2024年1月16日,实验室3篇论文被ICLR 2024接收。ICLR会议的全称是International Conference on Learning Representations,是机器学习领域新兴的旗舰国际会议。会议将于2024年5月7日至11日在奥地利首都维也纳召开。
论文简介如下:
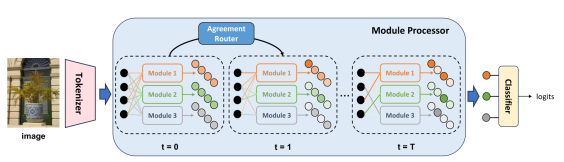
1. Scalable Modular Network: A Framework for Adaptive Learning via Agreement Routing (Minyang Hu, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen)
简介:本文提出了一种新颖的模块化网络框架,称为可扩展模块化网络(SMN),以实现自适应学习能力,并支持在预训练后集成新模块以实现更好的适应性。这种自适应能力来自SMN内的一种新颖的路由器设计,被称为一致性路由器,通过迭代的消息传递过程选择和组合不同的专家模块。一致性路由器通过迭代计算所有模块的一组输入和输出之间的一致性,来将输入有针对性地分配给特定的模块。在迭代路由的过程中,模块之间相互传递消息,同时考虑了局部交互(单个模块和输入之间的交互)和全局交互(涉及多个其他模块)。为了验证本文的贡献,论文在两个问题上进行了实验验证:一个是简单的极小极大游戏,另一个是更真实的少样本图像分类任务。实验结果表明,SMN能够泛化到新的分布,并快速适应新的任务。此外,在引入新模块后,SMN能够更好地适应新的任务。
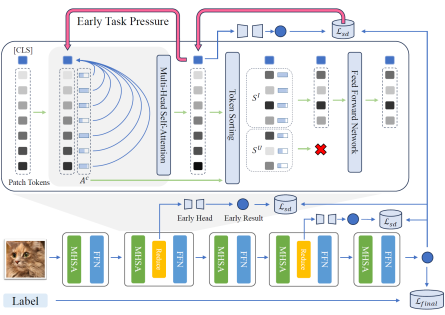
2. A Simple Romance Between Multi-Exit Vision Transformer and Token Reduction (Dongyang Liu, Meina Kan, Shiguang Shan, Xilin Chen)
简介:尽管视觉Transformer结构(ViT)在诸多任务上获得了广泛的成功,其较高的计算成本严重影响了实际应用。Token裁剪是一种有效的ViT加速技术,其通过在前向传播过程中识别并丢弃不重要的Token降低模型的整体计算量。由于Token承担着收集有用信息并形成任务输出的任务,其对剩余Token的注意力分数常被用作Token的重要性度量。然而,Token裁剪在模型较早期就会被运用,而来自任务的压力在整个模型的末尾才被施加,由于中间距离较远,在早期网络层中,Token 很可能缺乏全力收集任务相关信息的动力,导致相对随意的注意力分配。这一现象降低了Token重要性度量的可靠性,严重影响了Token裁剪效果。为了解决该问题,受到动态网络领域多出口结构的启发,我们提出名为METR的多出口加强Token裁剪策略,通过在网络早期引入提前退出头,迫使Token即使在浅层也要全力收集任务相关信息,从而提升其注意力分配和Token重要性之间的一致性。在此基础上,我们引入自蒸馏损失进一步提升模型精度。广泛的实验表明,我们的方法能够稳定且明显地提升模型在Token裁剪后的性能。
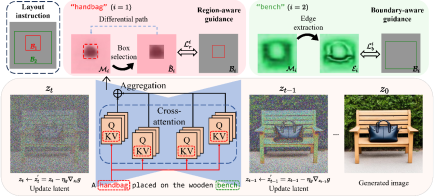
3. R&B: Region and Boundary Aware Zero-shot Grounded Text-to-image Generation (Jiayu Xiao, Henglei Lv, Liang Li, Shuhui Wang, Qingming Huang)
简介: 最近文本到图像(T2I)扩散模型在生成高质量图像方面取得了显著进展。然而,这些模型仍然无法很好地根据一些布局指令生成对应的组合式图片。在这项工作中,我们探索了零样本基于布局指令的文本到图像生成,即在不训练辅助模块或微调扩散模型的情况下生成与输入布局信息相对应的图像。我们提出了一种区域和边界(R&B)感知的交叉注意力引导方法,在生成过程中逐渐调节扩散模型的注意力图,并帮助模型合成具有以下特点的图像:(1)高保真度,(2)与文本输入高度契合,(3)与布局指令吻合。具体而言,我们利用离散采样来弥合连续注意力图和离散布局约束之间的差距,并设计了一个区域感知损失来在扩散过程中优化生成的布局。我们进一步提出了一个边界感知损失,以增强相应区域内的物体判别性。实验结果表明,我们的方法在几个基准测试上在质量和数量上都显著优于现有的零样本基于布局的T2I生成方法。
附件下载: