupted images, raising concerns about their reliability in safety-critical applications. To address this issue, we introduce the MLLM-IC benchmark, specifically designed to assess the performance of MLLMs under image corruption scenarios. MLLM-IC offers a more comprehensive evaluation of corruption robustness compared to existing benchmarks, enabling a multi-dimensional assessment of various MLLM capabilities across a broad range of corruption types. It includes 40 distinct corruption types and 34 low-level multimodal capabilities, each organized into a three-level hierarchical structure. Notably, it is the first corruption robustness benchmark designed to facilitate the evaluation of fine-grained MLLM capabilities. We further evaluate several prominent MLLMs and derive valuable insights into their characteristics. We believe the MLLM-IC benchmark will provide crucial insights into the robustness of MLLMs in handling corrupted images and contribute to the development of more resilient MLLMs.
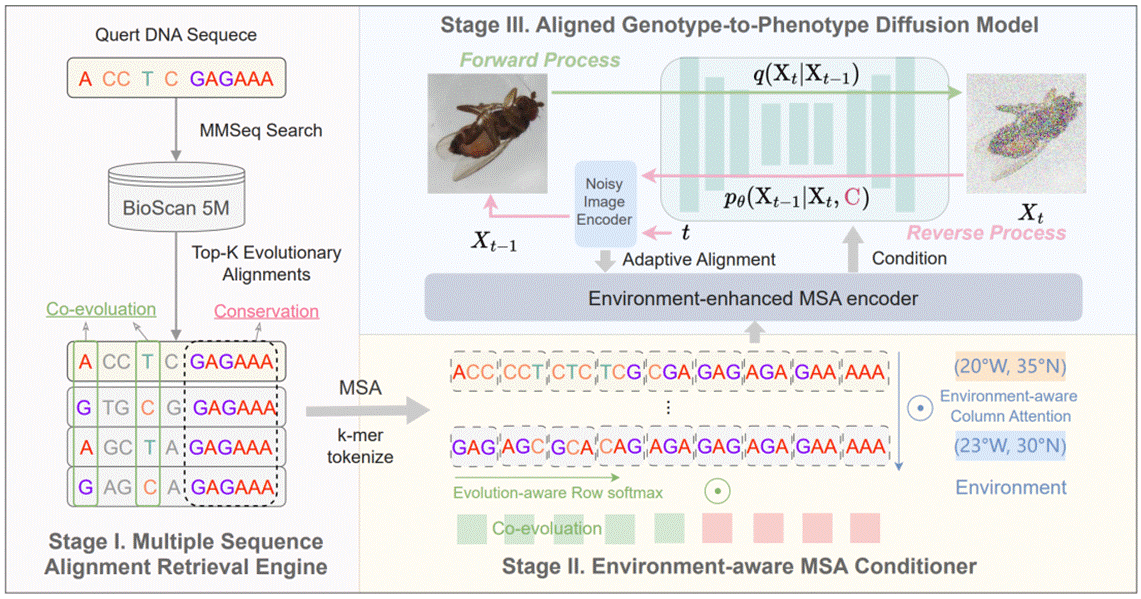
3. G2PDiffusion: Cross-species Genotype-to-Phenotype Prediction via Evolutionary Diffusion (Mengdi Liu, Zhangyang Gao, Hong Chang, Ziqing Li, Shiguang Shan, Xilin Chen)
Understanding how genes influence phenotype across species is a fundamental challenge in genetic engineering, which will facilitate advances in various fields such as crop breeding, conservation biology, and personalized medicine. However, current phenotype prediction models are limited to individual species and expensive phenotype labeling process, making the genotype-to-phenotype prediction a highly domain-dependent and data-scarce problem. To this end, we suggest taking images as morphological proxies, facilitating cross-species generalization through large-scale multimodal pretraining. We propose the first genotype-to-phenotype diffusion model (G2PDiffusion) that generates morphological images from DNA considering two critical evolutionary signals, i.e., multiple sequence alignments (MSA) and environmental contexts. The model contains three novel components: 1) a MSA retrieval engine that identifies conserved and co-evolutionary patterns; 2) an environmentaware MSA conditional encoder that effectively models complex genotype-environment interactions; and 3) an adaptive phenomic alignment module to improve genotype-phenotype consistency. Extensive experiments show that integrating evolutionary signals with environmental context enriches the model’s understanding of phenotype variability across species, thereby offering a valuable and promising exploration into advanced AI-assisted genomic analysis.
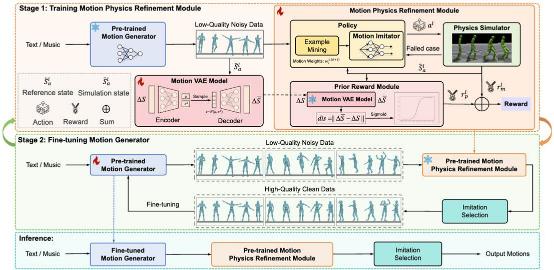
4. Morph: A Motion-free Physics Optimization Framework for Human Motion Generation ( Zhuo Li*, Mingshuang Luo*, Ruibing Hou, Xin Zhao, Hao Liu, Hong Chang, Zimo Liu, Chen Li)
Human motion generation has been widely studied due to its crucial role in areas such as digital humans and humanoid robot control. However, many current motion generation approaches disregard physics constraints, frequently resulting in physically implausible motions with pronounced artifacts such as floating and foot sliding. Meanwhile, training an effective motion physics optimizer with noisy motion data remains largely unexplored. In this paper, we propose Morph, a Motion-Free physics optimization framework, consisting of a Motion Generator and a Motion Physics Refinement module, for enhancing physical plausibility without relying on expensive real-world motion data. Specifically, the motion generator is responsible for providing large-scale synthetic, noisy motion data, while the motion physics refinement module utilizes these synthetic data to learn a motion imitator within a physics simulator, enforcing physical constraints to project the noisy motions into a physically-plausible space. Additionally, we introduce a prior reward module to enhance the stability of the physics optimization process and generate smoother and more stable motions. These physically refined motions are then used to fine-tune the motion generator, further enhancing its capability. This collaborative training paradigm enables mutual enhancement between the motion generator and the motion physics refinement module, significantly improving practicality and robustness in real-world applications. Experiments on both text-to-motion and music-to-dance generation tasks demonstrate that our framework achieves state-of-the-art motion quality while improving physical plausibility drastically.
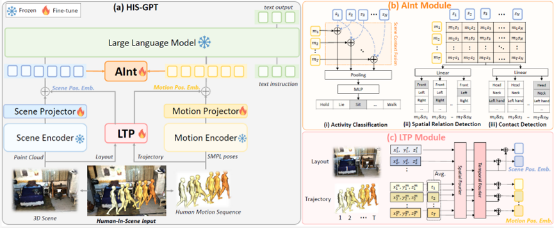
5. HIS-GPT: Towards 3D Human-In-Scene Multimodal Understanding (Jiahe Zhao, Ruibing Hou, Zejie Tian, Hong Chang, Shiguang Shan)
Existing multimodal large language models for 3D visual scenes have demonstrated powerful capabilities, but they can only comprehend scenes without human existence. To address this issue, this paper proposes a new task named Human-In-Scene understanding, aimed at achieving overall cognition of humans in 3D scenes. Firstly, we introduce a comprehensive benchmark, HIS-Bench, for this new task, covering 16 subtasks including perception, reasoning, and planning of human activities and behaviors in scenes. To construct HIS-Bench, we leverage expert models and existing 3D human datasets to develop an automated data generation pipeline. Secondly, we propose HIS-GPT, a large model for 3D human-in-scene understanding, which overcomes the limitations of existing 3D scene models in handling Human-In-Scene tasks. HIS-GPT employs pretrained encoders to separately encode scene and human motion features, while introducing an auxiliary task module to model human-scene interactions, and adopting a joint position encoding to enhance the representation of human-scene relations. Experiments demonstrate that HIS-GPT achieves significant performance improvements over existing baseline models on Human-In-Scene tasks.
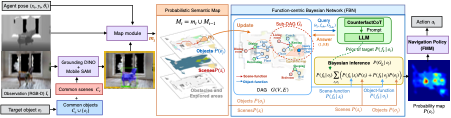
6. Function-centric Bayesian Network for Zero-Shot Object Goal Navigation (Sixian Zhang, Xinyao Yu, Xinhang Song, Yiyao Wang, Shuqiang Jiang)
Object goal navigation requires an agent to navigate to a specified target in unseen environments without an explicit map, which demands an understanding of object-scene contextual relationships to infer the target's location based on partial observations. The function of an object plays a crucial role in its categorization and naming. Analyzing an object's functional role within a given scene enhances the understanding of its contextual relationships, thereby aiding in goal inference. In this paper, we propose the Function-centric Bayesian Network (FBN) for the zero-shot ObjectNav task. FBN is designed to uncover the functions that observed objects afford individually or collaboratively with other objects, as well as the functional semantics contained within the observed scenes. The probabilistic directed edges in FBN describe the object-function and scene-function relationships, which are derived by prompting LLMs with the proposed CounterfactCoT. CounterfactCoT determines existence and probability of edges, by guiding LLMs to compare the impact of an edge’s existence or absence on the surrounding context. Leveraging FBN with Bayesian inference, the probability of each function group and probability map of goal occurrence are computed. Then the waypoint is selected based on obtained probability map. Experiments on MP3D and HM3D demonstrate that FBN effectively captures object-scene-function relationships and improves zero-shot ObjectNav performance.
7. CogCM: Cognition-Inspired Contextual Modeling for Audio Visual Speech Enhancement (Feixiang Wang, Shuang Yang, Shiguang Shan, Xilin Chen)
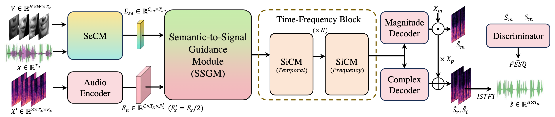
Audio-Visual Speech Enhancement (AVSE) leverages both audio and visual information to improve speech quality. Despite noisy real-world conditions, humans are generally able to perceive and interpret corrupted speech segments as clear. Researches in cognitive science have shown how the brain merges auditory and visual inputs to achieve this. These studies uncover four key insights for AVSE, reflecting a hierarchical synergy of semantic and signal processes with visual cues enriching both levels: (1) Humans utilize high-level semantic context to reconstruct corrupted speech signals. (2) Visual cues are shown to strongly correlate with semantic information, enabling visual cues to facilitate semantic context modeling. (3) Visual appearance and vocal information jointly benefit identification, implying that visual cues strengthen low-level signal context modeling. (4) High-level semantic knowledge and low-level auditory processing operate concurrently, allowing the semantics to guide signal-level context modeling. Motivated by these insights, we propose CogCM, a cognition-inspired hierarchical contextual modeling framework. The CogCM framework includes three core modules: (1) A semantic context modeling module (SeCM) to capture high-level semantic context from both audio and visual modalities; (2) A signal context modeling module (SiCM) to model fine-grained temporal-spectral structures under multi-modal semantic context guidance; (3) A semantic-to-signal guidance module (SSGM) to leverage semantic context in guiding signal context modeling across both temporal and frequency dimensions. Extensive experiments on 7 benchmarks demonstrate CogCM's superiority, especially achieving 63.6\% SDR and 58.1\% PESQ improvements at -15dB SNR -- outperforming state-of-the-art methods across all metrics.
8. Not Only Vision: Evolve Visual Speech Recognition via Peripheral Information (Zhaoxin Yuan, Shuang Yang, Shiguang Shan, Xilin Chen)
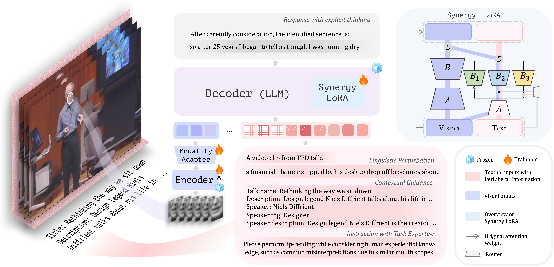
Is visual information alone sufficient for visual speech recognition (VSR) in challenging real-world scenarios? Humans do not rely solely on visual information for lip-reading but also incorporate additional cues, such as speech-related context and prior knowledge about the task. However, existing methods have largely overlooked such external information in automatic VSR systems. To systematically explore the role of such information in VSR, we introduce the concept of Peripheral Information. We categorize it into three types based on the relevance to the spoken content: (1) Contextual Guidance (e.g., topic or description of speech), (2) Task Expertise (e.g., human prior experience in lip-reading), and (3) Linguistic Perturbation (irrelevant signals processed alongside meaningful information). Considering the disparity that peripheral information provides additional clues with varying significance while visual input serves as the most direct source for VSR, we propose a framework that introduces a hierarchical processing strategy to handle different modalities. With visual-specific adaptation and a dynamic routing mechanism for multi-modal information, our approach reduces the impact of modality conflicts effectively and enables selective utilization of peripheral information with varying relevance.. Leveraging readily available peripheral information, our model achieves a WER of 22.03% on LRS3, surpassing previous approaches. Further experiments on AVSpeech demonstrate its generalization in real-world scenarios.
9. Trial-Oriented Visual Rearrangement (Yuyi Liu, Xinhang Song, Tianliang Qi, Shuqiang Jiang)
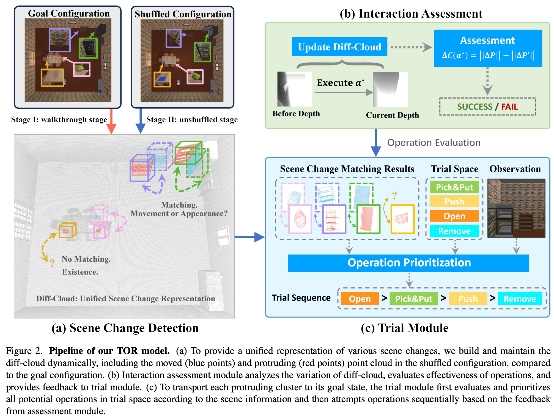
Visual rearrangement task requires the embodied agent to first explore and memorize the goal state of the environment, and then restore the environment to its original memorized state through navigation and interaction after the environment state is disrupted. The existing methods have achieved good performance in handling object displacement changes by constructing independent explicit scene graph structures. However, it is difficult to unify the processing of object appearance and existence changes. The main reason is that the discrimination space for movement, appearance, and existence changes is highly heterogeneous. If the three types of changes are unified for inference, it will greatly increase the complexity of the inference space and significantly reduce the confidence of decision-making. If decoupling is used for processing, it is necessary to model each change separately, resulting in a decrease in the reuse rate of each module. Therefore, this paper proposes a Trial-Oriented Visual Rearrangement (TOR) framework driven by embodied trial and error, which utilizes principles of strong embodiment to prune the joint inference space and find smaller shared spaces to handle various changes. TOR captures environmental changes by maintaining differential point cloud representations and restores the scene to the goal state through the alternating operation of trial module and interaction assessment module. The experimental results indicate that TOR has achieved significant results in restoring object movement and appearance changes, and demonstrates good generalization ability in complex multi room environments.
10. Learning on the Go: A Meta-learning Object Navigation Model (Xiaorong Qin, Xinhang Song, Sixian Zhang, Xinyao Yu, Xinmiao Zhang, Shuqiang Jiang)
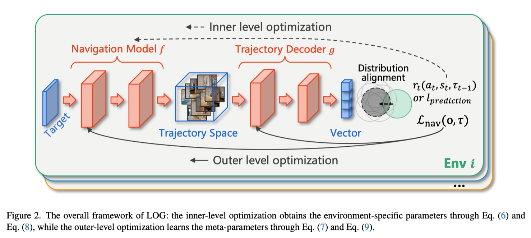
The object navigation task requires an agent to locate a target object in unknown environments using only visual observations. However, most existing methods employ fixed models during the testing phase, lacking adaptability to dynamic environmental changes, which limits their navigation capabilities in novel environments. To address this issue, this paper proposes a meta-learning mechanism that targets object-conditioned trajectory distribution shifts, enabling the model to effectively improve generalization across diverse environments by learning a central conditional distribution as a prior. Specifically, the approach learns common patterns of target-conditioned trajectories across different environments and aligns environment-specific distributions with the central distribution during adaptation, significantly reducing the search space and facilitating rapid updates with limited data. The proposed Learning on the Go (LOG) framework can be seamlessly integrated with traditional navigation methods, allowing agents to achieve flexible, real-time learning during navigation. Theoretical analysis demonstrates that learning a central distribution yields a tighter generalization bound, while experimental results on multiple datasets validate that the proposed method outperforms existing state-of-the-art approaches, exhibiting strong adaptability to cross-environment and cross-simulator navigation tasks.
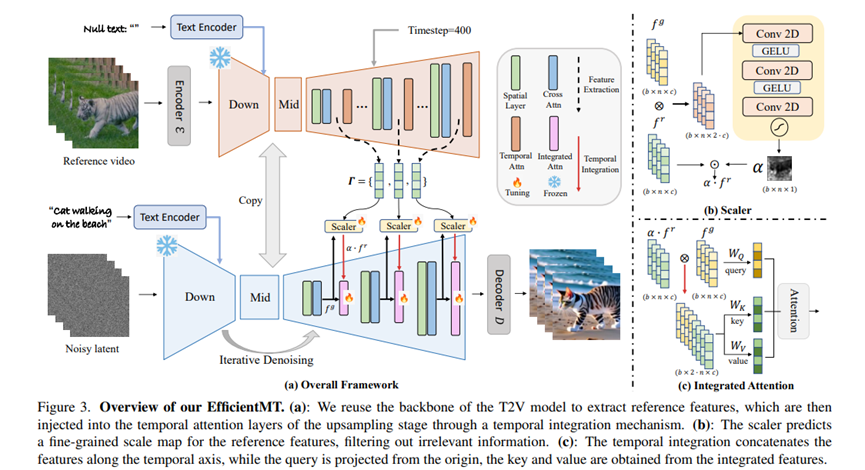
11. EfficientMT: Efficient Temporal Adaptation for Motion Transfer in Text-to-Video Diffusion Models(Yufei Cai, Hu Han, Yuxiang Wei, Shiguang Shan, Xilin Chen)
Visual content generation has made rapid progress in recent years, and video motion transfer is an important task in visual content generation. Existing video motion transfer methods rely on optimization strategies for individual samples or dense visual conditions (e.g., depth, Canny edge detection) to transfer motion patterns, which results in high computational complexity and difficulty in flexible motion transfer and editing. This paper proposes a novel and efficient end-to-end video motion transfer method, EfficientMT, which utilizes a small number of synthesized paired motion transfer samples (about 150) to adapt a pre-trained T2V backbone model, forming a general motion transfer framework. We reuse the backbone network of the base model as a reference feature extractor to bridge the gap between feature spaces, and introduce a Temporal Integration Mechanism (TIM) to seamlessly inject reference features into the generation process. To decouple and refine the motion-related information in the reference features, we introduce a scale predictor, Scaler, to generate a fine-grained weight map (scale map) for the reference features, adaptively filtering out irrelevant features. Extensive experiments show that compared to existing video motion transfer methods, EfficientMT can achieve efficient and fast inference without additional fine-tuning, while maintaining excellent editing flexibility and stability.
12. OV3D-CG: Open-vocabulary 3D Instance Segmentation with Contextual Guidance (Mingquan Zhou, Chen He, Ruiping Wang, Xilin Chen)
Open-vocabulary 3D instance segmentation (OV-3DIS), which aims to segment and classify objects beyond predefined categories, is a critical capability for embodied AI applications. Existing methods rely on pre-trained 2D foundation models, focusing on instance-level features while overlooking contextual relationships, limiting their ability to generalize to rare or ambiguous objects. To address these limitations, we propose an OV-3DIS framework guided by contextual information. First, we employ a Class-agnostic Proposal Module, integrating a pre-trained 3D segmentation model with a SAM-guided segmenter to extract robust 3D instance masks. Subsequently, we design a Semantic Reasoning Module, which selects the best viewpoint for each instance and constructs three 2D context-aware representations. The representations are processed using Multimodal Large Language Models with Chain-of-Thought prompting to enhance semantic inference. Notably, our method outperforms state-of-the-art methods on the ScanNet200 and Replica datasets, demonstrating superior open-vocabulary segmentation capabilities. Moreover, preliminary implementation in real-world scenarios verifies our method's robustness and accuracy, highlighting its potential for embodied AI tasks such as object-driven navigation.
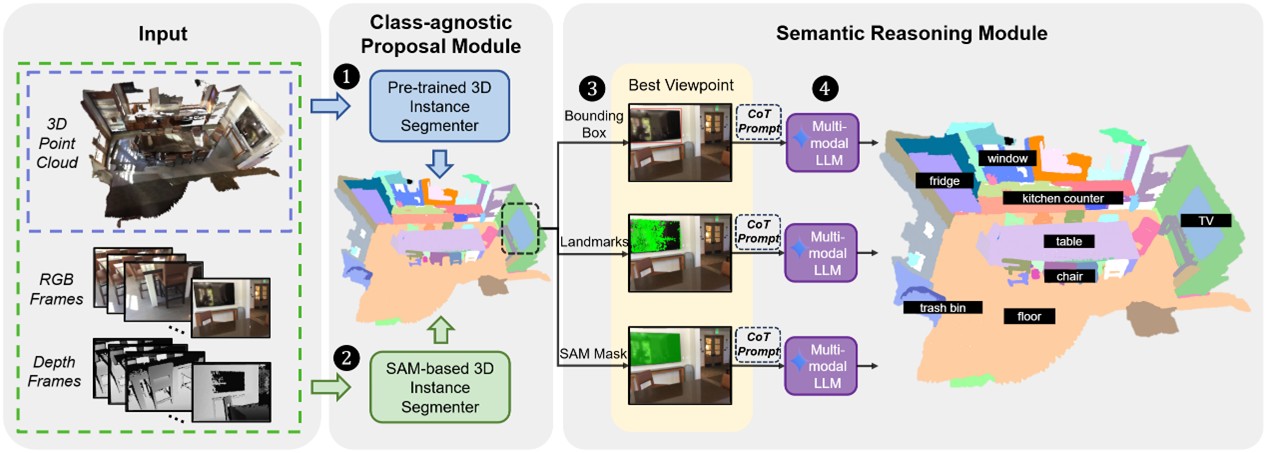
Overview of OV3D-CG
Download: