Congratulations! VIPL's 2 paper are accepted by ACM MM (ACM International Conference on Multimedia) 2025! ACM MM is a top conference on multimedia. This year, ACM MM will be held in Ottawa Canada from October 27th to October 31st.
The accepted papers are summarized as follows:
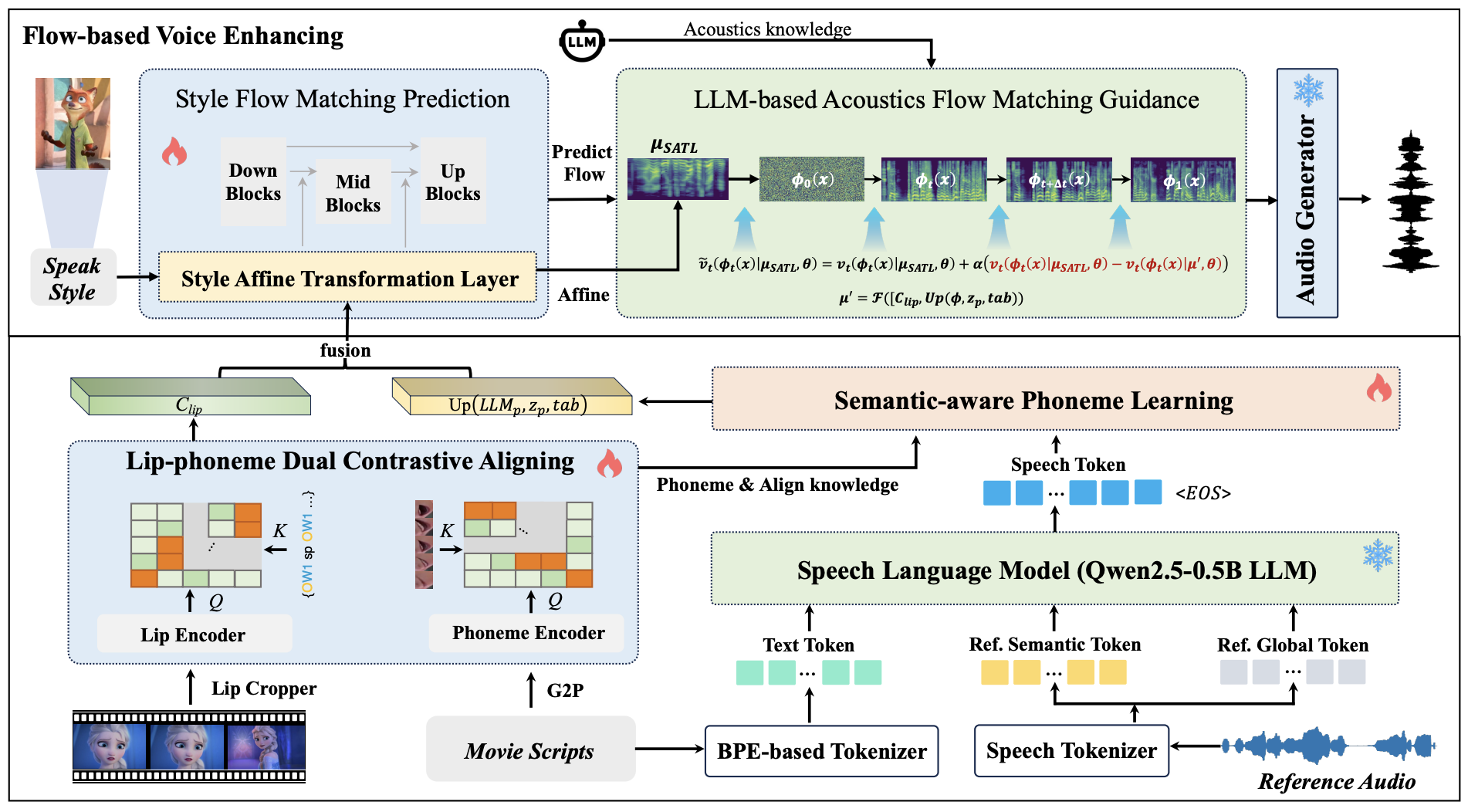
1. FlowDubber: Movie Dubbing with LLM-based Semantic-aware Learning and Flow Matching based Voice Enhancing (Gaoxiang Cong, Liang Li, Jiadong Pan, Zhedong Zhang, Amin Beheshti, Anton Van Den Hengel, Yuankai Qi, Qingming Huang)
Movie Dubbing aims to convert scripts into speeches that align with the given movie clip in both temporal and emotional aspects while preserving the vocal timbre of one brief reference audio. Existing methods focus primarily on reducing the word error rate while ignoring the importance of lip-sync and acoustic quality. To address these issues, we propose a large language model (LLM) based flow matching architecture for dubbing, named FlowDubber, which guarantees high-quality audio-visual sync and pronunciation by incorporating a large speech language model and dual contrastive aligning while achieving better acoustic quality via the proposed voice-enhanced flow matching than previous works. First, we introduce Qwen2.5 as the backbone of LLM to learn the in-context sequence from movie scripts and reference audio. Then, the proposed semantic-aware learning focuses on capturing LLM semantic knowledge at the phoneme level. Next, dual contrastive aligning (DCA) ensures mutual alignment with lip movement, reducing ambiguities where similar phonemes might be confused. Finally, the proposed Flow-based Voice Enhancing (FVE) improves acoustic quality in two aspects, which introduces an LLM-based acoustics flow matching guidance to strengthen clarity and uses affine style prior to enhance identity when recovering noise into mel-spectrograms via gradient vector field prediction. Extensive experiments demonstrate that our method outperforms several state-of-the-art methods on two primary benchmarks.
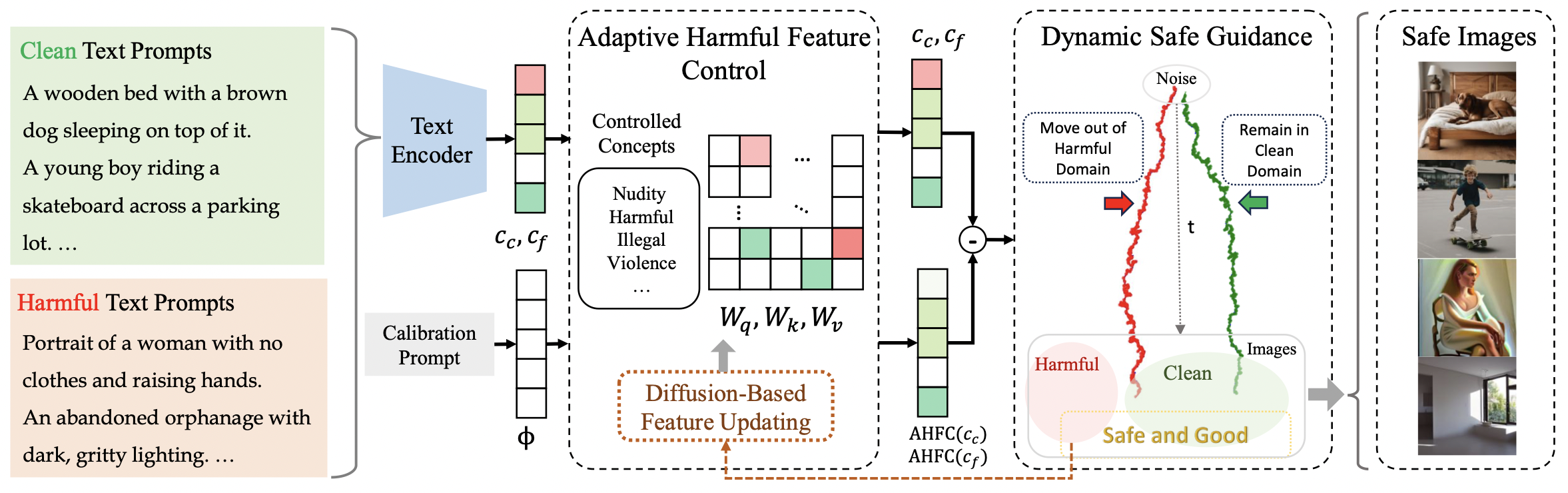
2. SafeCFG: Controlling Harmful Features with Dynamic Safe Guidance for Safe Generation (Jiadong Pan, Liang Li, Hongcheng Gao, Zhengjun Zha, Qingming Huang, Jiebo Luo)
Diffusion models have shown outstanding performance in text-to-image tasks and are therefore widely adopted. With the introduction of classifier-free guidance (CFG), the quality of images generated by diffusion models has been significantly improved. However, CFG can also be misused to generate more harmful images by maliciously guiding the image generation process. Existing safe alignment methods aim to reduce the risk of generating harmful content but often compromise the quality of clean image generation. To address this issue, we propose SafeCFG, which adaptively controls harmful features through dynamic safe guidancein the classifier-free guidance process. This method dynamically adjusts the CFG generation process based on the harmfulness of the input prompt, introducing significant deviations only when the generation is harmful, thereby enabling high-quality and safe image generation. SafeCFG can simultaneously modulate various types of harmful CFG generation processes, effectively removing harmful content while preserving high image quality. In addition, SafeCFG is capable of detecting image harmfulness, enabling unsupervised safe alignment of diffusion models without requiring predefined clean or harmful labels. Experimental results demonstrate that images generated by SafeCFG achieve both high quality and safety, and that diffusion models trained using our unsupervised approach also exhibit strong safety performance.
Download: