Recently, VIPL's paper on the visual question answering task was accepted by the journal IEEE JSTSP. The full name of IEEE JSTSP is IEEE Journal of Selected Topics in Signal Processing, with an impact factor of 6.69 in recent years. The paper information is as follows:
Learning to Recognize Visual Concepts for Visual Question Answering with Structural Label Space (Difei Gao, Ruiping Wang, Shiguang Shan, and Xilin Chen)
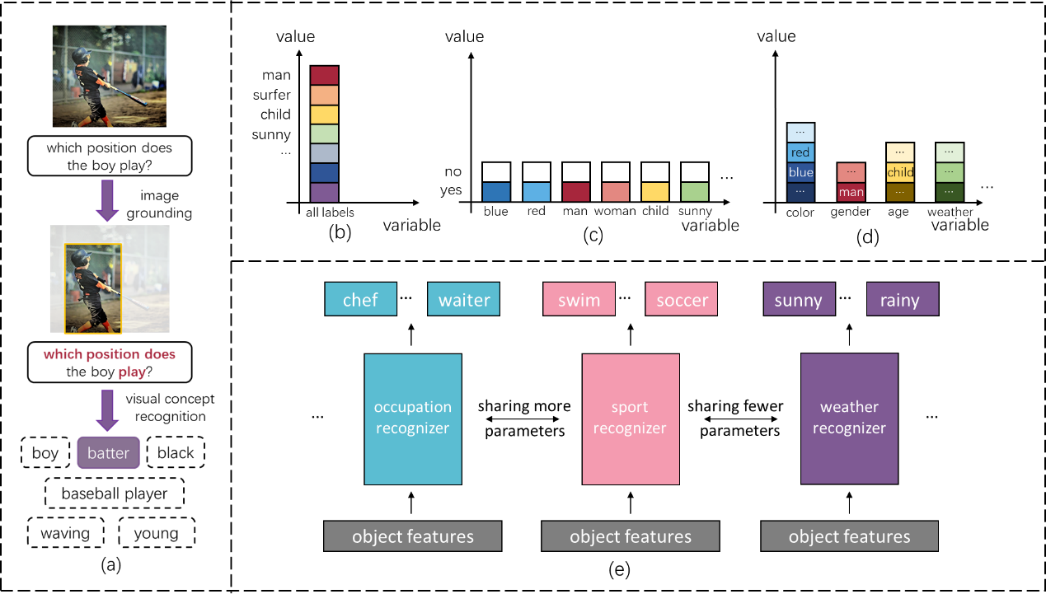
In recent years, cognitive tasks have received more and more attention. One of the important directions is the research of visual question answering (VQA). Compared to perception tasks, such as object classification, the visual question answering task is no longer limited to classifying a single type of concepts, but requires the model to master more comprehensive visual knowledge, including object types, attributes, human actions, etc., to deal with various question, as shown in (a). Therefore, the concepts required for the VQA task contain richer semantic information. For example, some concepts are extremely related (e.g., red and blue), and some concepts are less relevant (e.g., red and standing). When learning these diverse concepts, humans will naturally use semantic information to learn related concepts together, to eliminate the interference of unrelated concepts, and to improve learning efficiency. However, previous works usually use a simple MLP to output visual concept as the answer in a flat label space as the answer that treats all labels equally, causing limitations in representing
and using the semantic meanings of labels. To address this issue, we propose a novel visual recognition module named Dynamic Concept Recognizer (DCR), which is easy to be plugged in an attention-based VQA model, to utilize the semantics of the labels in answer prediction. Concretely, we introduce two key features in DCR: 1) we introduce a novel structural label space to depict the difference of semantics between concepts, where the labels in new label space are assigned to different groups according to their meanings. This type of semantic information helps decompose the visual recognizer in VQA into multiple specialized sub-recognizers to improve the capacity and efficiency of the recognizer. 2) We introduce a feature attention mechanism to capture the similarity between relevant groups of concepts, e.g., human-related group “chef, waiter” is more related to “swimming, running, etc.” than scene related group “sunny, rainy, etc.”. This type of semantic information helps sub-recognizers for relevant groups to adaptively share part of modules and to share the knowledge between relevant sub-recognizers to facilitate the learning procedure. Extensive experiments on several datasets have shown that the proposed structural label space and DCR module can efficiently learn the visual concept recognition and benefit the performance of the VQA model.