Congratulations! VIPL's 6 papers are accepted by CVPR(IEEE/CVF Computer Vision and Pattern Recognition Conference) 2025! CVPR is a top-tier international conference on computer vision and pattern recognition. In this year, CVPR will be held in Nashville, Tennessee, USA on Jun 11th through the 15th. The accepted papers are summarized as follows.
1. UniPose: A Unified Multimodal Framework for Human Pose Comprehension, Generation and Editing (Yiheng Li, Ruibing Hou, Hong Chang, Shiguang Shan, Xilin Chen)
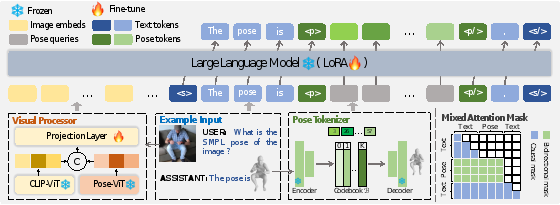
Human pose plays a crucial role in the digital age. While recent works have achieved impressive progress in understanding and generating human poses, they often support only a single modality of control signals and operate in isolation, limiting their application in real-world scenarios. This paper presents UniPose, a framework employing Large Language Models (LLMs) to comprehend, generate, and edit human poses across various modalities, including images, text, and 3D SMPL poses. The method overview is shown in Fig. 1. Specifically, we apply a pose tokenizer to convert 3D poses into discrete pose tokens, enabling seamless integration into the LLM within a unified vocabulary. To further enhance the fine-grained pose perception capabilities, we facilitate UniPose with a mixture of visual encoders, among them a pose-specific visual encoder. Benefiting from a unified learning strategy, UniPose effectively transfers knowledge across different pose-relevant tasks, adapts to unseen tasks, and exhibits extended capabilities. This work serves as the first attempt at building a general-purpose framework for pose comprehension, generation, and editing. Extensive experiments highlight UniPose's competitive and even superior performance across various pose-relevant tasks.
2. R2C: Mapping Room to Chessboard to Unlock LLM As Low-Level Action Planner (Ziyi Bai, Hanxuan Li, Bin Fu, Chuyan Xiong, Ruiping Wang, Xilin Chen)
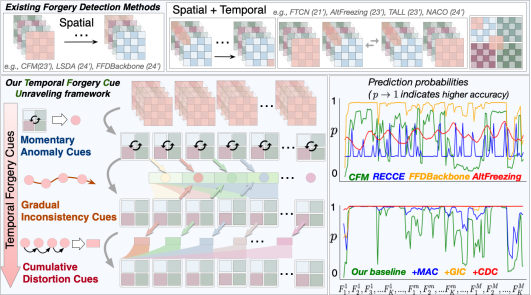
3. Face Forgery Video Detection via Temporal Forgery Cue Unraveling (Zonghui Guo, Yingjie Liu, Jie Zhang, Haiyong Zheng, Shiguang Shan)
Face Forgery Video Detection (FFVD) is a critical yet challenging task in determining whether a digital facial video is authentic or forged. Existing FFVD methods typically focus on isolated spatial or coarsely fused spatiotemporal information, failing to leverage temporal forgery cues thus resulting in unsatisfactory performance. This paper strives to unravel these cues across three progressive levels: momentary anomaly, gradual inconsistency, and cumulative distortion. Accordingly, this paper designs a consecutive correlate module to capture momentary anomaly cues by correlating interactions among consecutive frames. Then, this paper devises a future guide module to unravel inconsistency cues by iteratively aggregating historical anomaly cues and gradually propagating them into future frames. Finally, this paper introduce a historical review module that unravels distortion cues via momentum accumulation from future to historical frames. These three modules form our Temporal Forgery Cue Unraveling (TFCU) framework, sequentially highlighting spatial discriminative features by unraveling temporal forgery cues bidirectionally between historical and future frames. Extensive experiments and ablation studies demonstrate the effectiveness of our TFCU method, achieving state-of-the-art performance across diverse unseen datasets and manipulation methods. Code will be made publicly available.
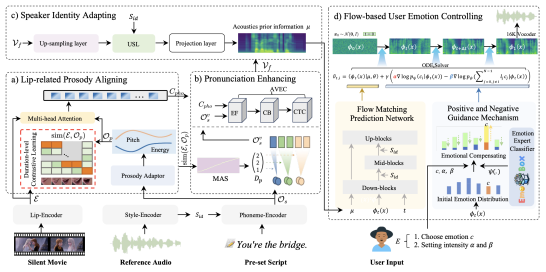
4. EmoDubber: Towards High Quality and Emotion Controllable Movie Dubbing (Gaoxiang Cong, Jiadong Pan, Liang Li, Yuankai Qi, Yuxin Peng, Anton van den Hengel, Jian Yang, Qingming Huang)
Given a piece of text, a video clip, and a reference audio, the movie dubbing task aims to generate speech that aligns with the video while cloning the desired voice. The existing methods have two primary deficiencies: (1) They struggle to simultaneously hold audio-visual sync and achieve clear pronunciation; (2) They lack the capacity to express user-defined emotions. To address these problems, this paper proposes EmoDubber, an emotion-controllable dubbing architecture that allows users to specify emotion type and emotional intensity while satisfying high-quality lip sync and pronunciation. The method overview is shown in Fig. 1. Specifically, this paper first designs Lip-related Prosody Aligning (LPA), which focuses on learning the inherent consistency between lip motion and prosody variation by duration level contrastive learning to incorporate reasonable alignment. Then, this paper designs Pronunciation Enhancing (PE) strategy to fuse the video-level phoneme sequences by efficient conformer to improve speech intelligibility. Next, the speaker identity adapting module aims to decode acoustics prior and inject the speaker style embedding. After that, the proposed Flow-based User Emotion Controlling (FUEC) is used to synthesize waveform by flow matching prediction network conditioned on acoustics prior. In this process, the FUEC determines the gradient direction and guidance scale based on the user's emotion instructions by the positive and negative guidance mechanism (PNGM), which focuses on amplifying the desired emotion while suppressing others. Extensive experimental results on three benchmark datasets demonstrate favorable performance compared to several state-of-the-art methods.
5. Video Language Model Pretraining with Spatio-temporal Masking (Yue Wu, Zhaobo Qi, Junshu Sun, Yaowei Wang, Qingming Huang, Shuhui Wang)
The development of video-language self-supervised models based on mask learning has significantly advanced downstream video tasks. These models leverage masked reconstruction to facilitate joint learning of visual and linguistic information. However, a recent study reveals that reconstructing image features yields superior downstream performance compared to video feature reconstruction. This paper hypothesizes that this performance gap stems from how masking strategies influence the model's attention to temporal dynamics. To validate this hypothesis, this paper conducts two sets of experiments demonstrating that alignment between masked object and reconstruction target is crucial for effective video-language self-supervised learning. Based on these findings, this paper proposes a spatio-temporal masking strategy (STM) for video-language model pretraining that operates across adjacent frames, and a decoder leverages semantic information to enhance the spatio-temporal representations of masked tokens. Through the combination of masking strategy and reconstruction decoder, STM enforces the model to learn the spatio-temporal feature representation more comprehensively. Experimental results across three video understanding downstream tasks validate the superiority of our method.

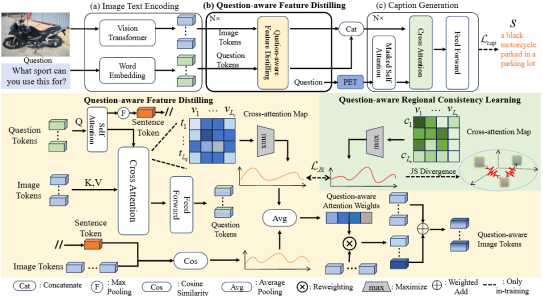
6. Separation of powers: On segregating knowledge from observation in LLM-enabled knowledge-based visual question answering (Zhen Yang, Zhuo Tao, Qi Chen, Yuankai Qi, Anton van den Hengel, Qingming Huang, Liang Li)
Knowledge-based visual question answering (KBVQA) separates image interpretation and knowledge retrieval into separate processes, motivated in part by the fact that they are very different tasks. In this paper, this paper transforms the KBVQA into linguistic question-answering tasks so that this paper can leverage the rich world knowledge and strong reasoning abilities of Large Language Models (LLMs). The caption-then-question approach to KBVQA has been effective, but relies on the captioning method to describe the detail required to answer every possible question. This paper proposes instead a Question-Aware Captioner (QACap), which uses the question as guidance to extract correlated visual information from the image and generate a question-related caption. To train such a model, This paper utilizes GPT-4 to build a corresponding high-quality question-aware caption dataset on top of existing KBVQA datasets. Extensive experiments demonstrate that our QACap model and dataset significantly improve KBVQA performance. Our method, QACap, achieves 68.2% accuracy on the OKVQA validation set, 73.4% on the direct-answer part of the A-OKVQA validation set, and 74.8% on the multiple-choice part, all setting new SOTA benchmarks.
Download: