实验室今年有9篇论文被IEEE ICCV2021接收,IEEE ICCV的全称是IEEE International Conference on Computer Vision (国际计算机视觉会议),是计算机视觉领域的三大顶级会议之一。
1. Meta Gradient Adversarial Attack (Zheng
Yuan, Jie Zhang, Yunpei Jia, Chuanqi Tan, Tao Xue, Shiguang Shan)
对抗攻击(Adversarial Attack)近年来成为了一个新的研究热点,该任务旨在于生成使得分类模型误分类的样本,以探索模型的鲁棒性。现有的基于迁移的对抗攻击方法已经在黑盒模型上取得了较好的迁移性,但仍然有进一步探索的空间。本文受到元学习的启发,提出了一个新的即插即用的框架Meta Gradient Adversarial Attack (MGAA),它可以和任何现有的基于梯度的攻击方法相结合来提高攻击方法的跨模态迁移性。具体地,我们每次从一个模型池中随机采样多个模型来组成不同的任务,在每个任务中迭代地模拟白盒和黑盒的攻击。通过优化目标函数,我们可以缩小白盒和黑盒攻击时梯度方向之间的差异,从而提高对抗样本在黑盒模型上的迁移性。大量在CIFAR10和ImageNet上的实验表明了我们的框架在白盒和黑盒攻击的设置下都超过了现有的最优方法。

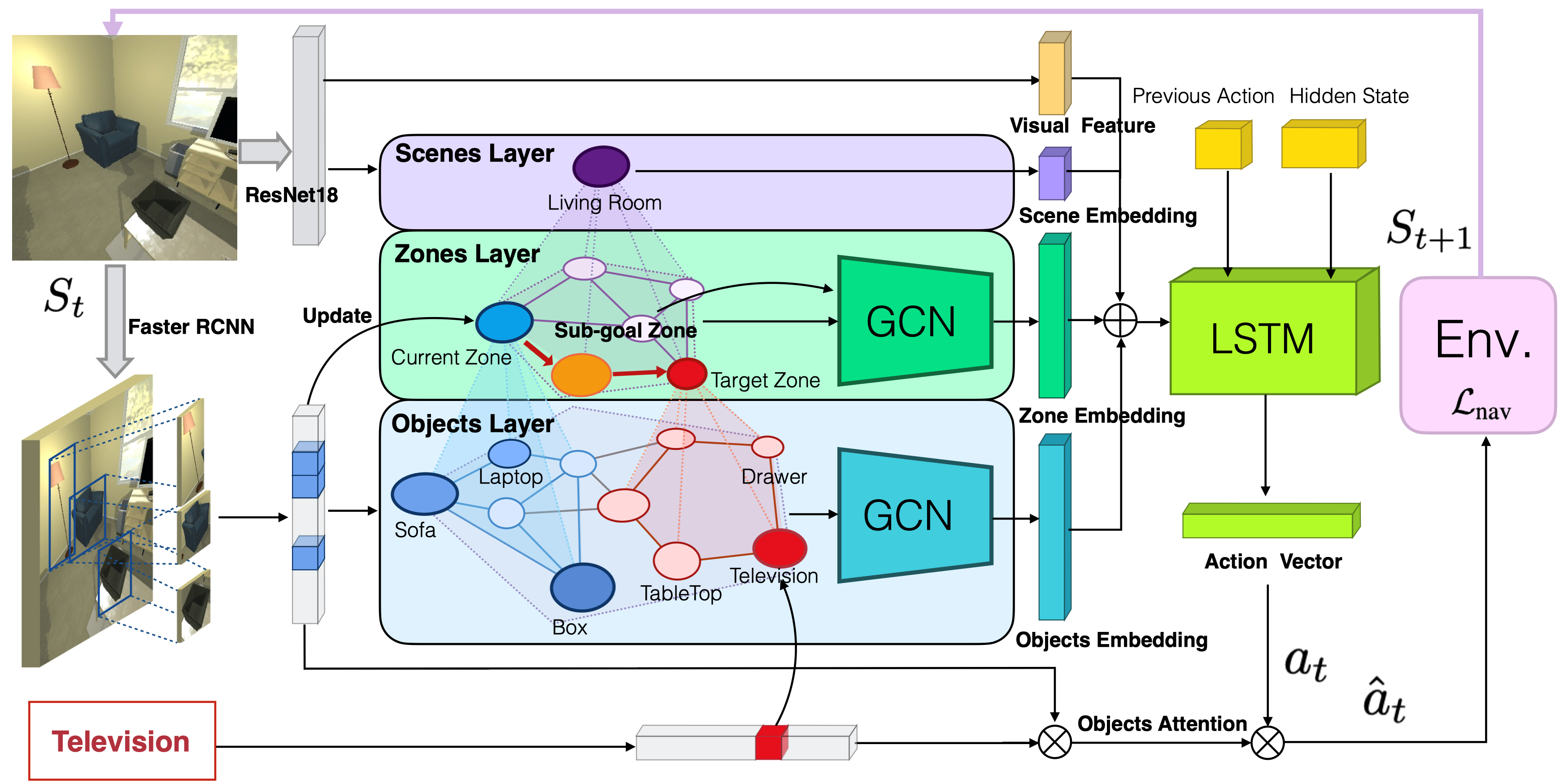
2. Hierarchical Object-to-Zone Graph for Object Navigation (Sixian Zhang, Xinhang Song, Yubing Bai, Weijie Li, Yakui Chu, Shuqiang Jiang)
物体导航任务是要求智能体在未知环境中找到指定的目标物体。先前的工作通常利用深度学习模型通过强化学习方式来训练智能体进行实时的动作预测。然而当目标物体没有出现在智能体的视野中,智能体往往由于缺乏指导而不能做出高效的动作。本文提出一种由物体到区域的多层级(hierarchical object-to-zone, HOZ)图,为智能体提供由粗到细的先验信息指导,并且HOZ图可以在新的环境中根据观测信息来不断更新。具体来说,HOZ图包含场景节点、区域节点和物体节点。借助于HOZ图,智能体可以根据目标物体以及当前观测规划出一条从当前区域到目标物体可能出现区域的路径。本文在AI2-Thor三维模型器中验证了所提出的方法,所选用的评测指标,除了常用的成功率(Success Rate, SR)和按路径长度加权的成功率(Success weighted by Path Length, SPL),本文还提出了用于评测导航中动作有效性的指标:按动作效率加权的成功率(Success weighted by Action Efficiency, SAE),实验结果证明了我们方法的有效性。
3. EigenGAN: Layer-Wise Eigen-Learning for GANs (Zhenliang He, Meina Kan, Shiguang Shan)
关于卷积神经网络可解释性的研究表明:判别式卷积网络的不同层能够捕捉到不同抽象程度的语义概念,比如,较浅的层用于检测颜色和纹理而较深的层更多地关注物体和部件。自然地,我们可以期待生成式卷积网络也拥有同样的性质。该论文提出一种针对生成对抗网络的层次化本征学习的方法(EigenGAN),通过无监督的方式使得生成网络在不同的网络层都拥有可解释的维度。具体来说,EigenGAN在每一个生成网络层都嵌入一个拥有正交基的线性子空间模型。一方面,因为每个子空间模型直接嵌入到某个特定的网络层中,所以建立了子空间与相应层语义变化的直接联系。另一方面,在对抗学习的驱动下,生成网络将尽可能地捕捉数据分布的各种主要变化,而这些主要变化将分别根据其语义抽象程度被不同的网络层所表示。而在子空间模型的协助下,某一个特定层所表示的一些主要变化将进一步被正交地分散到不同的基向量中。最终,每一个基向量将成为一个“本征维度”,控制着对应层语义下的某个属性或者某种有含义的变化。该论文从理论上证明:在线性条件下,即单层网络,提出的EigenGAN方法能够和PCA一样学到数据的主成分。此外,从特征流形的角度看,该方法将数据生成的建模分解为多个层次化的维度扩增步骤。



4. Cross-Encoder for Unsupervised Gaze Representation Learning (Yunjia Sun, Jiabei Zeng, Shiguang Shan, Xilin Chen)
为了在没有大量标注数据的情况下进行 3D 视线估计的深度学习,我们提出了无监督学习框架 Cross-Encoder,利用无标签数据来学习视线估计的表示。为了解决视线特征总是与眼睛特征耦合在一起的问题,Cross-Encoder 在“相同眼图像对”和“视线相似图像对”上交换一部分特征,以达到解耦的目的。具体来说,每张图像都会被编码为一个视线特征和一个眼睛特征。Cross-Encoder根据其视线特征和图像对中另一图像的眼睛特征来重构“相同眼图像对”中的每幅图像,而根据眼睛特征和图像对中另一图像的视线特征重构“视线相似图像对”中的每幅图像。实验结果证明了我们工作的有效性。首先,不论是跨数据集,还是在同一数据集内,Cross-Encoder学习的视线表示在使用很少样本训练的情况下,优于其他无监督学习方法。其次,由Cross-Encoder预训练的ResNet18能与目前最好的视线估计方法相匹敌。最后,消融实验表明,Cross-Encoder解耦了视线特征与眼部特征。

5. Env-QA: A Video Question Answering Benchmark for Comprehensive Understanding of Dynamic Environments (Difei Gao, Ruiping Wang, Ziyi Bai, Xilin Chen)
视觉理解的研究不应局限于网络上的图像或视频。人类为了在多变的环境下完成复杂的任务,会深入地了解看到的整个环境,快速感知周围发生的事件,并持续跟踪物体的状态变化。然而,这对当前的AI系统来说仍然是一个巨大的挑战。为了让AI系统能够理解动态环境,本文构建了一个视频问答数据集Env-QA。Env-QA 包含2.3万个第一人称视频,其中每个视频是由一系列环境中的交互事件组成。该数据库还收集了8.5万个问题,从多个角度评测模型对视频所描绘环境的理解,包括环境的组成、布局和状态变化等。此外,本文提出了一种视频问答模型来初步解决该任务。Env-QA的独特挑战在于根据事件链条还原整个环境的信息,那么模型就需要能够提取事件级的视频表示。因此,本文所提出的模型会根据视频的内容划分为多个长度灵活的事件片段,同时提出了相应的事件级注意力机制,实现多步推理并回答问题。进一步,通过与主流视频问答方法的对比实验,验证了所提出问答模型框架的有效性,并发现现有方法在长期状态跟踪、多事件时间推理和事件计数等方面都存在一定的局限性。

图1: Env-QA任务示例
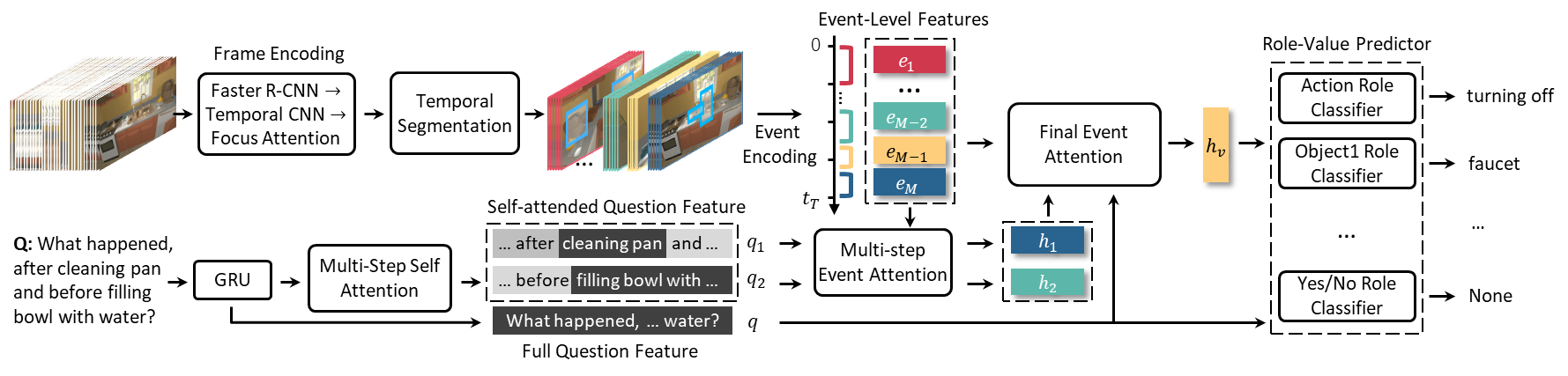
图2: 所提出问答模型的基本框架
6. Topic Scene Graph Generation by Attention Distillation from Caption. (Wenbin Wang, Ruiping Wang, Xilin Chen)
图像文本描述和场景图是刻画图像内容的两种形式,文本描述倾向于优先阐述图像中的核心内容,而场景图侧重于全面细致地反映图像内容。相比较而言,场景图由于其结构化的形式以及更加全面的内容而被广泛应用于下游的检索、推理、语言导航等任务中,但其充斥着平凡的视觉关系,存在大量噪声,这种缺陷也逐渐成为限制其被更广泛应用的障碍。同时,传统的三元组式表达也限制了关系型事件表述的多样性。针对这些挑战,本文汲取图像文本描述的优势,提出了一种新型的主题场景图(Topic Scene Graph),利用图文描述注意力指导场景图中视觉关系重要性排序,收集图文描述生成过程中对于单个物体的注意力信息,进而获得关于视觉关系的注意力信息来作为训练关系重要性排序分数的弱监督信号。在这个过程中,视觉关系和图像文本描述使用一个共享模型生成,使得视觉关系的表达更加自然。实验表明,通过恰当利用注意力信息和使用共享模型,主题场景图能够优先捕获核心关系内容,并且拥有更自然的语言型关系描述,在下游的跨模态图文检索等应用任务上获得更好的性能。

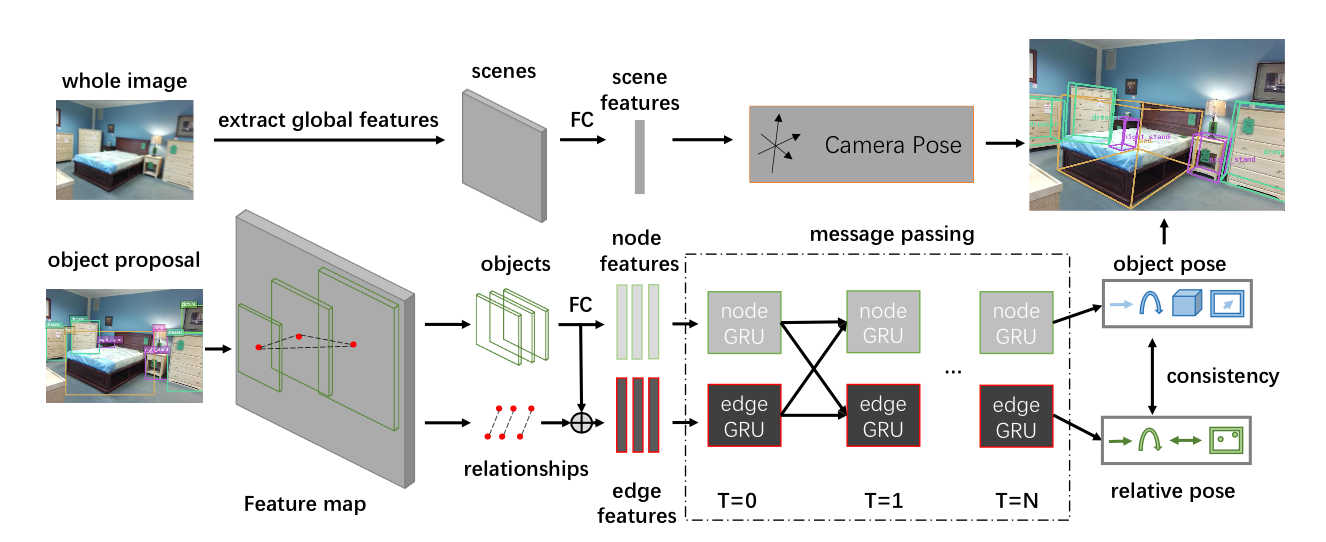
7. Holistic Pose Graph: Modeling Geometric Structure among Objects in a Scene using Graph Inference for 3D Object Prediction. (Jiwei Xiao, Ruiping Wang, Xilin Chen)
8. Visual Alignment Constraint for Continuous Sign Language Recognition (Yuecong Min, Aiming Hao, Xiujuan Chai, Xilin Chen)

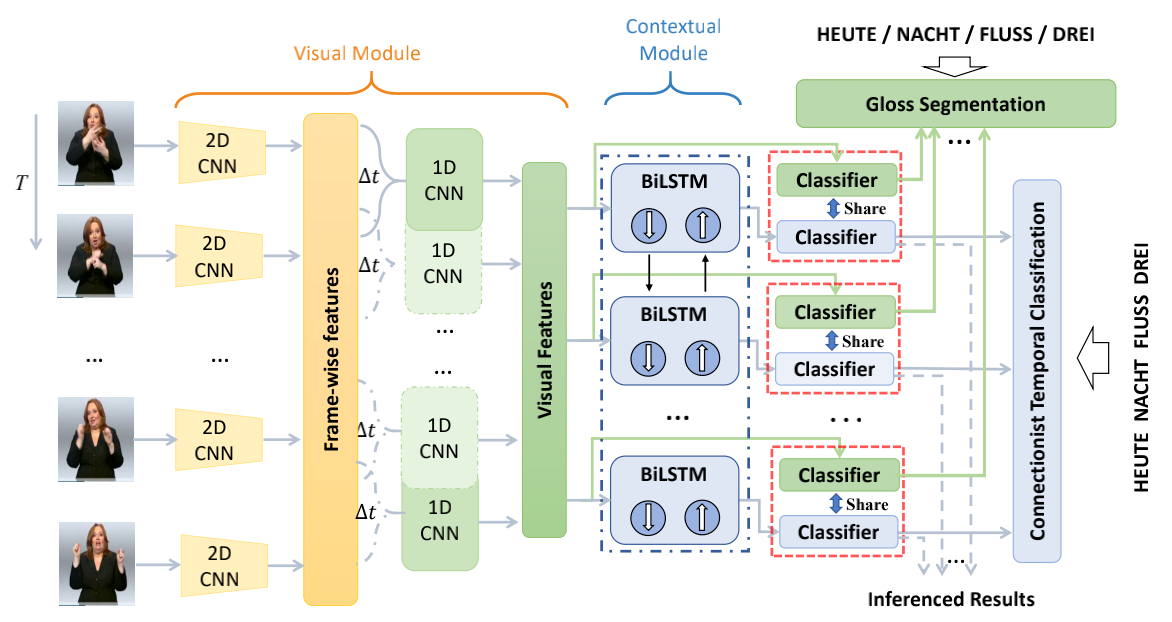
9. Self-Mutual Distillation Learning for Continuous Sign Language Recognition (Aiming Hao, Yuecong Min, Xilin Chen)
近年来,深度学习极大地推进了基于视频的连续手语识别(CSLR)的发展。现阶段,针对CSLR的典型模型由一个视觉模块(visual module)和一个上下文模块(contextual module)构成,并使用CTC损失函数约束模型训练过程。网络中的视觉模块关注空间信息和短期时序信息,而上下文模块则关注长期时序信息。然而,由于反向传播中链式法则的限制,视觉模块很难得到充分的优化以提供更具鲁棒性的特征。这导致了上下文模块只关注上下文信息,而不能很好地平衡视觉和上下文信息。本文提出了一种自相互知识蒸馏(SMKD),通过共享不同模块所对应的分类器,强迫视觉模块和上下文模块同时关注长短期信息,并增强两个模块的判别能力。具体来说,将视觉模块和上下文模块得到的特征同时使用CTC损失进行优化,并共享两个模块对应分类器的权重向量。此外,使用CTC损失进行训练时往往会出现尖峰现象。虽然这一现象能帮助我们选择每个手语词对应的关键帧,但它同时也会忽略掉其他的帧,并使得视觉特征快速饱和。为了更充分地利用视觉信息,本文也为视觉模块设计了一种词分割算法。最后,权重共享的约束将在训练后期解除以减少对上下文模块的约束。本文将上述过程总结为一种三阶段的训练方案来训练所提出的的SMKD方法,同时也在两个CLSR公开数据集上验证了SMKD方法的有效性。
附件下载: