Congratulations! VIPL's four papers are accepted by ICLR 2026 on Jan. 25th, 2026! ICLR is a top international conference on machine learning. In this year, ICLR will be held in Rio de Janeiro, Brazil from April 23rd to 27th.
The accepted papers are summarized as follows :
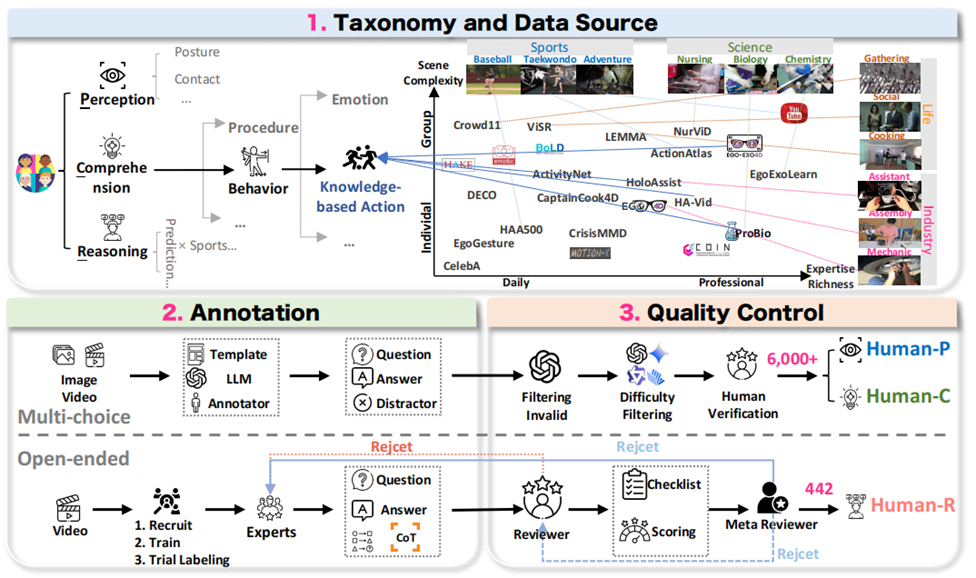
1. HumanPCR: Probing MLLM Capabilities in Diverse Human-Centric Scenes(Keliang Li, Hongze Shen, Hao Shi, Ruibing Hou, Hong Chang, Jie Huang, Chenghao Jia, Wen Wang, Yiling Wu, Dongmei Jiang, Shiguang Shan, Xilin Chen)
The aspiration for artificial general intelligence demands that Multimodal Large Language Models (MLLMs) possess a deep understanding of human behavior in diverse and complex scenarios. To rigorously evaluate this capability, we propose HumanPCR, a comprehensive evaluation suite structured along a hierarchical taxonomy: Perception, Comprehension, and Reasoning. Perception and Comprehension comprise over 6,000 questions spanning fine-grained tasks such as pose and gaze estimation, while the Reasoning level (Human-R) introduces a carefully curated and challenging multi-evidence video reasoning test. Unlike existing benchmarks that often rely on “referred visual evidence” explicitly indicated in the question, Human-R requires models to integrate discrete visual cues and, more importantly, to proactively seek proactive visual evidence—implicit visual context that is crucial for reasoning yet absent from the textual prompt. Extensive evaluations across 30+ state-of-the-art models show that current MLLMs perform poorly on human-related tasks involving fundamental abilities such as spatial perception and theory-of-mind reasoning, and they face substantial difficulty in proactively collecting the necessary visual evidence for inference. Encouragingly, reasoning-enhanced models such as o3 demonstrate the potential to reduce errors arising from missed proactive evidence, pointing to a promising direction for future human-centric visual understanding.
2. Revisiting Multimodal Positional Encoding in Vision-Language Models
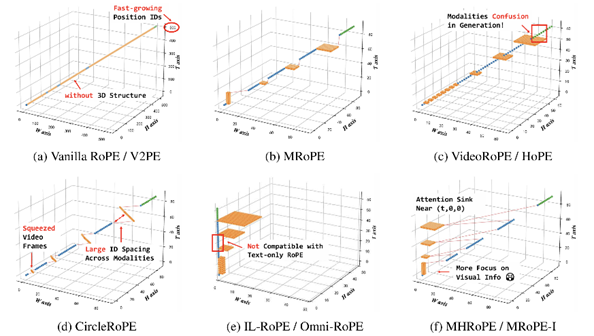
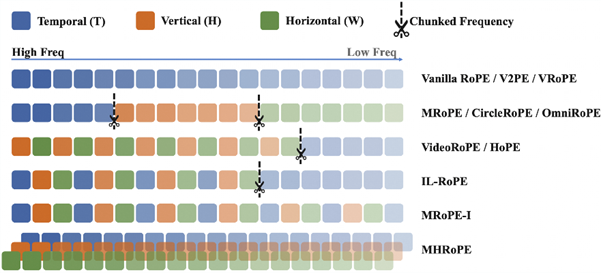
(Jie Huang, Xuejing Liu, Sibo Song, Ruibing Hou, Hong Chang, Junyang Lin, Shuai Bai)Multimodal position encoding is essential for vision-language models, yet there has been little systematic investigation into it. We conduct a comprehensive analysis of multimodal Rotary Positional Embedding (RoPE) by examining its two core components: position design and frequency allocation. Through extensive experiments, we identify three key guidelines: positional coherence, full frequency utilization, and preservation of textual priors—ensuring unambiguous layout, rich representation, and faithful transfer from the pre-trained LLM. Based on these insights, we propose Multi-Head RoPE (MHRoPE) and MRoPE-Interleave (MRoPE-I), two simple and plug-and-play variants that require no architectural changes. Our methods consistently outperform existing approaches across diverse benchmarks, with significant improvements in both general and fine-grained multimodal understanding.
For more details, please refer to our paper https://arxiv.org/abs/2510.23095.
Code is avaliable at https://github.com/JJJYmmm/Multimodal-RoPEs.
3. Plan-R1: Safe and Feasible Trajectory Planning as Language Modeling (Xiaolong Tang, Meina Kan, Shiguang Shan, Xilin Chen)
Safe and feasible trajectory planning is critical for real-world autonomous driving systems.However, existing learning-based planners rely heavily on expert demonstrations, which not only lack explicit safety awareness but also risk inheriting undesirable behaviors such as speeding from suboptimal human driving data. Inspired by the success of large language models, we propose Plan-R1, a two-stage trajectory planning framework that decouples principle alignment from behavior learning. In the first stage, a general trajectory predictor is pre-trained on expert data to capture diverse, human-like driving behaviors. In the second stage, the model is fine-tuned with rule-based rewards using Group Relative Policy Optimization (GRPO), explicitly aligning ego planning with principles such as safety, comfort, and traffic rule compliance. This two-stage paradigm retains human-like behaviors while enhancing safety awareness and discarding undesirable patterns from demonstrations. Furthermore, we identify a key limitation of directly applying GRPO to planning: group-wise normalization erases cross-group scale differences, causing rare, high-variance safety-violation groups to have similar advantages as abundant low-variance safe groups, thereby suppressing optimization for safety-critical objectives. To address this, we propose Variance-Decoupled GRPO (VD-GRPO), which replaces normalization with centering and fixed scaling to preserve absolute reward magnitudes, ensuring that safety-critical objectives remain dominant throughout training. Experiments on the nuPlan benchmark demonstrate that Plan-R1 significantly improves planning safety and feasibility, achieving state-of-the-art performance, particularly in realistic reactive settings.
Code is available at https://github.com/XiaolongTang23/Plan-R1.

4. Adaptive Nonlinear Compression for Large Foundation Models (Liang Xu, Shufan Shen, Qingming Huang, Yao Zhu, Xiangyang Ji, Shuhui Wang)
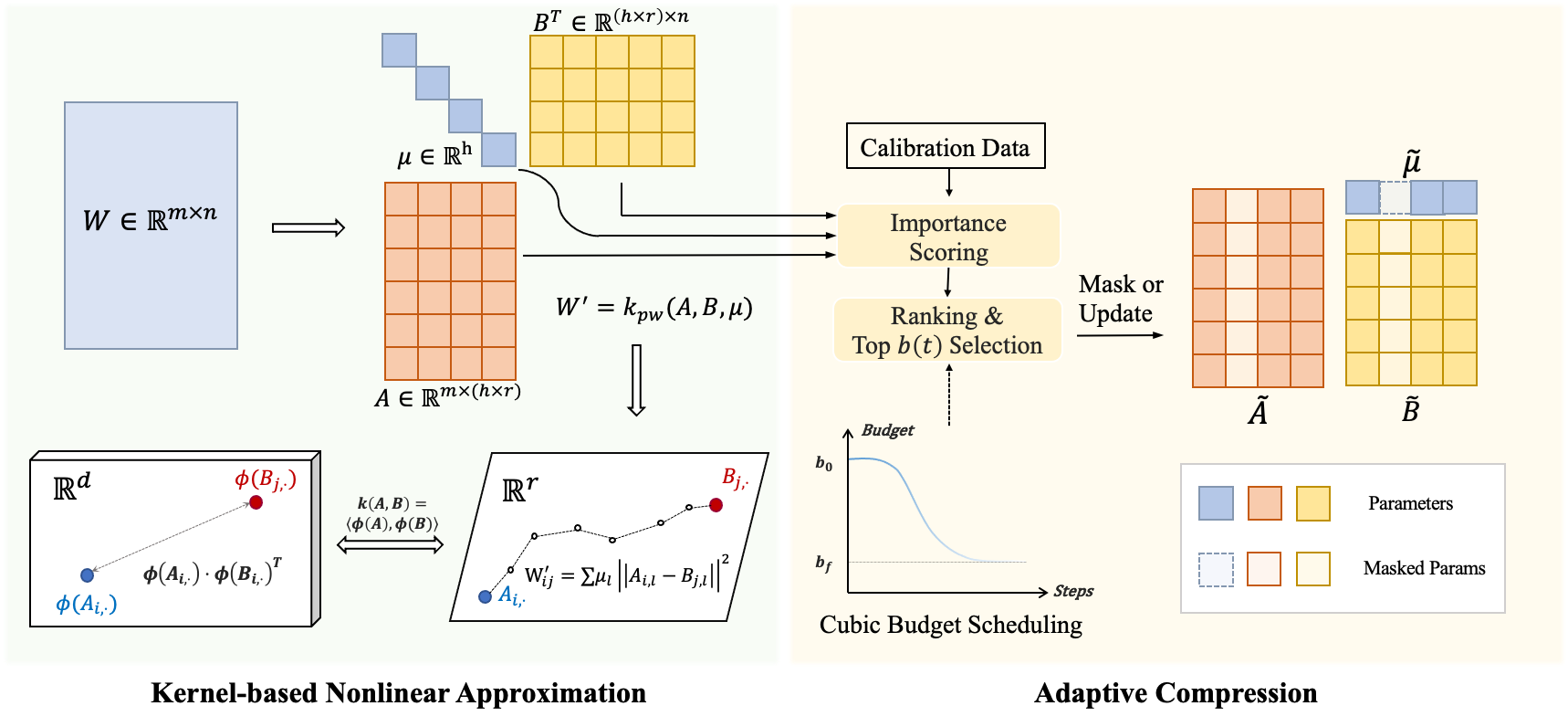
Despite achieving superior performance, large foundation models (LFMs) have substantial memory requirements, leading to a growing demand for model compression methods. While low-rank approximation presents a promising hardware-friendly solution, existing linear methods suffer significant information losses due to rank truncation. Nonlinear kernels can enhance expressiveness by operating in higher-dimensional spaces, yet most kernels introduce prohibitive overhead and struggle to support adaptive rank allocation across heterogeneous matrices. In this paper, we propose a compression method called Nonlinear Low-Rank Approximation with Adaptive Budget Allocation (NLA). Instead of relying on linear products, we employ piecewise-linear kernels with a forward-pass optimization operator to approximate weight matrices, enhancing the recovery of high-rank weight matrices from low-rank matrices. Moreover, considering the heterogeneous representation abilities and dynamic sensitivities of different weight matrices, we adaptively allocate the compression ratio of each weight matrix during the re-training process by cubic sparsity scheduling. Through evaluations on large language models and vision models across various datasets, NLA demonstrates superior performance while achieving a higher compression ratio compared to existing methods.
Download: