近日,实验室2篇论文被WACV 2022接收。WACV的全称是IEEE Workshop on Applications of Computer Vision,是计算机视觉领域的重要会议。2篇论文的信息概要介绍如下:
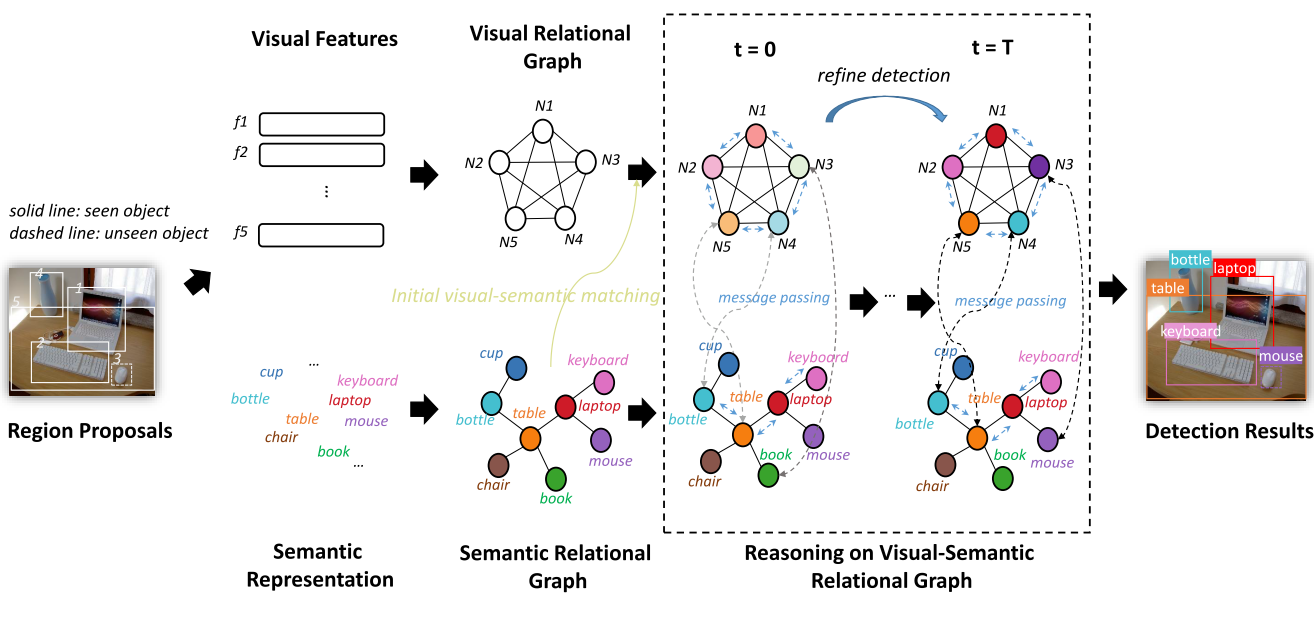
1. From Node to Graph: Joint Reasoning on Visual-Semantic Relational Graph for Zero-Shot Detection. (Hui Nie, Ruiping Wang, Xilin Chen)
零样本检测旨在定位和识别复杂场景中未知的物体,当前方法通常仅利用单个物体的信息。然而,人类对视觉场景的理解超过了单独识别每个物体:多个物体之间的上下文信息,例如视觉关系信息(视觉上相似的物体)和语义关系信息(共生)都是有助于理解视觉场景。本文验证了上下文信息在零样本检测中比在传统物体检测中起着更重要的作用。为了充分利用这些信息,本文提出了一种基于图建模和推理的端到端零样本检测新方法图对齐网络(Graph Aligning Network),它同时考虑多个物体而不是单个物体的视觉和语义信息。具体来说,本文构建了一个视觉关系图和一个语义关系图,其中节点分别是图像中的物体和类别的语义表示,边是每个图中节点之间的相关性。为了表征两种模态之间的相互影响,将这两个图进一步合并成一个异构的视觉语义关系图,其中为这两个子图设计了模态转换器,使模态信息转化到公共空间中用于信息交流,同时让消息在节点之间传递以改进它们的表示。在MSCOCO 数据集上的综合实验验证了本文所提方法优于最先进的方法,定性分析表明使用上下文信息的有效性。
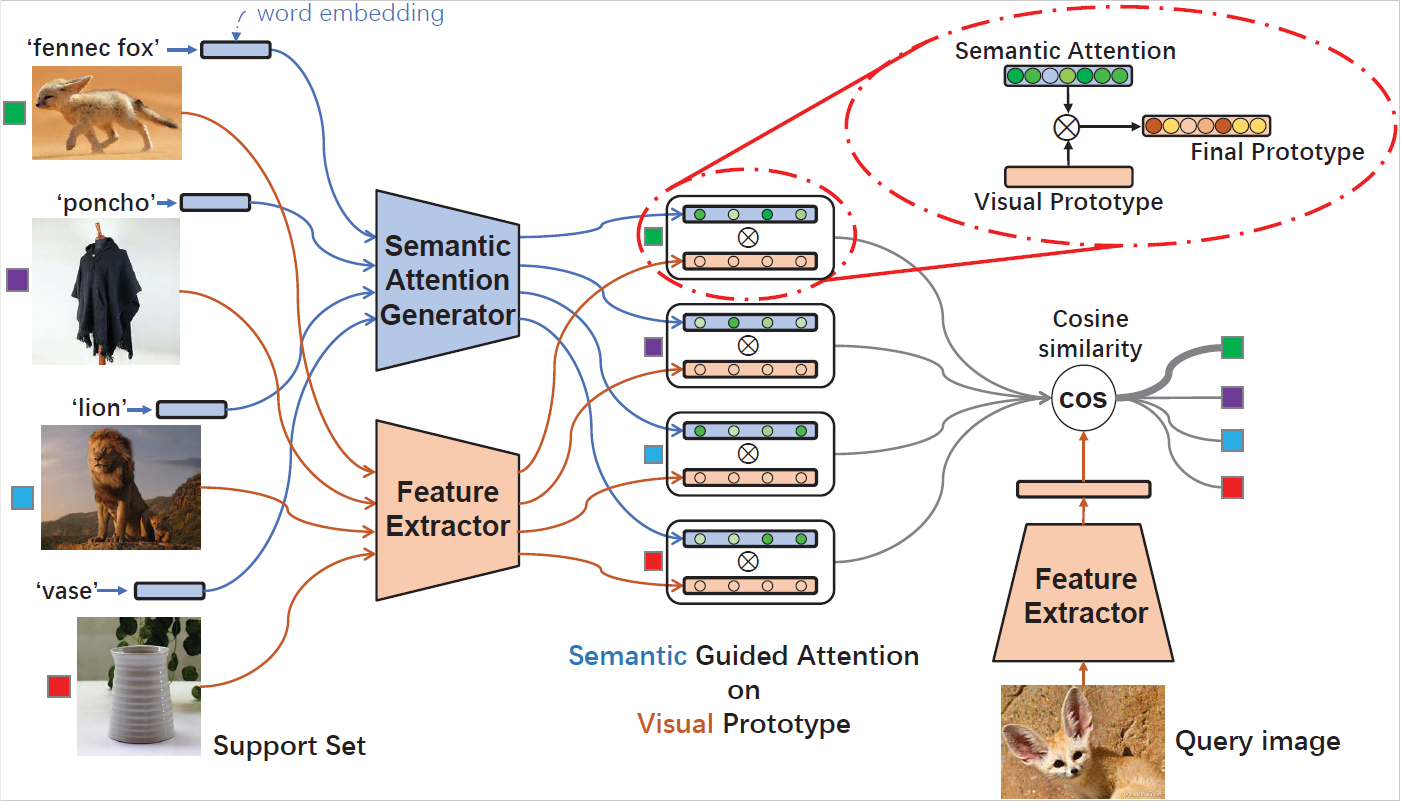
2. SEGA: Semantic Guided Attention on Visual Prototype for Few-Shot Learning. (Fengyuan Yang, Ruiping Wang, Xilin Chen)
小样本学习的核心挑战是由于样本缺乏导致无法对新类别形成全面的理解。而人类却可以基于极少量的样本,甚至是一个样本进行快速的类别学习。其原因在于人类学习新类别过程中利用了视觉先验知识和语义先验知识,从而掌握每个类别区分于其他类别的关键判别性特征。为了像人类一样利用先验知识,本文提出了语义指导的注意力机制(SEmantic Guided Attention, SEGA),利用语义自上而下地指导视觉感知的注意力,即应该关注哪些类别相关的视觉特征维度。具体而言,视觉先验知识的迁移体现在视觉原型的生成迁移了相似基类的视觉原型,而语义先验知识的利用体现在训练从标签语义词向量到注意力向量的映射网络,并用该注意力向量对视觉原型进行特征选择,使之更稳定且更有判别性。实验表明,本文基于语义生成的注意力确实能捕获类别相关的判别性特征维度,并且通过大量可视化实验深入探究了语义指导的注意力到底关注了哪里并尝试分析了背后的原理,同时定量结果也验证了本文方法的优越性。
附件下载: