At the beginning of the new semester, CVPR2018 published the results of the received paper. Congratulations, there are VIPL's four papers, covering those topics of face detection, domain adaptation, age estimation and object detection. CVPR 2018 will be held in Salt Lake City, USA, in June 2018.
The recieved four papers are summarized as follows:
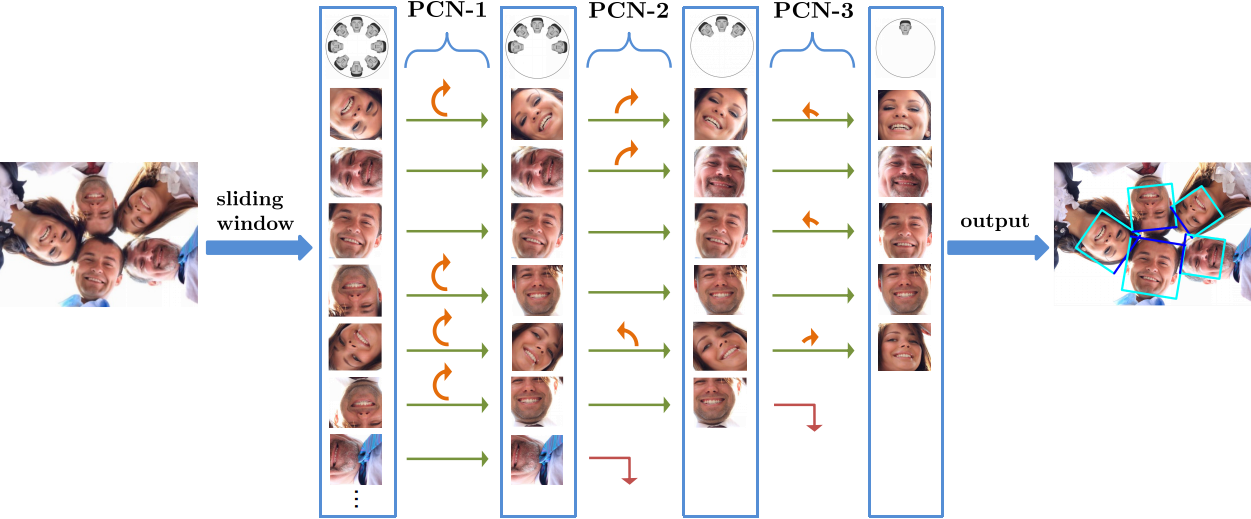
1.Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks ( Xuepeng Shi, Shiguang Shan, Meina Kan, Shuzhe Wu, Xilin Chen )
In real and complex scenes, such as sports broadcast and family photo, face may have arbitrary in-plane rotation angle due to the influence of human posture and view angle, which brings great challenges to face detection. In order to solve the challenge of face detection in 360 °plane rotation, we propose a method of cascade-based rectifying network. Each level of the network simultaneously filters the non-face window and corrects the orientation of face rotation. In order to ensure the accuracy and speed of the correction, the first few levels of the network only carry out rough orientation classification. The method of gradually correcting and reducing the appearance change of human face can significantly improve the detection accuracy. The method has the advantages of high speed, small model and high precision, so it has a good application prospect.
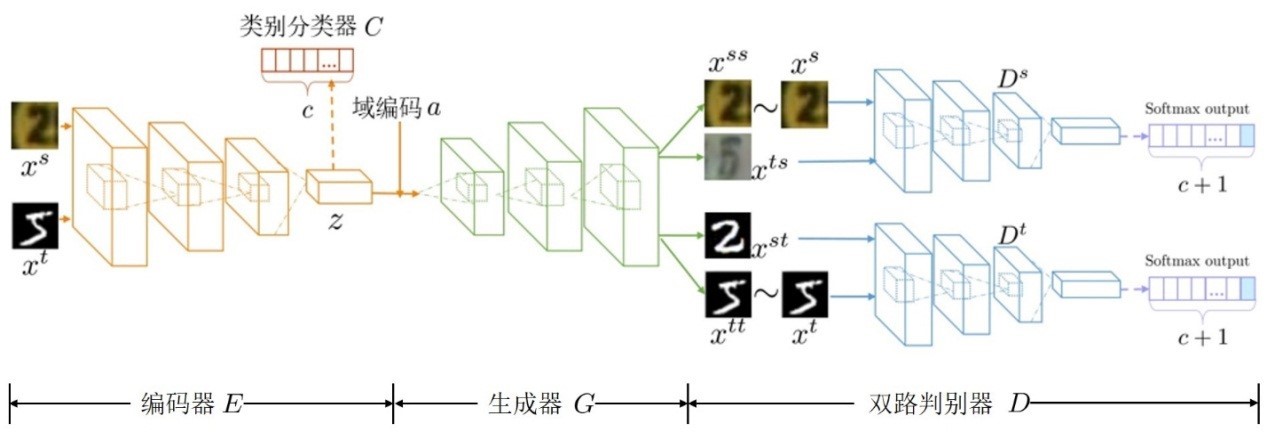
2. Duplex Generative Adversarial Network for Unsupervised Domain Adaptation ( Lanqing Hu, Meina Kan, Shiguang Shan, Xilin Chen )
In order to solve the problem of unsupervised domain adaptation, we propose a two-stream confrontation generation method (DupGAN). In this method, a large amount of labeled sample knowledge (called source domain) is transferred to a set of unlabeled samples with the same target task (called target domain) in the way of generating antagonistic network (GAN). Specifically, DupGAN uses an encoder to extract features, a generator decodes the features obtained by the encoder into a source-domain or target-domain style image based on a domain code, and two discriminators confront the generator to train and constrain the specific categories of the samples. Thus, the encoder learns that the feature is domain independent and has class information, and achieves the best performance on the domain adaptive correlation test set at present.
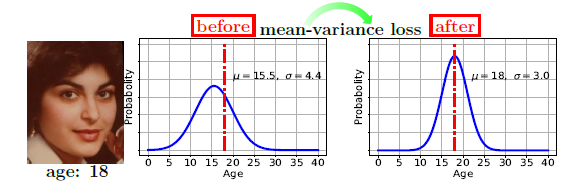
3. Mean-variance Loss for Deep Age Estimation from A Face (Hongyu Pan, Hu Han, Shiguang Shan, Xilin Chen )
Label distribution learning is an effective label representation method in ordinal attribute learning, which represents ordinal attribute as probability distribution of attribute label space (such as Gao Si distribution) rather than a single value.The traditional attribute estimation based on label distribution learning depends on the mean and variance of manually provided or assumed label distribution, and its application scope is limited. We propose a new loss function (mean-variance loss) for age estimation based on distributed learning. We incorporate the mean and variance of the estimated attribute label distribution into the loss calculation process. The mean value of the estimated age distribution is closer to the true age value, and the variance of the age distribution is as small as possible (not required to be close to the variance of the training set data). The proposed method does not need to artificially provide or assume the label distribution of the training set data, so it can be extended to a wider range of ordinal attribute learning scenarios. Experiments on the current mainstream age estimation databases (MORPH, FG-NET and CLAP2016) show that the proposed age estimation method is far superior to the current best method. In addition, we apply this method to the problem of the aesthetic evaluation of pictures, and obtain the performance similar to that of the best methods in the case of using less information.
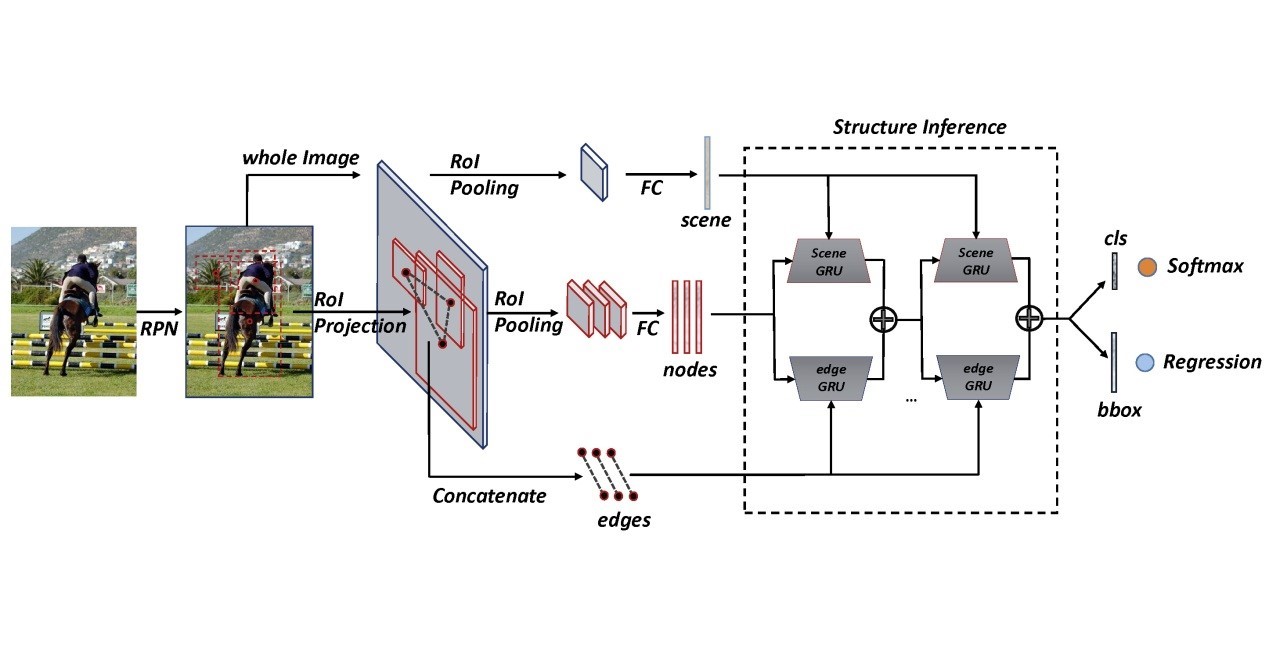
4. Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships ( Yong Liu, Ruiping Wang, Shiguang Shan, Xilin Chen )
Scene context is very important for accurate object detection, which has been explored in the early research. In recent years, with the rise of in-depth learning methods such as Faster RCNN, in the context of increasing emphasis on data and performance, the use of context-related information is rarely tried. In this paper, a structural inference network (Structure Inference Net, called SIN), formalizes the problem of object detection into graph structure reasoning. The graph structure is used to model the detail features of objects, the context of scene, and the relationships between objects. The message passing mechanism of gated loop unit (GRU) is used to reason the categories and positions of objects in the image. Experiments on benchmark data sets PASCAL VOC and MS COCO demonstrate the effectiveness of the proposed method in precision enhancement, and that context information is helpful for outputting detection results that are more in line with human perception.
Download: