2026年4月,实验室有2篇论文被ACL 2026录用。ACL 2026的全称是The 64nd Annual Meeting of the Association for Computational Linguistics,将于2026年7月2-7日在美国加利福利亚圣迭戈举行。
被录用论文简介如下:
- From Prediction to Intervention: Personalized Meal-Level Glucose Regulation via an LLM Agent (Mingyu Huang, Weiqing Min, Ying Jin, Yilin Wang, Shuqiang Jiang)
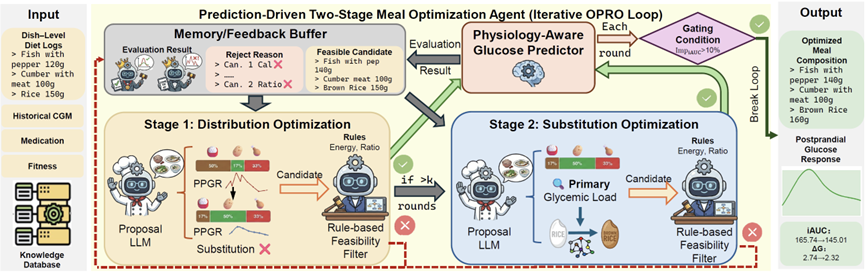
个性化血糖调控是精准营养领域中一个核心但尚未解决的问题,其难点在于餐后血糖反应(PPGR)在不同个体之间表现出显著差异。传统干预方法多依赖于升糖指数(GI),难以充分刻画这种个体间异质性,也缺乏依据个体生理反馈动态调整膳食的机制。相比之下,基于大语言模型的智能体(LLM Agent)凭借其上下文感知推理与迭代优化能力,在类似任务中展现出良好潜力。受此启发,本研究提出了一套闭环、生理反馈驱动的智能体系统,将个性化PPGR建模与膳食干预统一于同一框架中,以实现对PPGR的有效调控。具体而言,本研究构建了一个具备生理感知能力的PPGR预测模型,通过可学习的时序生理吸收衰减模块,对个体肠道吸收动力学进行建模。在此基础上,本研究进一步设计了一个预测结果驱动的膳食优化智能体,该智能体以PPGR预测结果为显式反馈,对真实餐食组合进行迭代优化。在多个公开数据集上的实验以及与基线方法的对比表明,本方法不仅能提升血糖预测精度,还能显著降低血糖波动幅度。
- INFACT: A Diagnostic Benchmark for Induced Faithfulness and Factuality Hallucinations in Video-LLMs (Junqi Yang, Yuecong Min, Jie Zhang, Shiguang Shan, Xilin Chen)
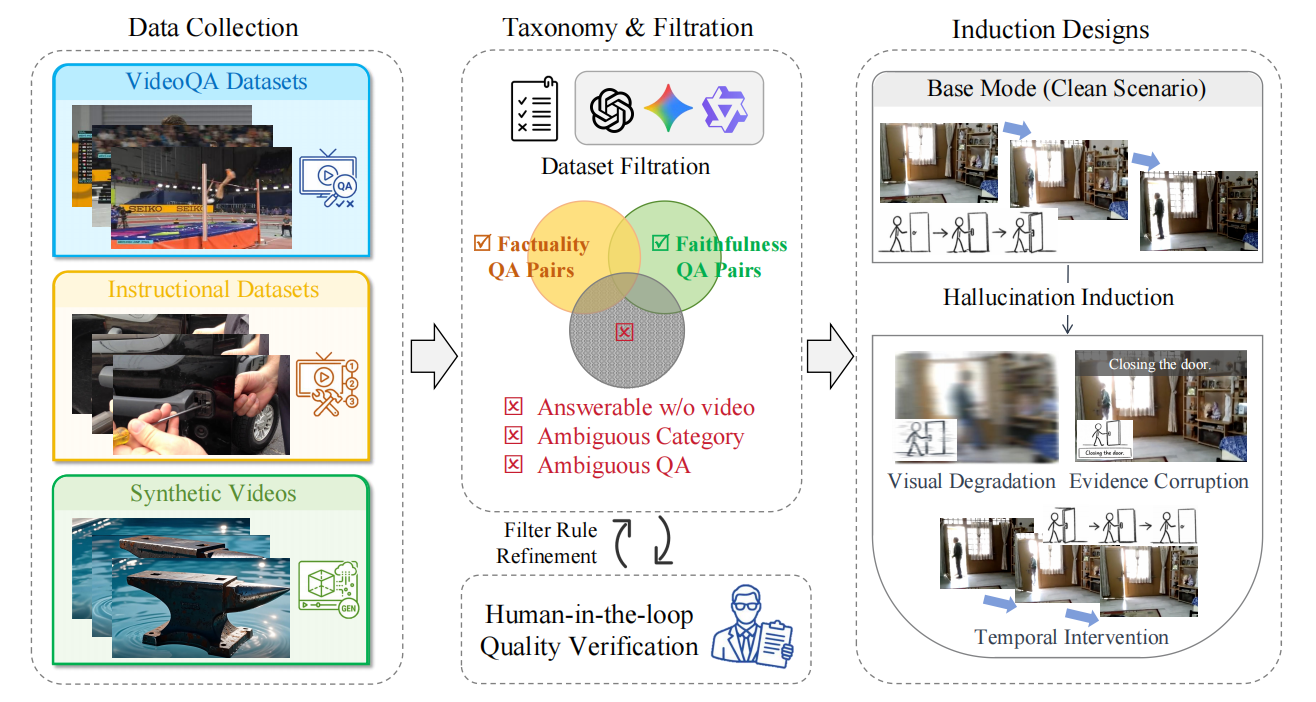
视频大语言模型(Video-LLMs)尽管进展迅速,但仍面临幻觉问题——生成与视频证据矛盾的内容(忠实性幻觉)或与可验证世界知识矛盾的内容(事实性幻觉)。现有基准主要关注忠实性幻觉且仅在干净场景下评测,对事实性幻觉覆盖不足,也无法揭示模型在受干扰条件下的可靠性。为此,本文提出INFACT,一个包含9,800个QA实例的诊断性基准,建立了忠实性(3层12类)和事实性(3类12子类)的细粒度分类体系,涵盖真实视频与合成视频。INFACT设计了四种评测模式:基准模式、视觉退化、证据污染和时序干预,并引入抵抗率(RR)和时序敏感度(TSS)两项可靠性指标。对14个代表性Video-LLMs的实验表明:(1)基准模式下的高准确率并不能可靠地转化为干扰模式下的高可靠性;(2)证据污染比视觉退化对模型稳定性的破坏更大;(3)许多开源模型在事实性问题上的TSS接近零,表现出显著的时序惰性,即在时序结构被破坏后仍坚持原始预测,暴露了模型依赖静态先验而非真正的时序推理。
【论文链接】https://arxiv.org/pdf/2603.11481
附件下载: