1. Overview
ImageNet-150K dataset is a subset of ImageNet with additional visual attribute annotations. The images are associated with category and visual attribute labels, and thus can be used for many different tasks, e.g. hash learning, attribute learning, and so on. Specifically, the dataset contains 1,000 categories with 150 images per category, resulting in 150,000 images in total. Moreover, we further select 50,000 out of 150,000 images (50 images per category) to annotate 25 visual attributes including color, texture, shape, material, and structure. The final attributes annotations are presented with three values, i.e. +1, −1, and 0, for indicating the presence, absence, and uncertainty of a specific attribute respectively.
2. Data annotation
Based on the ImageNet dataset, 1000 categories with 150 images (148 images from the training set and 2 images from the validation set) per category are randomly selected to form the ImageNet-150K dataset. Moreover, we further select 50 out of 150 images per category (48 images from the training set and 2 images from the validation set) to annotate 25 visual attributes including color, texture, shape, material, and structure. The final attributes annotations are presented with three values, i.e. +1, −1, and 0, for indicating the presence, absence, and uncertainty of a certain attribute respectively. Specifically, for each attribute of each image, three individual annotators are required to choose from positive, negative, or uncertain to indicate the presence of that attribute in the image. Images with at least two annotations of positive/negative are labeled as +1/-1 respectively (i.e. positive/negative sample of the specific attribute), and the other images are labeled as 0 (uncertain).
The annotated attributes on this dataset in order are: (1) black, (2) blue, (3) brown, (4) gray, (5) green, (6) orange, (7) pink, (8) red, (9) purple, (10) white, (11) yellow, (12) colorful, (13) spots, (14) stripes, (15) rectangular, (16) round, (17) columnar, (18) sharp, (19) metal, (20) wooden, (21) furry, (22) has tail, (23) has horn, (24) has two legs/bipedal, (25) has four legs/quadruped. Some examples are given below:
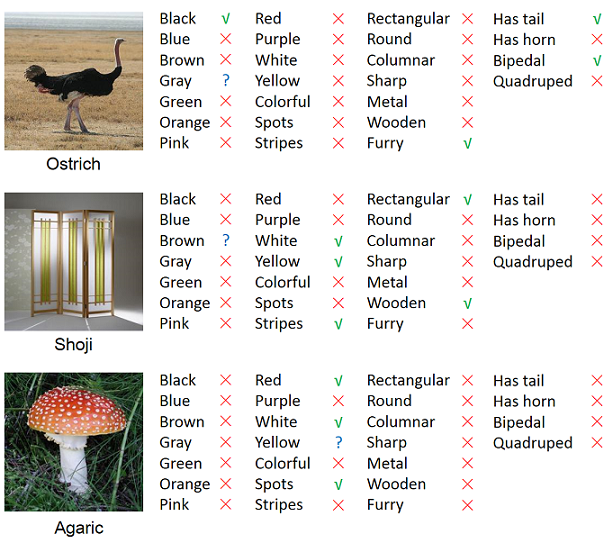
3. Data partition
We suggest dividing the 50,000 images with both identity and attribute labels into two parts. The first part consists of the 48 images per category from the training set of ImageNet (48,000 images in total), and should be used to train the model. While the second part are the 2 images of each category from the validation set, and should be used to evaluate the model. With such a partition, the pre-trained models could be leveraged without worrying about exploiting validation data in the training stage. Besides, the remaining 100,000 images that only have category labels constitute the auxiliary set, which are also used for training.
4. Contact
Ruiping Wang (wangruiping@ict.ac.cn), Institute of Computing Technology, Chinese Academy of Sciences
Haomiao Liu (haomiao.liu@vipl.ict.ac.cn), Institute of Computing Technology, Chinese Academy of Sciences
5. Download
The ImageNet-150K dataset is released to
universities and research institutes for research purpose only. To request a
copy of the ImageNet-150K dataset, please do as follows:
• Send an email to Dr. Wang (wangruiping@ict.ac.cn). When we receive your email, we would provide the download link to you.
• By using the ImageNet-150K dataset, you are recommended to refer to the following paper:
Haomiao Liu, Ruiping Wang, Shiguang Shan, Xilin Chen. Learning Multifunctional Binary Codes for Both Category and Attribute Oriented Retrieval Tasks. Computer Vision and Pattern Recognition (CVPR), pp: 6259-6268, July 2017.
Download: