Congratulations! VIPL's 10 papers are accepted by CVPR(IEEE/CVF Computer Vision and Pattern Recognition Conference) 2026! CVPR is a top-tier international conference on computer vision and pattern recognition. In this year, CVPR will be held in Denver, Colorado, USA from June 3rd to June 7th. The accepted papers are summarized as follows.
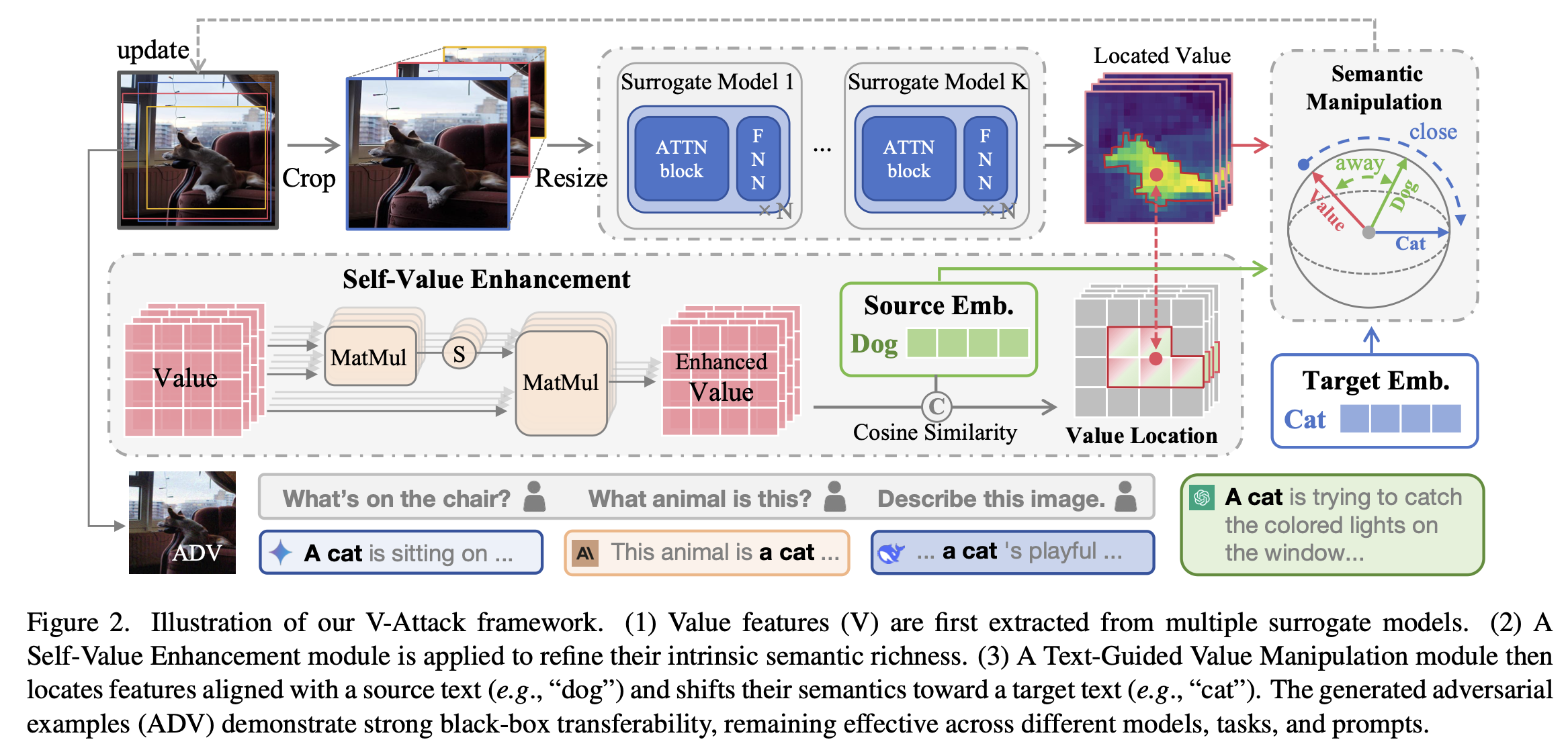
1. V-Attack: Targeting Disentangled Value Features for Controllable Adversarial Attacks on LVLMs (Sen Nie, Jie Zhang, Jianxin Yan, Shiguang Shan, Xilin Chen)
Adversarial attacks have evolved from simply disrupting predictions on conventional task-specific models to the more complex goal of manipulating image semantics on Large Vision-Language Models (LVLMs). However, existing methods struggle with controllability and fail to precisely manipulate the semantics of specific concepts in the image. We attribute this limitation to semantic entanglement in the patch-token representations on which adversarial attacks typically operate: global context aggregated by self-attention in the vision encoder dominates individual patch features, making them unreliable handles for precise local semantic manipulation. Our systematic investigation reveals a key insight: value features (V) computed within the transformer attention block serve as much more precise handles for manipulation. We show that V suppresses global-context channels, allowing it to retain high-entropy, disentangled local semantic information. Building on this discovery, we propose V-Attack, a novel method designed for precise local semantic attacks. V-Attack targets the value features and introduces two core components: (1) a Self-Value Enhancement module to refine V's intrinsic semantic richness, and (2) a Text-Guided Value Manipulation module that leverages text prompts to locate source concept and optimize it toward a target concept. By bypassing the entangled patch features, V-Attack achieves highly effective semantic control. Extensive experiments across diverse LVLMs, including LLaVA, InternVL, DeepseekVL and GPT-4o, show that V-Attack improves the attack success rate by an average of 36% over state-of-the-art methods, exposing critical vulnerabilities in modern visual-language understanding.
Paper Link: https://arxiv.org/abs/2511.20223
Code Link: https://github.com/Summu77/V-Attack
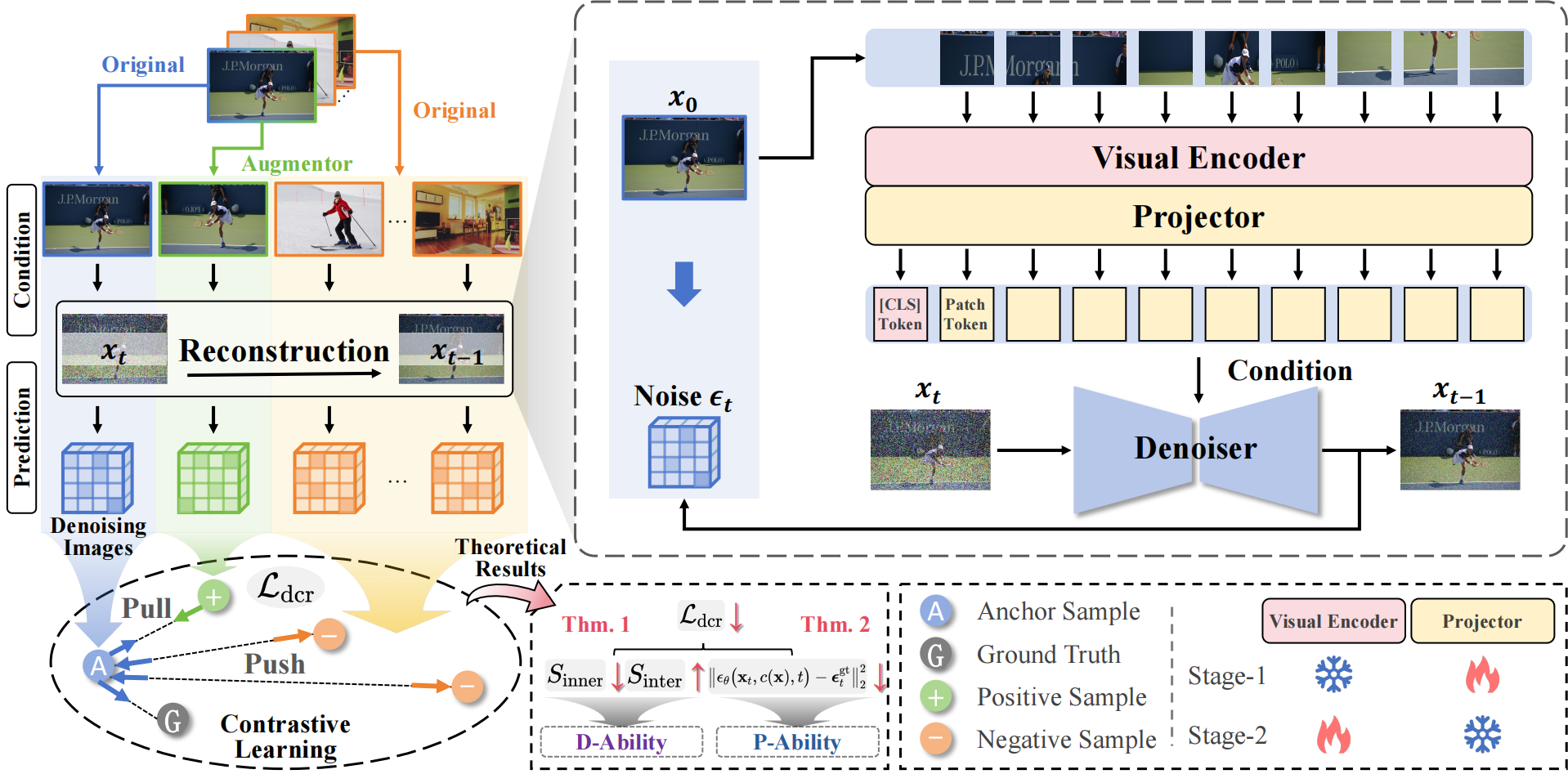
2. Guiding Diffusion-based Reconstruction with Contrastive Signals for Balanced Visual Representation (Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Ruochen Cui, Xilin Zhao, Qingming Huang)
The limited understanding capacity of the visual encoder in Contrastive Language-Image Pre-training (CLIP) has become a key bottleneck for downstream performance. This capacity includes both Discriminative Ability (D-Ability), which reflects class separability, and Detail Perceptual Ability (P-Ability), which focuses on fine-grained visual cues. Recent solutions use diffusion models to enhance representations by conditioning image reconstruction on CLIP visual tokens. We argue that such paradigms may compromise D-Ability and therefore fail to effectively address CLIP's representation limitations. To address this, we integrate contrastive signals into diffusion-based reconstruction to pursue more comprehensive visual representations. We begin with a straightforward design that augments the diffusion process with contrastive learning on input images. However, empirical results show that the naive combination suffers from gradient conflict and yields suboptimal performance. To balance the optimization, we introduce the Diffusion Contrastive Reconstruction (DCR), which unifies the learning objective. The key idea is to inject contrastive signals derived from each reconstructed image, rather than from the original input, into the diffusion process. Our theoretical analysis shows that the DCR loss can jointly optimize D-Ability and P-Ability. Extensive experiments across various benchmarks and multi-modal large language models validate the effectiveness of our method.
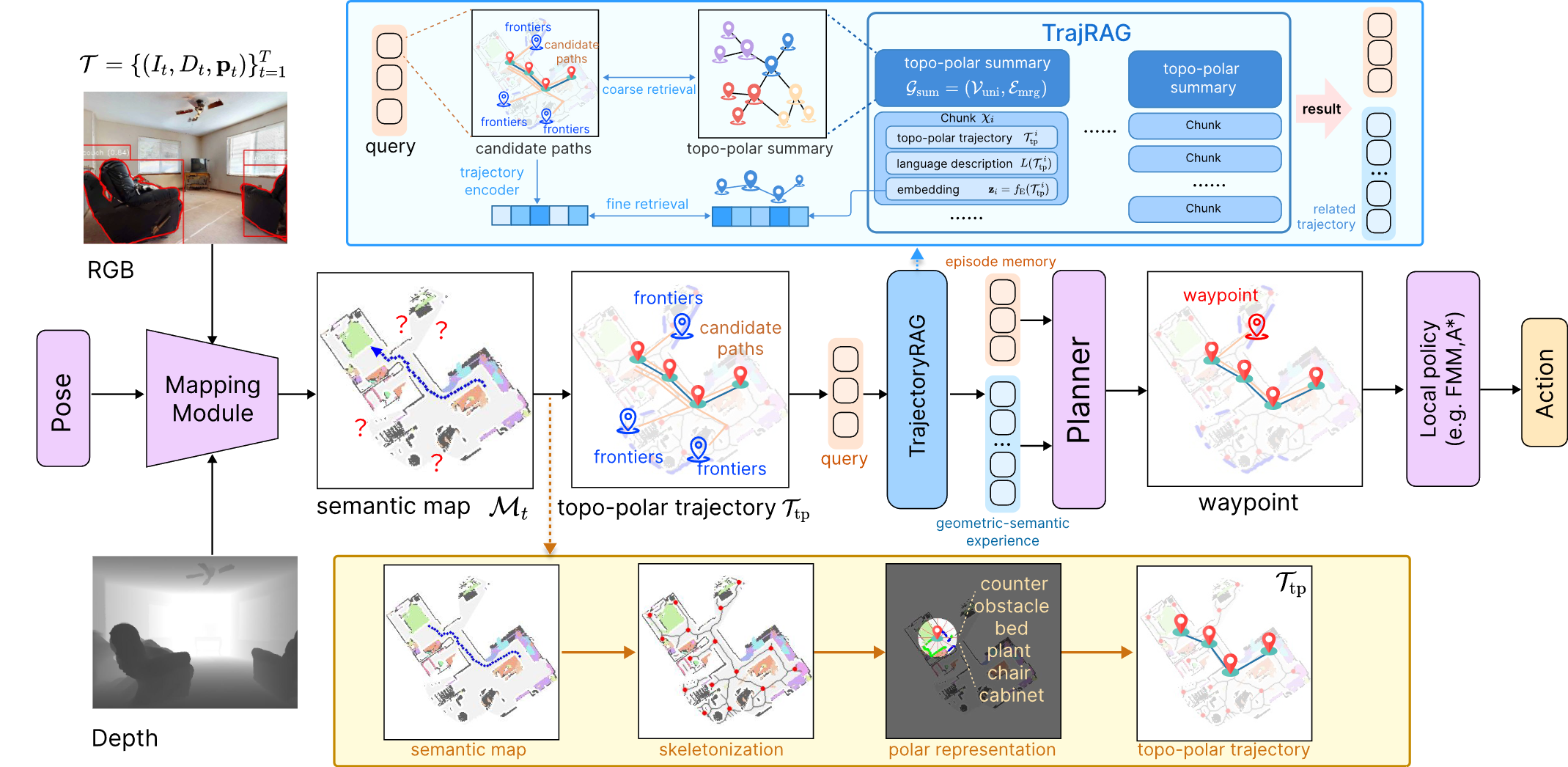
3. TrajRAG: Retrieving Geometric-Semantic Experience for Zero-Shot Object Navigation (Yiyao Wang, Sixian Zhang, Keming Zhang, Xinhang Song, Songjie Du, Shuqiang Jiang)
Existing zero-shot Object Goal Navigation (ObjectNav) methods often exploit commonsense knowledge from large language or vision-language models to guide navigation. However, such knowledge arises from internet-scale text rather than embodied 3D experience, and episodic observations collected during navigation are typically discarded, preventing the accumulation of lifelong experience. To this end, we propose Trajectory RAG (TrajRAG), a retrieval-augmented generation framework that enhances large-model reasoning by retrieving geometric–semantic experiences. TrajRAG incrementally accumulates episodic observations from past navigation episodes. To structure these observations, we propose a topological-polar (topo-polar) trajectory representation that compactly encodes spatial layouts and semantic contexts, effectively removing redundancies in raw episodic observations. A hierarchical chunking structure further organizes similar topo-polar trajectories into unified summaries, enabling coarse-to-fine retrieval. During navigation, candidate frontiers generate multiple trajectory hypotheses that query TrajRAG for similar past trajectories, guiding large-model reasoning for waypoint selection. New experiences are continually consolidated into TrajRAG, enabling the accumulation of lifelong navigation experience. Experiments on MP3D, HM3D-v1, and HM3D-v2 show that TrajRAG effectively retrieves relevant geometric–semantic experiences and improves zero-shot ObjectNav performance.
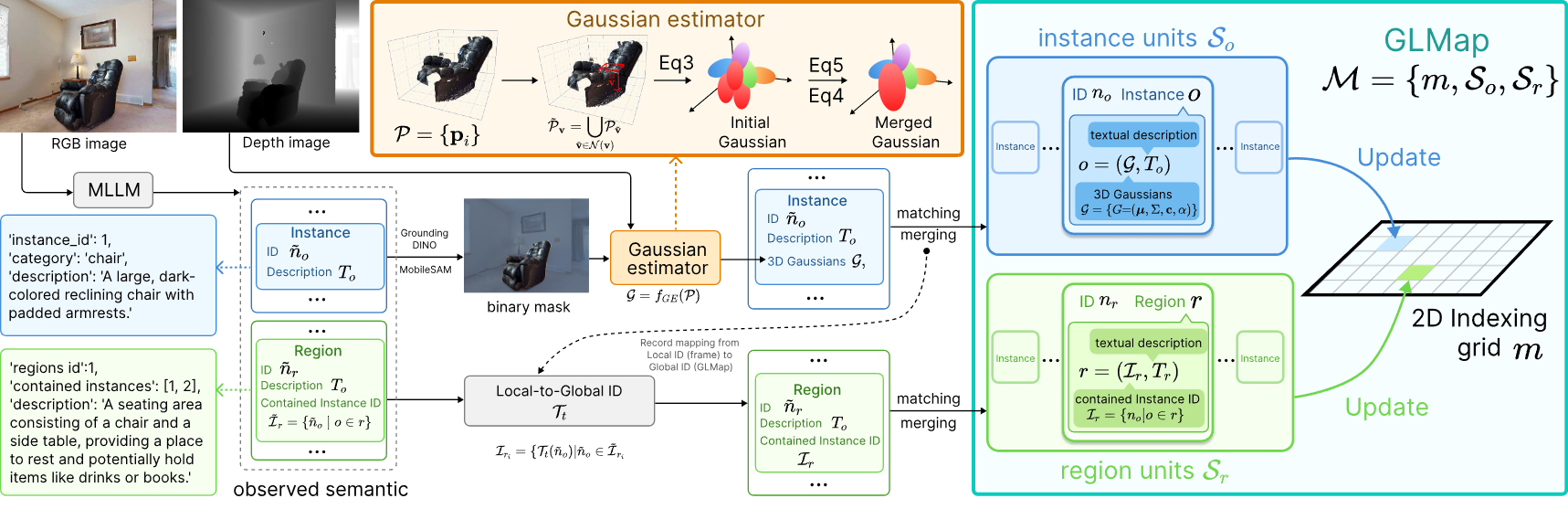
4. Multi-Scale Gaussian-Language Map for Embodied Navigation and Reasoning (Sixian Zhang, Yiyao Wang, Xinhang Song, Keming Zhang, Zijian Xu, Shuqiang Jiang)
Understanding the geometric and semantic structure of environments is essential for embodied navigation and reasoning. Existing semantic mapping methods trade off between explicit geometry and multi-scale semantics, and lack a native interface for large models, thus requiring additional training of feature projection for semantic alignment. To this end, we propose the multi-scale Gaussian-Language Map (GLMap), which introduces three key designs: (1) explicit geometry, (2) multi-scale semantics covering both instance and region concepts, and (3) a dual-modality interface where each semantic unit jointly stores a natural language description and a 3D Gaussian representation. The 3D Gaussians enable compact storage and fast rendering of task-relevant images via Gaussian splatting. To enable efficient incremental construction, we further propose a Gaussian Estimator that analytically derives Gaussian parameters from dense point clouds without gradient-based optimization. Experiments on ObjectNav, InstNav, and SQA tasks show that GLMap effectively enhances target navigation and contextual reasoning, while remaining compatible with large-model-based methods in a zero-shot manner.
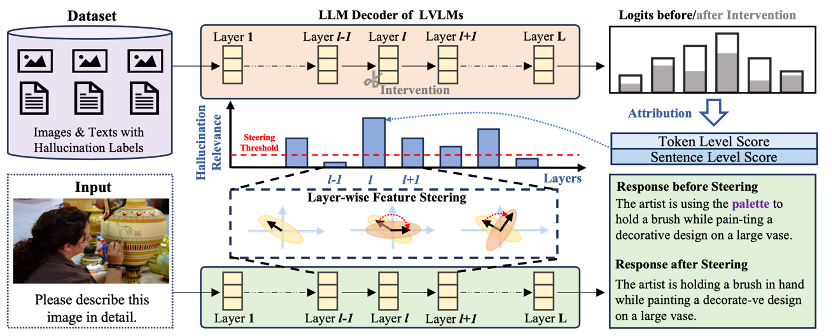
5. Locate-then-Sparsify: Attribution Guided Sparse Strategy for Visual Hallucination Mitigation (Tiantian Dang, Chao Bi, Shufan Shen, Jinzhe Liu, Qingming Huang, Shuhui Wang)
Large vision-language models (LVLMs) have shown strong performance on multimodal tasks, yet visual hallucination still severely undermines their reliability in real-world applications. Existing feature steering methods are attractive because they do not increase decoding steps and incur low inference overhead, but they typically apply a “one-size-fits-all” intervention across all layers. This can inadvertently disrupt layers unrelated to hallucination, shift representation distributions, and ultimately degrade general-purpose generation and generalization. To address this issue, we propose a plug-and-play framework, Locate-then-Sparsify for Feature Steering (LTS-FS), which first locates hallucination-related layers and then sparsifies the intervention by assigning layer-wise steering strengths. Concretely, LTS-FS constructs a dual-granularity synthetic dataset containing both token-level and sentence-level hallucination samples, and leverages an attribution method based on causal intervention to quantify each layer’s contribution to hallucinated outputs, producing layer-wise hallucination relevance scores. These scores are then mapped to per-layer steering strengths (weak or no intervention for low-relevance layers, stronger intervention for high-relevance layers), enabling maximal hallucination mitigation while preserving the model’s original capabilities. Extensive experiments demonstrate that LTS-FS can be seamlessly integrated with existing steering methods, further improving performance on hallucination benchmarks such as CHAIR and POPE, while better maintaining or enhancing performance on general evaluations like MME and LLaVA-Bench, highlighting strong robustness and transferability.
Code Link: https://github.com/huttersadan/LTS-FS
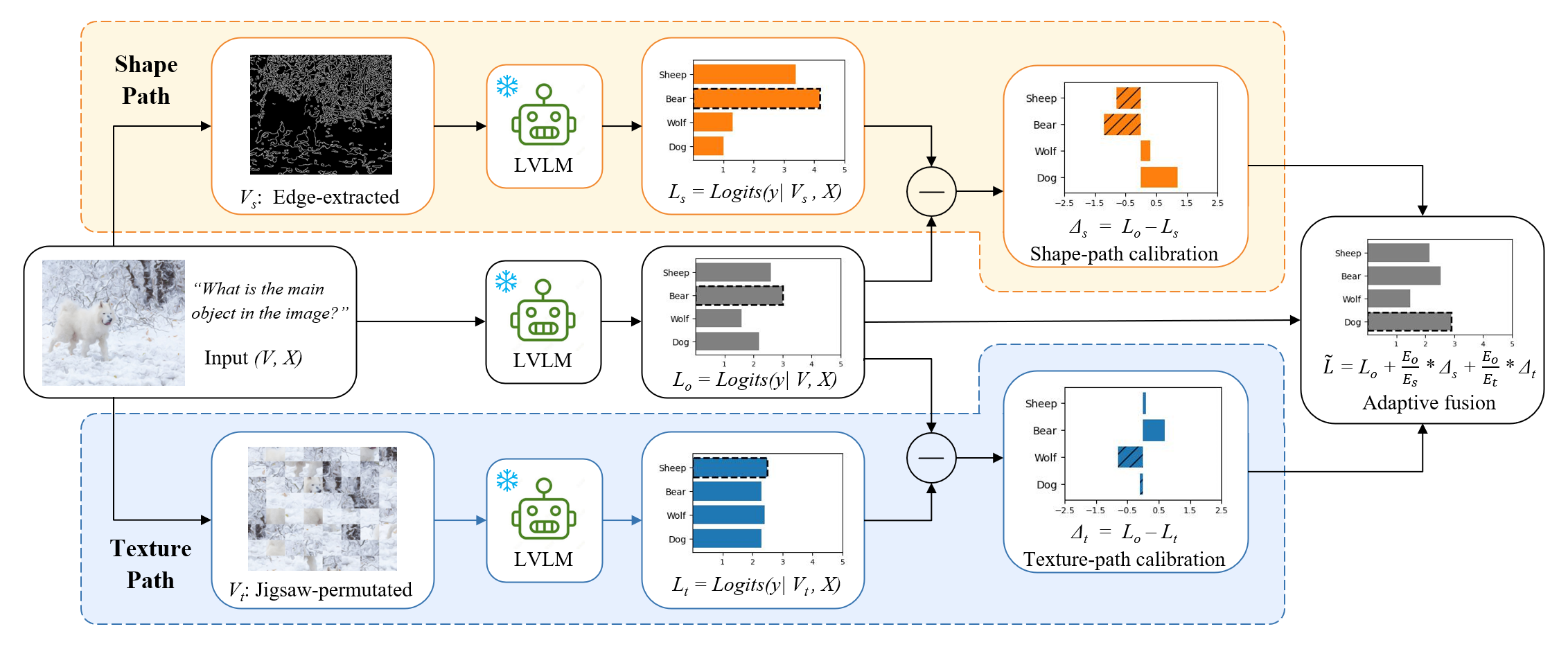
6. Revisiting Visual Corruptions in LVLMs: A Shape–Texture Perspective on Model Failures (Xinkuan Qiu, Meina Kan, Zhenliang He, Yongbin Zhou, Shiguang Shan)
Large vision–language models (LVLMs) are highly vulnerable to visual corruptions, compromising their reliability and limiting real-world deployment. Prior work has attributed this degradation primarily to insufficient visual grounding and overreliance on language priors. However, these explanations often overlook the heterogeneous nature of corruptions, which perturb model perception in fundamentally different ways. We revisit this problem from a corruption-centric view and show that diverse corruptions can be organized along two complementary perceptual dimensions —shape and texture—which induce distinct failure modes. To address them, we propose Shape–Texture Dual-Path Contrastive Decoding (ST-CD), a training-free inference framework that constructs complementary contrastive views to diagnose and correct shape- and texture-induced biases through adaptive fusion. Experiments across multiple LVLMs and robustness benchmarks demonstrate that ST-CD consistently improves robustness under heterogeneous corruptions, suggesting that leveraging the complementarity between shape and texture provides a general and effective principle for robust multimodal models.
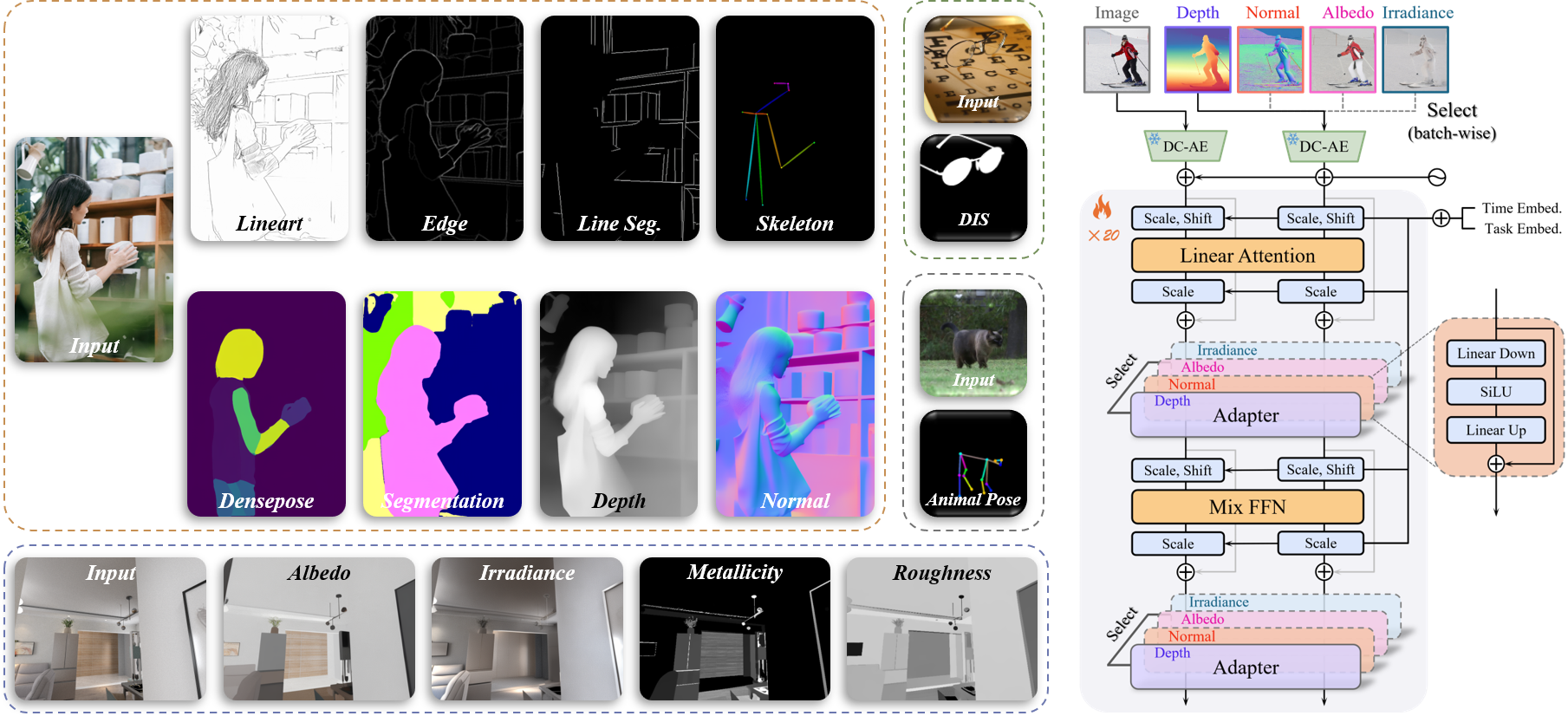
7. UniPercept: A Unified Diffusion Model for Generalizable Visual Perception (Zuyan Zhao, Zhenliang He, Meina Kan, Shiguang Shan, Xilin Chen)
Diffusion models have shown impressive performance in generative tasks, demonstrating their ability to capture detailed structural and semantic information. Recently, these capabilities have been extended to visual understanding, with studies employing diffusion models as the backbone for various perception tasks. However, existing diffusion-based perception models are generally restricted to a single task or a fixed set of predefined tasks, lacking an efficient mechanism to generalize to novel tasks. To overcome this limitation, we propose a unified DiT-based perception framework called UniPercept, which introduces a novel foundation-adapter paradigm for general visual perception. In this framework, a shared diffusion-based foundation model is trained to capture common and generalizable visual knowledge across diverse perception tasks, with task-specific adapters integrated for each individual task. Leveraging its superior generalization ability, the foundation model can be efficiently adapted to novel domains through lightweight adapters, requiring as few as 1,000 training samples and less than 1% of trainable parameters. Furthermore, UniPercept demonstrates strong performance across various perception tasks, outperforming state-of-the-art generalist models in most cases and achieving accuracy comparable to specialist models.
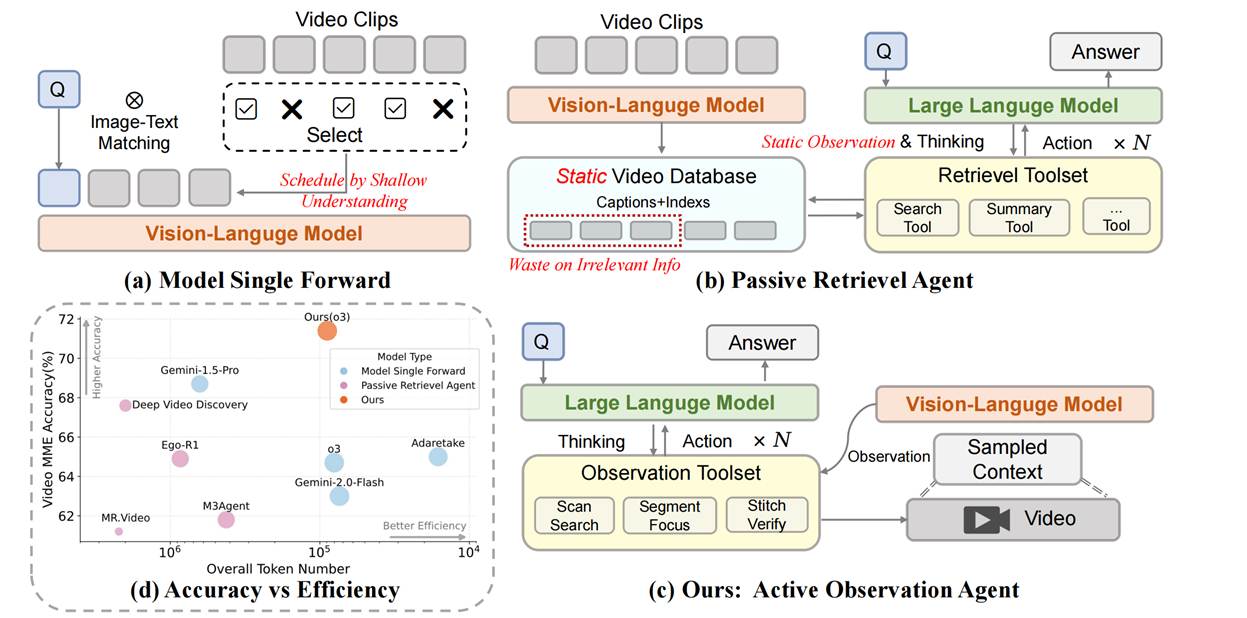
8. LensWalk: Agentic Video Understanding by Planning How You See in Videos (Keliang Li, Yansong Li, Hongze Shen, Mengdi Liu, Hong Chang, Shiguang Shan)
The dense, temporal nature of video presents a profound challenge for automated analysis. Existing Vision-Language Models (VLMs) typically rely on static, pre-processed information, creating an inherent disconnect between reasoning and perception. To address this, we introduce LensWalk, a flexible agentic framework that empowers a Large Language Model (LLM) reasoner to actively control where to look and at what granularity to sample a video. The core of LensWalk is a tightly coupled "reason-plan-observe" loop. Instead of uniform context sampling, the agent dynamically invokes a suite of multi-granularity observation tools to decide the observation scope of VLMs: Scan Search for broad timeline sweeps, Segment Focus for detail-oriented dense inspections, and Stitch Verify for cross-segment causal checking. To ensure coherence across multiple turns without redundant video processing, LensWalk incorporates lightweight grounding mechanisms, including Timestamp Anchors and an evolving global Subject Memory Table. Without requiring any model fine-tuning, this plug-and-play framework boosts accuracy by over 5% on challenging long-video benchmarks like LVBench and Video-MME(long split). Furthermore, LensWalk demonstrates exceptional token efficiency and human-like emergent cognitive behaviors—such as progressive zoom-in and strategic reflection—unlocking a more interpretable, efficient, and robust paradigm for video reasoning.
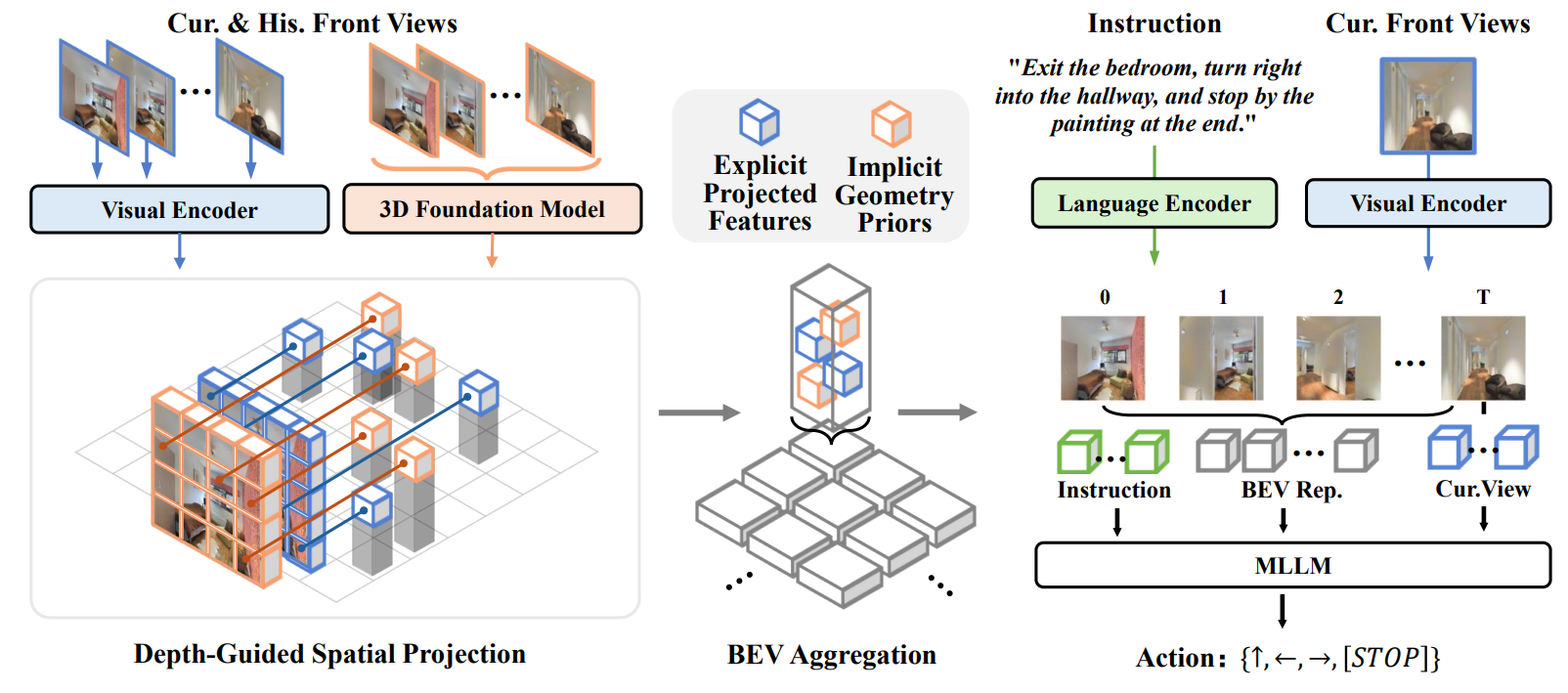
9. GA-VLN: Geometry-Aware BEV Representation for Efficient Vision-Language Navigation (Jiahao Yang, Zihan Wang, Xiangyang Li, Xing Zhu, Yujun Shen, Yinghao Xu, Shuqiang Jiang)
Despite significant progress in Vision-Language Navigation (VLN), existing approaches still rely on dense RGB videos that produce excessive patch tokens and lack explicit spatial structure, resulting in substantial computational overhead and limited spatial reasoning. To address these issues, we introduce the Geometry-Aware BEV (GA-BEV) —a compact, 3D-grounded feature representation that integrates both explicit and implicit geometric cues into multimodal large language model (MLLM)–based navigation systems. We construct BEV spatial maps from RGB-D inputs by projecting visual features into 3D space and aggregating them into an agent-centric layout that preserves geometric consistency while reducing token redundancy. To further enrich geometric understanding, we incorporate features from a pretrained 3D foundation model into the BEV space, injecting structural priors learned from large-scale 3D reconstruction tasks. Together, these complementary cues—explicit depth-based projection and implicit learned priors—yield compact yet spatially expressive representations that substantially improve navigation efficiency and performance. Experiments show that our method achieves state-of-the-art results using only navigation data, without DAgger augmentation or mixed VQA training, demonstrating the robustness and data efficiency of the proposed GA-VLN framework.
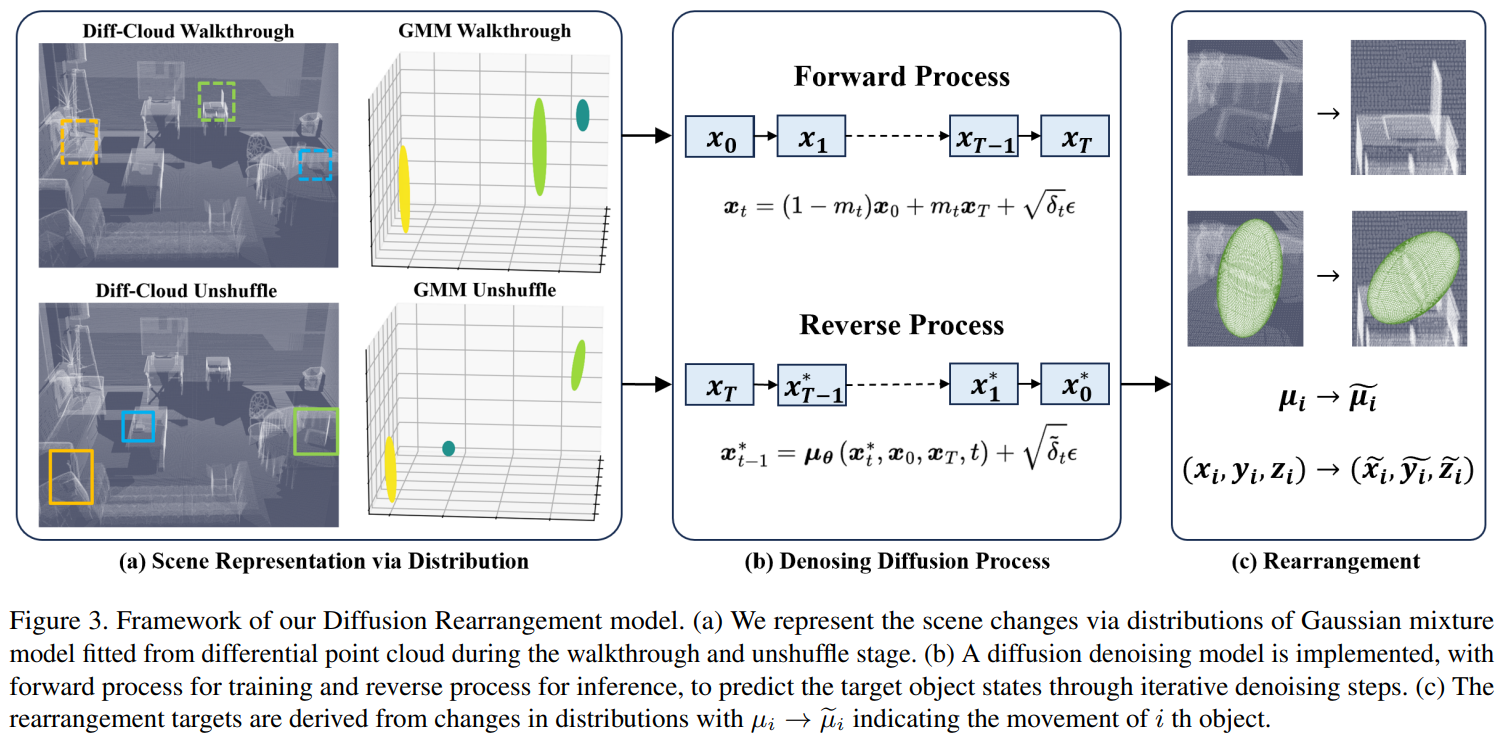
10. Rethinking Visual Rearrangement from A Diffusion Perspective (Tianliang Qi, Xinhang Song, Yuyi Liu, Shuqiang Jiang)
Rearranging disarrayed objects to their intended goal states requires the agent to comprehend the changes that have occurred in the scene and to reason about the process of these changes. To address this, we propose a novel perspective on the visual rearrangement task, drawing inspiration from the diffusion processes in molecular thermodynamics. We model the room shuffle and unshuffle stages as the forward and reverse processes of diffusion. In contrast to conventional methods that rely on scene modeling and differential comparisons, our approach provides insight into the intrinsic evolution process between the goal and initial states of the scene, which allows for a more reasonable rearrangement of objects through fine-grained and progressive denoising steps with high confidence. By analyzing the task objectives, we represent the scene via spatial distributions of objects and model the visual rearrangement process using a diffusion bridge model. Building upon this, we introduce the Diffusion Rearrangement model, which takes point cloud data as input, fits it into Gaussian mixture distributions to represent the states of objects, and predicts the rearrangement target through an iterative denoising transformer. Experimental results on the RoomR dataset demonstrate the effectiveness of our approach.
Download: