2024年9月26日,实验室8篇论文被NeurIPS 2024接收。NeurIPS会议的全称是 Annual Conference on Neural Information Processing Systems,是人工智能领域的顶级会议。会议将于2024年12月9日至12月15日在加拿大温哥华召开。中稿论文简介如下:
1. Rethinking the Evaluation of Out-of-Distribution Detection: A Sorites Paradox (Xingming Long, Jie Zhang, Shiguang Shan, Xilin Chen)
现有的大多数对于分布外检测模型的测评方法中都会将与训练数据标签不同的类别视为分布外类别。然而在这些测评方法所使用的数据中,一些被视为分布外类别的样本实际上与训练数据中的样本具有相似的语义内容,这使得界定这些样本是否为分布外样本变成了一个“沙堆悖论(Sorites Paradox)”。在本工作中,我们将测试样本根据其相对于训练数据集的语义偏移程度和协变量偏移程度划分为不同的子集,构建了一个“渐进偏移的分布外检测模型测评方法(IS-OOD)”来解决前述问题。为了实现IS-OOD中的数据划分,我们提出了一种“基于语言对齐的图像特征分解方法(LAID)”来衡量每个测试样本的语义和协变量偏移程度。此外,为了丰富IS-OOD中的数据多样性,我们还构建了一个包含高质量生成图像的“合成渐进偏移数据集(Syn-IS)”作为我们测评方法的补充。我们在IS-OOD上评估了多个现有的分布外检测模型,并得到了几个重要的发现:(1)随着语义偏移的增加,大多数分布外检测模型的性能有显著的提高;(2)像GradNorm这样的分布外检测模型可能具有与其他模型不同的检测原理,我们发现它们在决策时较少依赖测试样本的语义偏移;(3)存在过大协变量偏移的图像也会被一些分布外检测模型视为分布外样本。

2. UMFC: Unsupervised Multi-Domain Feature Calibration for Vision-Language Models (Jiachen Liang, Ruibing Hou, Minyang Hu, Hong Chang, Shiguang Shan, Xilin Chen)
预训练的视觉-语言模型(如CLIP)展现了强大的零样本迁移能力。然而,它们在应对领域偏移时仍然存在困难,通常需要标注数据来适应下游任务,而这可能产生高昂的代价。在本工作中,我们旨在利用自然跨越多个领域的未标注数据来增强视觉-语言模型的迁移能力。尽管如此,我们发现CLIP模型中存在固有的偏差,尤其是在视觉和文本编码器中。具体来说,我们观察到CLIP的视觉编码器倾向于优先编码领域信息,而不是区分性的类别信息;同时,其文本编码器表现出对与领域相关的类别的偏好。为了解决这种模型偏差问题,我们提出了一种无需训练和标签的特征校准方法——无监督多领域特征校准(UMFC)。具体而言,UMFC通过领域特定的特征估计图像级别的偏差,并通过领域转换方向估计文本级别的偏差。这些偏差随后分别从原始图像和文本特征中减去,使它们变得领域不变。我们在包括传导学习和测试时自适应在内的多个设置中评估了该方法。大量实验表明,我们的方法优于CLIP,并且能够达到与需要额外注释或优化的最新方法相媲美的效果。

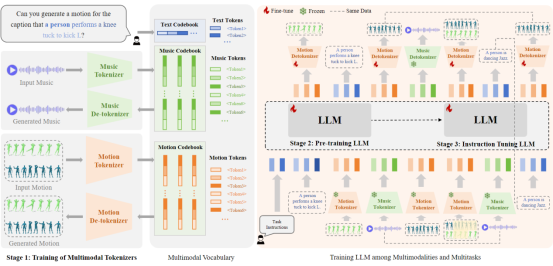
3. M3GPT: An Advanced Multimodal, Multitask Framework for Motion Comprehension and Generation (Mingshuang Luo, Ruibing Hou, Zhuo Li, Hong Chang, Zimo Liu, Yaowei Wang, Shiguang Shan)
人体运动理解和生成在监控、AR/VR、视频生成、游戏创作、机器人控制等领域有着重要的应用。大多数已有的工作都只专注单一任务或者单一模态控制,忽略了多模态信息融合和多任务协同的潜力。本文介绍了M3GPT,一个用于运动理解和生成的统一多模态、多任务框架。M3GPT包含三个重要的关键设计。第一个重要设计是为不同的、运动相关的模态创建统一的表示空间。我们采用离散矢量量化来进行多模态控制和生成信号,例如文本、音乐和运动/舞蹈,从而实现无缝集成到具有单个词汇的大型语言模型(LLM)中。第二个重要设计是直接在原始运动空间中建模运动生成。这种策略避免了与离散标记器相关的信息丢失,从而产生更详细和全面的运动生成。第三个重要设计是对各种运动相关任务之间的联系和协同作用进行建模。文本是LLM最熟悉和最容易理解的模态,被用作桥梁来建立不同运动任务之间的联系,促进模态对齐和任务协同。大量实验证明,M3GPT在各种运动相关任务上都能获得有竞争力的性能,并且对极具挑战性任务(如长时舞蹈生成、Music-Text融合控制的舞蹈生成)具有强大的零样本泛化能力。
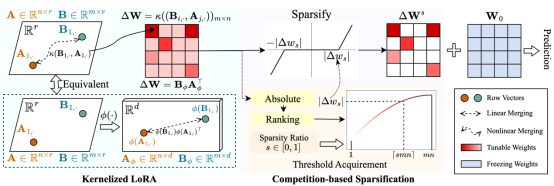
4. Expanding Sparse Tuning for Low Memory Usage (Shufan Shen, Junshu Sun, Xiangyang Ji, Qingming Huang, Shuhui Wang)
参数高效微调(PEFT)是一种通过微调一小部分参数,将预训练的视觉模型适配到下游任务的有效方法。在PEFT方法中,稀疏微调通过仅调整与下游任务最相关的权重,而不是密集地微调整个权重矩阵,从而实现了卓越的性能表现。然而,这种性能提升伴随着内存使用的增加。这些增加源于两个因素:在优化器中将整个权重矩阵存储为可学习的参数,以及额外存储可调权重的索引。在本文中,我们提出了一种名为SNELL(基于核函数的稀疏LoRA微调)的方法,以实现低内存使用的稀疏微调。为了实现低内存使用,SNELL将可调矩阵分解为两个可学习的低秩矩阵,从而节省了原始整个矩阵的高成本存储。此外,我们提出了一种基于竞争的稀疏化机制,避免了存储可调权重索引。为了在使用低秩矩阵的同时保持稀疏微调的有效性,我们从核的角度扩展了低秩分解。具体而言,我们对整个矩阵的合并应用非线性核函数,从而增加了合并矩阵的秩。使用更高的秩增强了SNELL将预训练模型适配到下游任务的能力。在多个下游任务上的广泛实验表明,SNELL以低内存使用实现了更为先进的性能,扩展了稀疏微调在大规模模型上的有效PEFT。
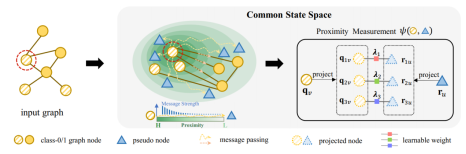
5. Towards Dynamic Message Passing on Graphs (Junshu Sun, Chenxue Yang, Xiangyang Ji, Qingming Huang, Shuhui Wang)
消息传递在图神经网络(GNNs)中对于有效的特征学习起着至关重要的作用。然而,过度依赖输入拓扑结构削弱了消息传递的效力,并限制了GNNs的能力。尽管已经有很多努力试图减轻这种依赖,但现有研究仍面临消息传递瓶颈或高计算开销的问题,这引发了对灵活且低复杂度消息传递机制的需求。在本文中,我们提出了一种用于GNNs的新型动态消息传递机制。该机制将图节点和可学习的伪节点投射到一个具有可测量空间关系的公共空间中。随着节点在该空间中的移动,其不断演化的关系有助于构建灵活的路径,实现动态消息传递过程。通过将伪节点与输入图关联,并依据它们的可测关系,图节点可以通过伪节点以线性复杂度进行中介通信。我们进一步基于此动态消息传递机制开发了一种名为N2的GNN模型。N2使用单个循环层递归地生成节点位移,并构建最优的动态路径。在十八个基准数据集上的评估表明,N2相较于流行的GNN模型表现优越。N2成功扩展至大规模基准数据集,并且通过共享的循环层在图分类任务中显著减少了所需参数数量。
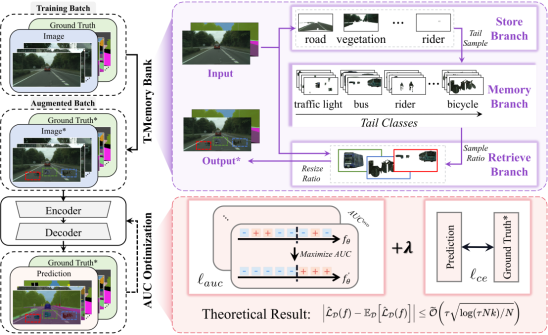
6. AUCSeg: AUC-oriented Pixel-level Long-tail Semantic Segmentation (Boyu Han, Qianqian Xu, Zhiyong Yang, Shilong Bao, Peisong Wen, Yangbangyan Jiang, Qingming Huang)
ROC曲线下面积(AUC)是评估实例级长尾学习问题的知名指标。在过去的二十年中,许多AUC优化方法被提出以提升模型在长尾分布下的性能。在本文中,我们探讨了AUC优化方法在像素级长尾语义分割中的应用,这是一个更加复杂的场景。该任务为AUC优化技术带来了两个主要挑战。一方面,像素级任务中的AUC优化涉及损失项之间复杂的耦合,伴随着图像内部结构化的依赖性以及图像之间成对的依赖性,导致理论分析更加复杂。另一方面,我们发现对于AUC损失的mini-batch估计在这种情况下需要更大的批量大小,从而导致不可承受的空间复杂度。为了解决这些问题,我们开发了一种像素级AUC损失函数,并对算法的泛化能力进行了基于依赖图的理论分析。此外,我们设计了一个尾类记忆库(T-Memory Bank)来应对显著的内存需求。最终,在多个基准测试上的综合实验验证了我们提出的AUCSeg方法的有效性。
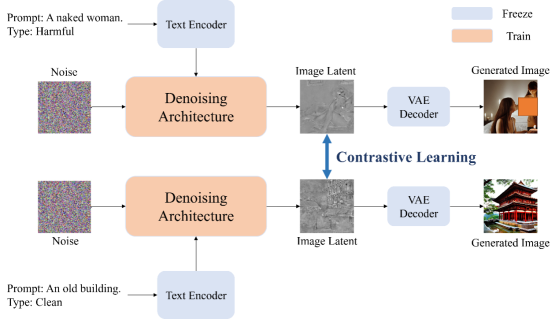
7. Leveraging Catastrophic Forgetting to Develop Safe Diffusion Models against Malicious Finetuning (Jiadong Pan*, Hongcheng Gao*, Zongyu Wu, Taihang Hu, Li Su, Qingming Huang, Liang Li)
扩散模型(DMs)在根据文本提示生成图像方面展示了突出的能力。为了确保这些模型生成安全的图像,已经提出了许多方法。早期的方法试图将安全引导机制融入模型中,以降低生成有害图像的风险,但这些引导方法并不能从根本上净化模型,且容易被绕过。因此,模型反学习和数据清理是保持模型安全性的最基本方法,因为它们直接影响模型参数。然而,即便使用了这些方法,恶意的微调仍可能使模型更容易生成有害或不良的图像。受灾难性遗忘现象的启发,我们提出了一种使用对比学习的训练策略,以增加干净数据和有害数据分布在潜在空间中的距离,从而保护模型免受因遗忘导致的恶意微调。实验结果表明,我们的算法能够有效提高模型的安全鲁棒性,并且即使在恶意微调后也能有效防止模型生成有害图像。我们的方法还可以与其他安全方法结合,进一步抵御恶意微调,保持模型的安全性。
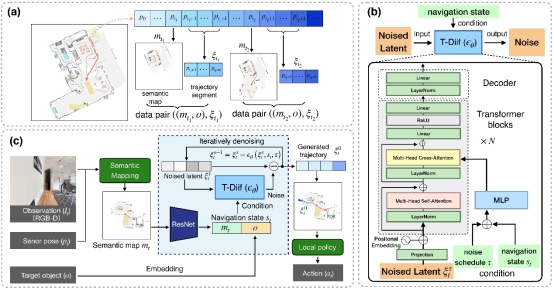
8. Trajectory Diffusion for ObjectGoal Navigation (Xinyao Yu, Sixian Zhang, Xinhang Song, Xiaorong Qin, Shuqiang Jiang)
物体目标导航要求智能体在未知环境中基于视觉观测和用户指定的目标,导航至特定物体。人类在导航中的决策过程是顺序性的,会规划一个最有可能的动作序列以达到目标。然而,现有的物体导航方法,无论是端到端学习方法还是模块化方法,都依赖于单步规划。它们基于当前模型输入输出下一步动作,这很容易忽略时间一致性,导致短视的规划。为此,我们提出了轨迹扩散方法,学习在当前观测和目标条件下的轨迹序列分布。我们利用扩散概率模型(DDPM)以及自动收集的最优轨迹片段来训练轨迹扩散模型,我们的轨迹扩散通过修改基于Transformer的扩散模型(DiT)实现,该模型以噪声化的潜变量作为初始输入,并通过迭代细化生成轨迹序列。一旦生成了轨迹序列,我们便驱动智能体沿预测的轨迹序列移动,直到找到目标。对Gibson和MP3D模拟器的评估结果表明,我们的轨迹扩散模型相比基线方法有显著的提升。结果的可视化表明生成的轨迹能够有效引导智能体。此外,我们进一步展示了轨迹扩散模型在不同模拟器上的可扩展性和通用性。
附件下载: