Congratulations! VIPL's 6 papers are accepted by ACM MM 2021! ACM MM is the premier international conference in multimedia. ACM MM 2021 will be held in October 2021 in Chengdu, China. The 6 papers are summarized as follows (in the order of title):
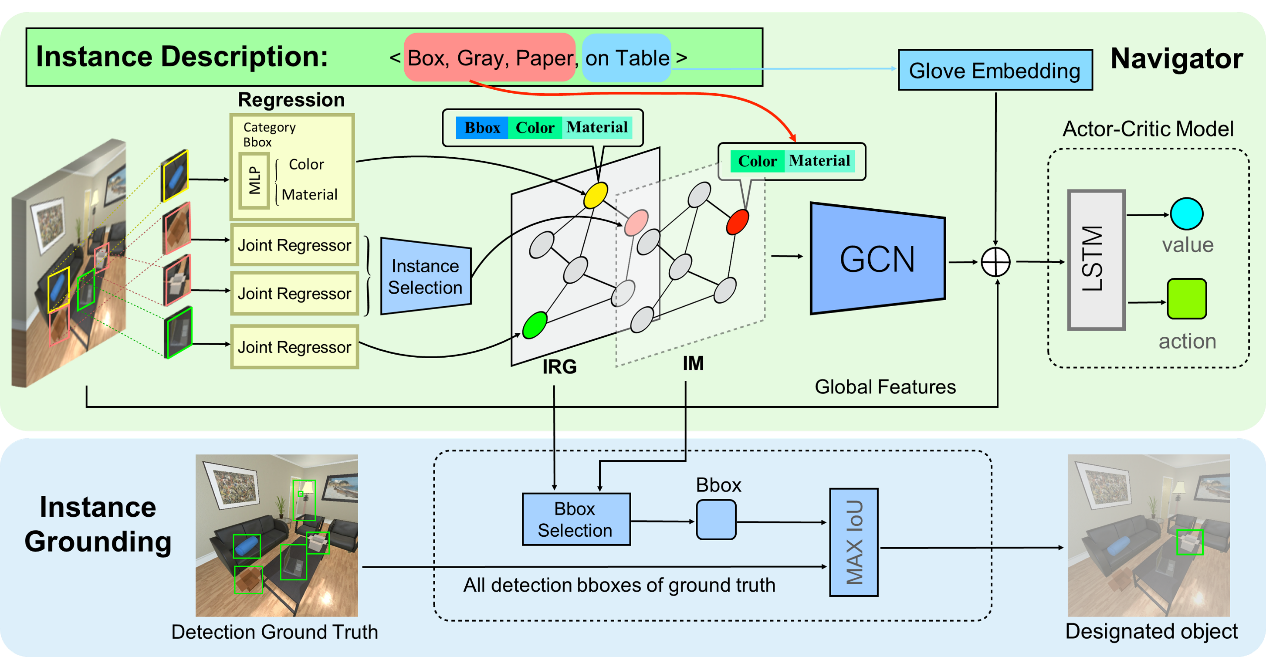
1. ION: Instance-level Object Navigation (Weijie Li, Xinhang Song, Yubing Bai, Sixian Zhang, Shuqiang Jiang)
Visual object navigation is a fundamental task in Embodied AI. Previous works focus on the category-wise navigation, in which navigating to any possible instance of target object category is considered a success. However, it may be more practical to navigate to the specific instance in our real life, since our particular requirements are usually satisfied with specific instances rather than all instances of one category. For instance, if our requirement is “drinking water”, then our real goal is to let the agent to find our own “cup”, not any cups belonging to other people. In this paper, we introduce a new task of Instance Object Navigation (ION) and propose a cascade framework with Instance-Relation Graph (IRG) based navigator and instance grounding module. In particular, multiple types of attributes such as colors, materials and object references are involved in the instance-level descriptions of the targets. In order to specify the different instances of the same object categories, we construct instance-level graph instead of category-level one, where instances are regarded as nodes, consisting of the representation of colors, materials and locations (bounding boxes). During navigation, the detected instances can activate corresponding nodes in IRG, which are updated with graph convolutional neural network (GCNN). The final instance prediction is obtained with the grounding module by selecting the candidates (instances) with maximum probability. For the task evaluation, we build a benchmark for instance-level object navigation on AI2-Thor simulator, where over 27,735 object instance descriptions and navigation groundtruth are automatically obtained with the interaction to the simulator. The proposed model outperforms the baseline by a large margin in instance-level metrics, showing that our proposed graph model can guide instance object navigation, as well as leaving a promising room for further improvement.
2. Learning Meta-path-aware Embeddings for Recommender Systems (Qianxiu Hao, Qianqian Xu, Zhiyong Yang, Qingming Huang)
The sparsity issue for user-item interactions commonly exists in real-world recommender systems. To tackle this issue, many existing works resort to meta-paths to enhance the recommender system. However, existing meta-path-based recommendation methods merely adopt simple meta-path fusion rules or shallow/stage-wise formulations, whose representative power is limited. To solve these issues, we propose a flexible fusion module and an end-to-end meta-path-aware embedding-based recommendation framework. Specifically, the flexible fusion module utilizes deep networks to integrate meta-path-based similarities into relative attentions between users and items. On top of the attention, we take advantage of the powerful graph neural networks to learn more complicated and flexible user/item embeddings. Finally, a recommender module predicts the user preference based on the user/item embeddings. Empirical studies on real-world datasets demonstrate the superiority of our proposed method.

3. Multimodal Entity Linking: A New Dataset and A Baseline (Jingru Gan, Jinchang Luo, Haiwei Wang, Shuhui Wang, Wei He, Qingming Huang)
We introduce a new Multimodal Entity Linking (MEL) task, to discover the linking of entities in multiple modalities on largescale multimodal data. Derived from the vanilla neural entity linking (NEL), MEL maps mentions in a multimodal documents with entities in a structured knowledge base. Different from NEL that focuses on textual information solely, MEL tackles object-level disambiguation among images, texts, and knowledge bases. Due to the lack of labeled data in this field, we release the first multimodal entity linking dataset M3EL. We collect movie reviews and images of 1,100 movies from IMDB, extract textual and visual mentions, and label them with entities registered in Wikipedia. We also propose a new baseline method of MEL task, which models the alignment of textual and visual mentions as a bipartite matching problem and solves it with an optimal-transport based linking method. We perform extensive experiments on our M3EL dataset to demonstrate the quality of our labeled data and the effectivity of the proposed baseline method as well. By introducing a new dataset and a baseline to the MEL problem, we envision this work to be helpful for soliciting more researches and applications regarding this intriguing new task in the future.
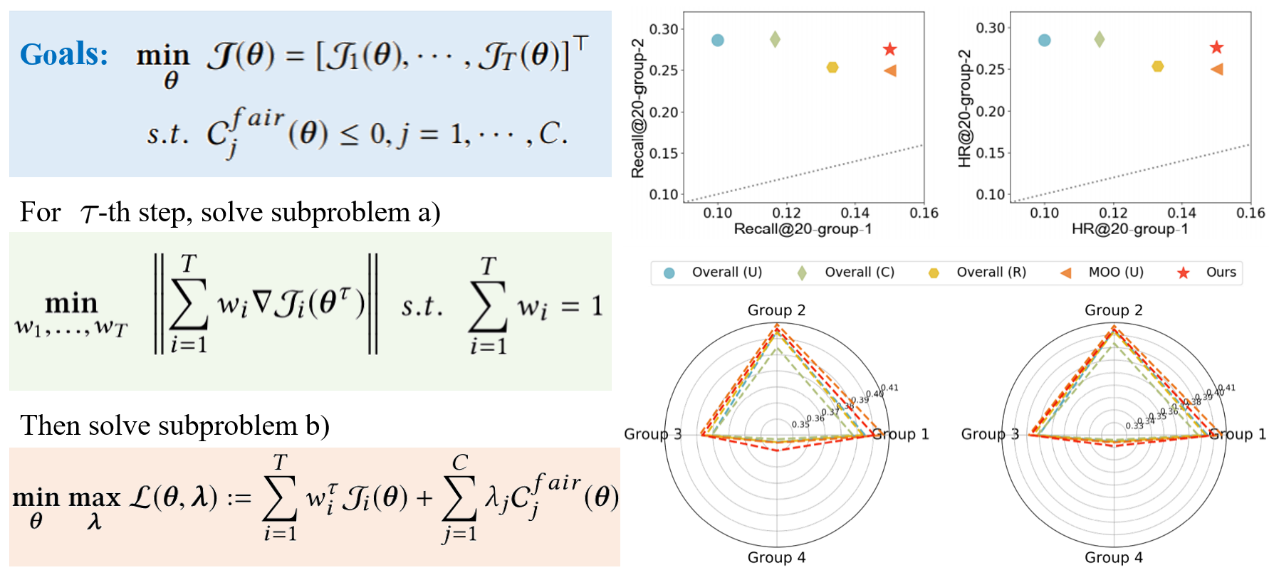
4. Pareto Optimality for Fairness-constrained Collaborative Filtering (Qianxiu Hao, Qianqian Xu, Zhiyong Yang, Qingming Huang)
Collaborative filtering methods learn users’ preferences towards items based on the users’ historical records. Due to inevitable imbalances and biases in real-world data, the traditional optimization scheme that optimizes the sum of all user-item interactions might lead to insufficient training for users with fewer interactions. Thus, they may develop a policy that unfairly discriminates against some disadvantaged subgroups. To tackle this problem, we propose a fairness constraint to limit the search space of parameters and formulate the underlying problem as a constrained Multi-Objective Optimization (MOO) problem. Besides the fairness constraint, the performance of each subgroup is treated equivalently as an objective. This ensures that the imbalanced subgroup sample frequency does not affect the gradient information. To solve this problem, a gradient-based constrained MOO algorithm is proposed to seek a proper Pareto optimal solution for the performance trade-off. Extensive experiments on synthetic and real-world datasets show that our approach could help improve the recommendation accuracy of disadvantaged groups thus while not damaging the overall performance much.
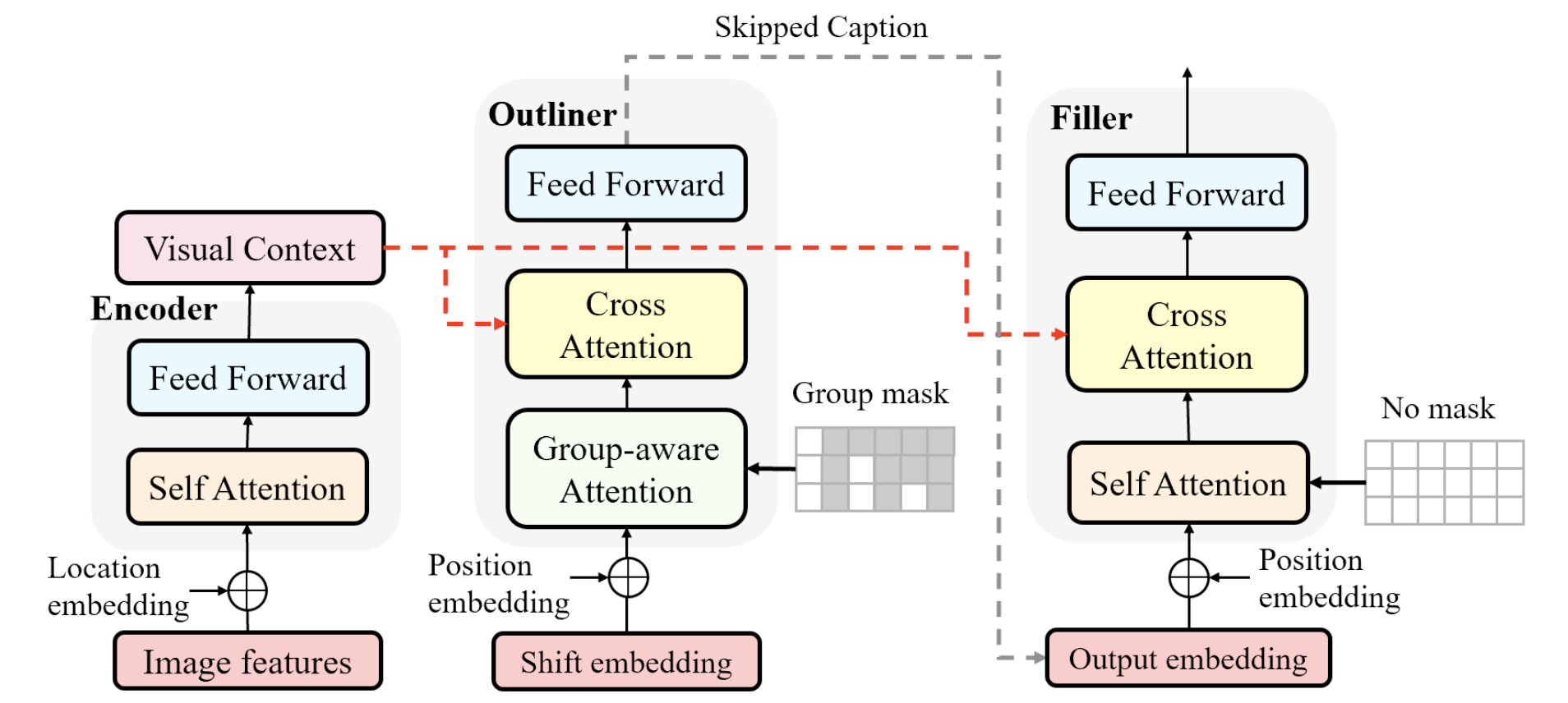
5. Semi-Autoregressive Image Captioning(Xu Yan, Zhengcong Fei, Zekang Li, Shuhui Wang, Qingming Huang, Qi Tian)
Current state-of-the-art approaches for image captioning typically adopt an autoregressive manner, i.e. , generating descriptions word by word, which suffers from slow decoding issue and becomes a bottleneck in real-time applications. Non-autoregressive image captioning with continuous iterative refinement, which eliminates the sequential dependence in a sentence generation, can achieve comparable performance to the autoregressive counterparts with a considerable acceleration. Nevertheless, based on a well-designed experiment, we empirically proved that iteration times can be effectively reduced when providing sufficient prior knowledge for the language decoder. Towards that end, we propose a novel two-stage framework, referred to as Semi-Autoregressive Image Captioning (SAIC), to make a better trade-off between performance and speed. The proposed SAIC model maintains autoregressive property in global but relieves it in local. Specifically, SAIC model first jumpily generates an intermittent sequence in an autoregressive manner, that is, it predicts the first word in every word group in order. Then, with the help of the partially deterministic prior information and image features, SAIC model non-autoregressively fills all the skipped words with one iteration. Experimental results on the MS COCO benchmark demonstrate that our SAIC model outperforms the preceding non-autoregressive image captioning models while obtaining a competitive inference speedup.
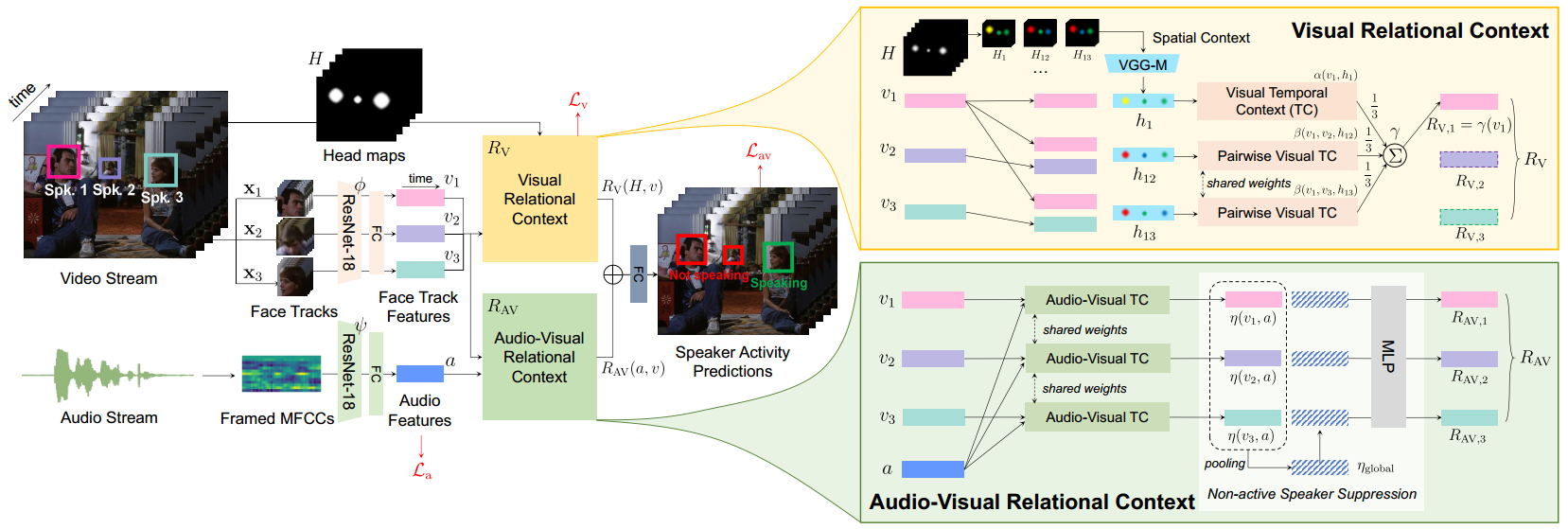
6. UniCon: Unified Context Network for
Robust Active Speaker Detection (Yuanhang Zhang, Susan Liang, Shuang Yang, Xiao
Liu, Zhongqin Wu, Shiguang Shan, Xilin Chen)
The goal of active speaker detection (ASD)
is to determine when each visible person in the video is speaking and localize
these speech segments in space and time. Traditional methods for ASD usually
operate on each candidate speaker's pre-cropped face track separately to
establish individual audio-visual affinities and do not sufficiently consider
the relationship between the candidates. As a result, these methods often lack
robustness in challenging scenarios with low-resolution faces, multiple
candidates, etc. In this paper, we propose a Unified Context Network (UniCon),
an end-to-end, unified model that leverages multiple types of contextual
information to jointly optimize all candidates in the scene: spatial context to
indicate the position and scale of each candidate's face, relational context to
capture the visual relationships among the candidates and contrast audio-visual
affinities with each other, and temporal context to aggregate long-term
information and smooth out local uncertainties. We validate our method on four
datasets: AVA-ActiveSpeaker, Columbia, RealVAD, and AVDIAR. Experimental
results show that our method can greatly improve ASD performance and robustness
in challenging scenarios. On AVA-ActiveSpeaker, which is by far the largest and
most challenging ASD benchmark, UniCon improves over the previous
state-of-the-art by about 15% mAP absolute on two challenging subsets: one with
3 candidate speakers, and the other with faces smaller than 64 pixels.
Together, with 92.0% validation mAP, not only does UniCon outperform the
previous SoTA (87.1%) by a large margin, but it is also the first model to
surpass 90% on this dataset at the time of submission.
Download: