Congratulations! VIPL’s paper on self-supervised video representation learning, "Collaboratively Self-supervised Video Representation Learning for Action Recognition" (authors: Jie Zhang, Zhifan Wan, Lanqing Hu, Stephen Lin, Shuzhe Wu, Shiguang Shan), was accepted by IEEE Transactions on Information Forensics & Security (T-IFS). T-IFS is a CCF-A journal in the fields of artificial intelligence and information security.
Considering the close connection between action recognition and human pose estimation, we design a Collaboratively Self-supervised Video Representation (CSVR) learning framework specific to action recognition by jointly factoring in generative pose prediction and discriminative context matching as pretext tasks. Specifically, our CSVR consists of three branches: a generative pose prediction branch, a discriminative context matching branch, and a video generating branch. Among them, the first one encodes dynamic motion feature by utilizing Conditional-GAN to predict the human poses of future frames, and the second branch extracts static context features by contrasting positive and negative video feature and I-frame feature pairs. The third branch is designed to generate both current and future video frames, for the purpose of collaboratively improving dynamic motion features and static context features. Extensive experiments demonstrate that our method achieves state-of-the-art performance on multiple popular video datasets.
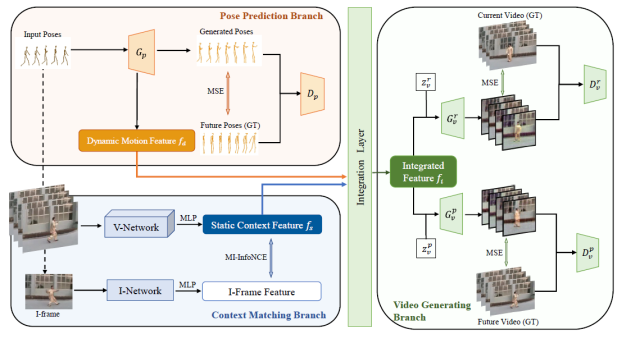
Figure 1. An overview of our self-supervised learning progress. Our CSVR contains three branches: pose prediction branch, context matching branch, and video generating branch.
Download: