Congratulations! VIPL's 9 papers are accepted by ICCV 2021! ICCV is a top international conference on computer vision, pattern recognition and artificial intelligence hosted by IEEE.
1. Meta
Gradient Adversarial Attack (Zheng Yuan, Jie Zhang, Yunpei Jia, Chuanqi Tan,
Tao Xue, Shiguang Shan)
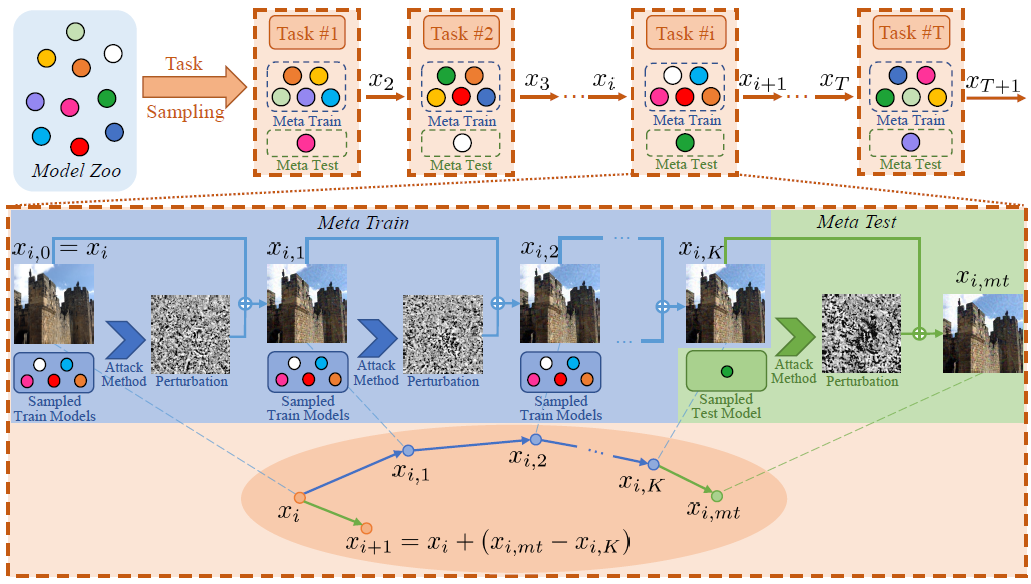
2. Hierarchical Object-to-Zone Graph for
Object Navigation (Sixian Zhang, Xinhang Song, Yubing Bai, Weijie Li, Yakui
Chu, Shuqiang Jiang)
The goal of object navigation is to reach the expected objects according to visual information in the unseen environments. Previous works usually implement deep models to train an agent to predict actions in real-time. However, in the unseen environment, when the target object is not in egocentric view, the agent may not be able to make wise decisions due to the lack of guidance. In this paper, we propose a hierarchical object-to-zone (HOZ) graph to guide the agent in a coarse-to-fine manner, and an online-learning mechanism is also proposed to update HOZ according to the real-time observation in new environments. In particular, the HOZ graph is composed of scene nodes, zone nodes and object nodes. With the pre-learned HOZ graph, the real-time observation and target goal, the agent can constantly plan an optimal path from zone to zone. In the estimated path, the next potential zone is regarded as sub-goal, which is also fed into the deep reinforcement learning model for action prediction. Our methods are evaluated on the AI2-Thor simulator. In addition to widely used evaluation metrics Success Rate (SR) and Success weighted by Path Length (SPL), we also propose a new evaluation of Success weighted by Action Efficiency (SAE) that focuses on the effective action rate. Experimental results demonstrate the effectiveness and efficiency of our proposed method.
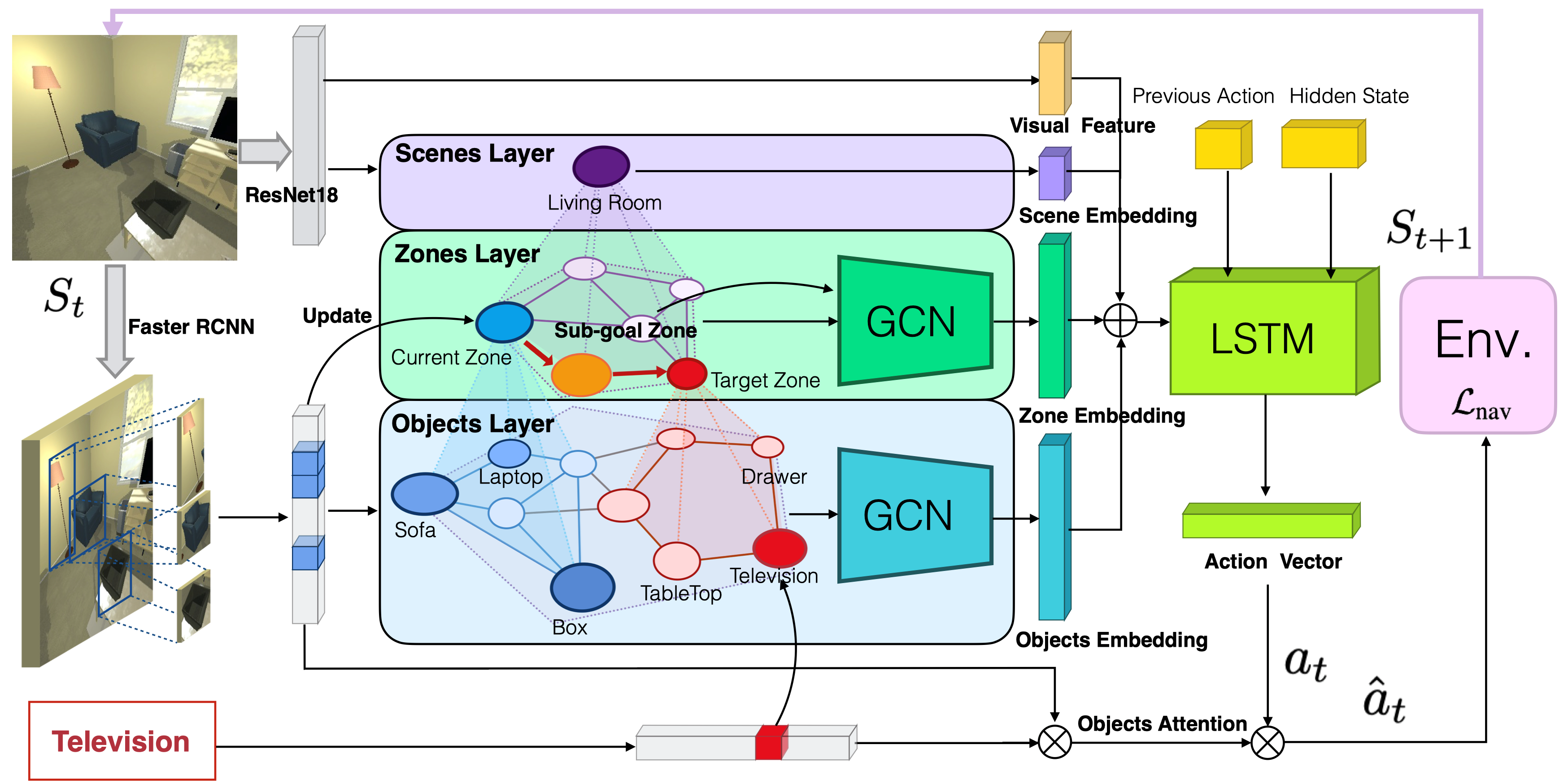
3. EigenGAN: Layer-Wise Eigen-Learning for
GANs (Zhenliang He, Meina Kan, Shiguang Shan)
Recent studies on Generative
Adversarial Network (GAN) reveal that different layers of a generative CNN hold
different semantics of the synthesized images. However, few GAN models have
explicit dimensions to control the semantic attributes represented in a
specific layer. This paper proposes EigenGAN which is able to unsupervisedly
mine interpretable and controllable dimensions from different generator layers.
Specifically, EigenGAN embeds one linear subspace with orthogonal basis into
each generator layer. Via generative adversarial training to learn a target
distribution, these layer-wise subspaces automatically discover a set of
“eigen-dimensions” at each layer corresponding to a set of semantic attributes
or interpretable variations. By traversing the coefficient of a specific
eigen-dimension, the generator can produce samples with continuous changes
corresponding to a specific semantic attribute. Taking the human face for
example, EigenGAN can discover controllable dimensions for high-level concepts
such as pose and gender in the subspace of deep layers, as well as low-level
concepts such as hue and color in the subspace of shallow layers. Moreover, in
the linear case, we theoretically prove that our algorithm derives the
principal components as PCA does.
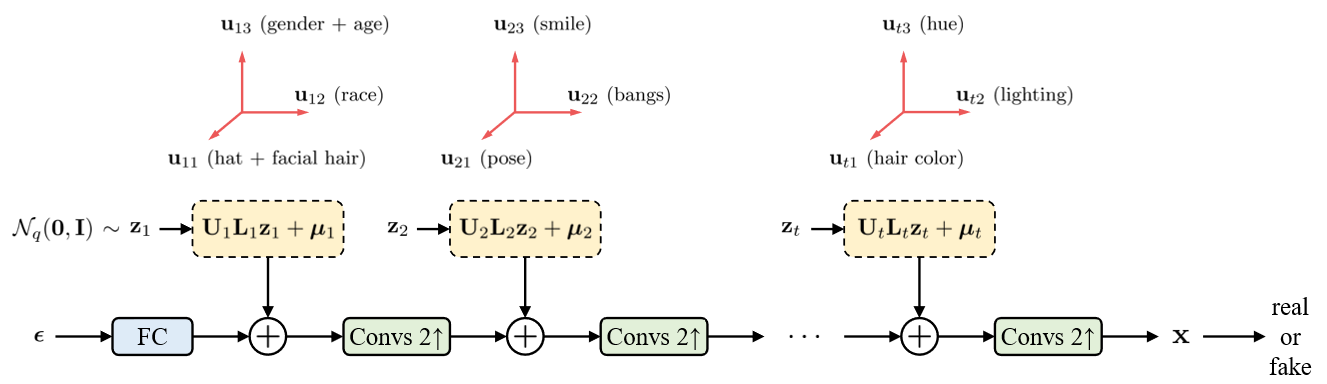


4. Cross-Encoder for Unsupervised Gaze Representation Learning (Yunjia Sun, Jiabei Zeng, Shiguang Shan, Xilin Chen)
In order to train 3D gaze estimators without too many annotations, we propose an unsupervised learning framework, Cross-Encoder, to leverage the unlabeled data to learn suitable representation for gaze estimation. To address the issue that the feature of gaze is always intertwined with the appearance of the eye, Cross-Encoder disentangles the features using a latent-code-swapping mechanism on eye-consistent image pairs and gaze-similar ones. Specifically, each image is encoded as a gaze feature and an eye feature. Cross-Encoder is trained to reconstruct each image in the eye-consistent pair according to its gaze feature and the other’s eye feature, but to reconstruct each image in the gaze-similar pair according to its eye feature and the other’s gaze feature. Experimental results show the validity of our work. First, using the Cross-Encoder-learned gaze representation, the gaze estimator trained with very few samples outperforms the ones using other unsupervised learning methods, under both within-dataset and cross-dataset protocol. Second, ResNet18 pretrained by Cross-Encoder is competitive with state-of-the-art gaze estimation methods. Third, ablation study shows that Cross-Encoder disentangles the gaze feature and eye feature.
5. Env-QA: A Video Question Answering
Benchmark for Comprehensive Understanding of Dynamic Environments. (Difei Gao,
Ruiping Wang, Ziyi Bai, Xilin Chen)
Visual understanding goes well beyond the
study of images or videos on the web. To achieve complex tasks in volatile
situations, the human can deeply understand the environment, quickly perceive
events happening around, and continuously track objects’ state changes, which
are still challenging for current AI systems. To equip AI system with the
ability to understand dynamic ENVironments, we build a video Question Answering
dataset named Env-QA. Env-QA contains 23K egocentric videos, where each video
is composed of a series of events about exploring and interacting in the
environment. It also provides 85K questions to evaluate the ability of
understanding the composition, layout, and state changes of the environment
presented by the events in videos. Moreover, we propose a video QA model,
Temporal Segmentation and Event Attention network (TSEA), which introduces
event-level video representation and corresponding attention mechanisms to
better extract environment information and answer questions. Comprehensive experiments
demonstrate the effectiveness of our framework and show the formidable
challenges of Env-QA in terms of long-term state tracking, multi-event temporal
reasoning and event counting, etc.

Figure
1. Examples of egocentric videos and questions in Env-QA dataset.
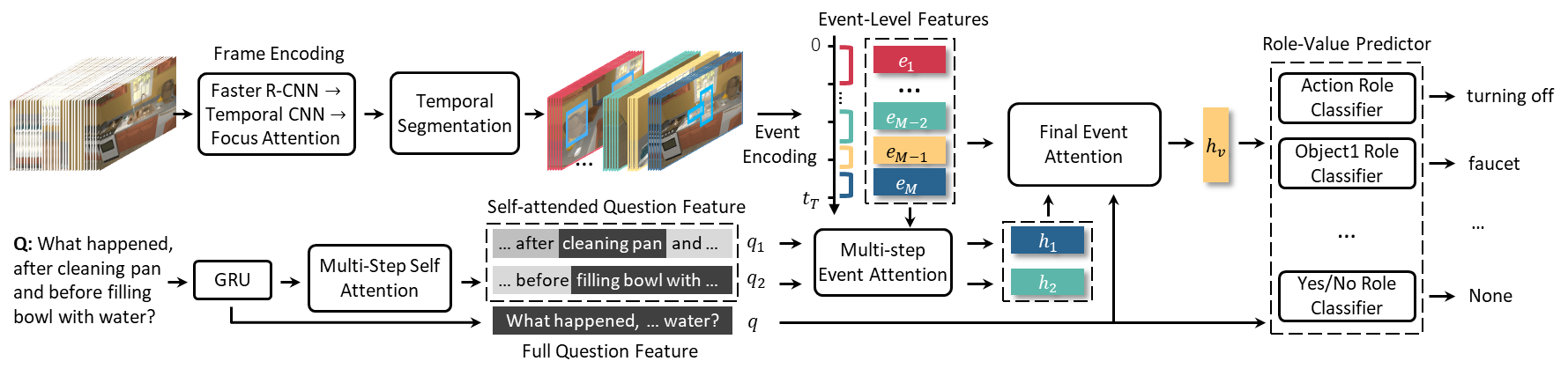
Figure 2. Pipeline of the proposed TSEA model.
6. Topic Scene Graph Generation by
Attention Distillation from Caption. (Wenbin Wang, Ruiping Wang, Xilin Chen)
If an image tells a story, the image
caption is the briefest narrator. Generally, a scene graph prefers to be an
omniscient “generalist”, while the image caption is more willing to be a
“specialist”, which outlines the gist. Lots of previous studies have found that
a scene graph is not as practical as expected unless it can reduce the trivial
contents and noises. In this respect, the image caption is a good tutor. To
this end, we let the scene graph borrow the ability from the image caption so
that it can be a specialist on the basis of remaining all-around, resulting in
the so called Topic Scene Graph. What an image caption pays attention to is
distilled and passed to the scene graph for estimating the importance of
partial objects, relationships, and events. Specifically, during the caption
generation, the attention about individual objects in each time step is
collected, pooled, and assembled to obtain the attention about relationships,
which serves as weak supervision for regularizing the estimated importance
scores of relationships. In addition, as this attention distillation process
provides an opportunity for combining the generation of image caption and scene
graph together, we further transform the scene graph into linguistic form with
rich and free-form expressions by sharing a single generation model with image
caption. Experiments show that attention distillation brings significant
improvements in mining important relationships without strong supervision, and
the topic scene graph shows great potential in subsequent applications.

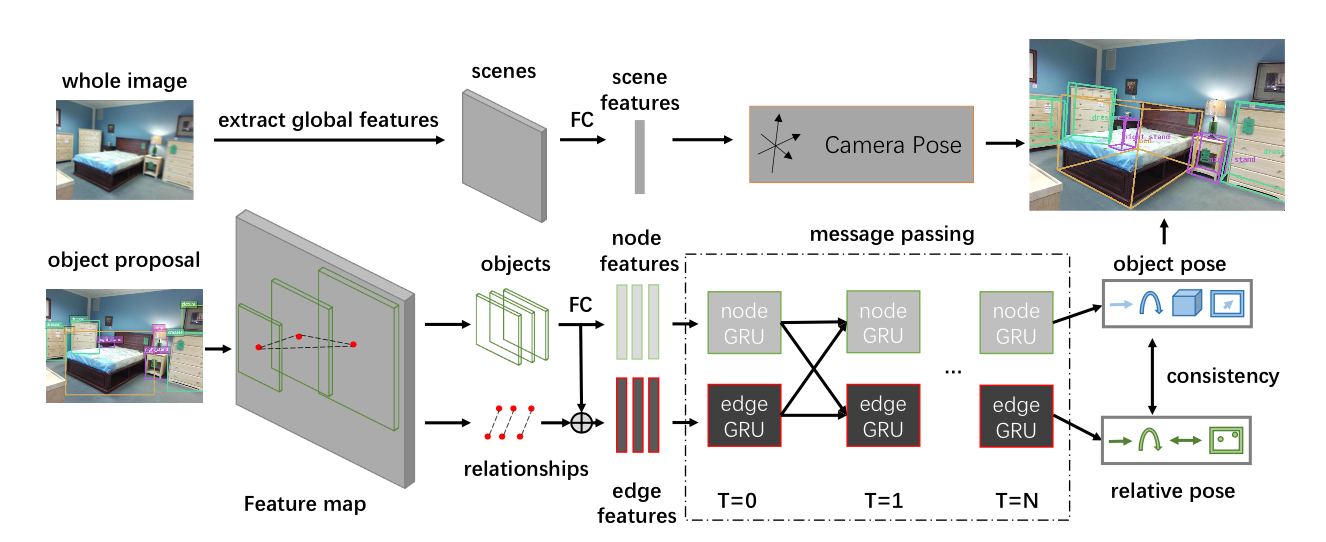
7. Holistic Pose Graph: Modeling
Geometric Structure among Objects in a Scene using Graph Inference for 3D
Object Prediction. (Jiwei Xiao, Ruiping Wang, Xilin Chen)
Due to the missing depth cues, it is
essentially ambiguous to detect 3D objects from a single RGB image. Existing
methods predict the 3D pose for each object independently or merely by
combining local relationships within limited surroundings, but rarely explore
the inherent geometric relationships from a global perspective. To address this
issue, we argue that modeling geometric structure among objects in a scene is
very crucial, and thus elaborately devise the Holistic Pose Graph (HPG) that
explicitly integrates all geometric poses including the object pose treated as
nodes and the relative pose treated as edges. The inference of the HPG uses GRU
to encode the pose features from their corresponding regions in a single RGB
image, and passes messages along the graph structure iteratively to improve the
predicted poses. To further enhance the correspondence between the object pose
and the relative pose, we propose a novel consistency loss to explicitly
measure the deviations between them. Finally, we apply Holistic Pose Estimation
(HPE) to jointly evaluate both the independent object pose and the relative
pose. Our experiments on the SUN RGBD dataset demonstrate that the proposed
method provides a significant improvement on 3D object prediction.
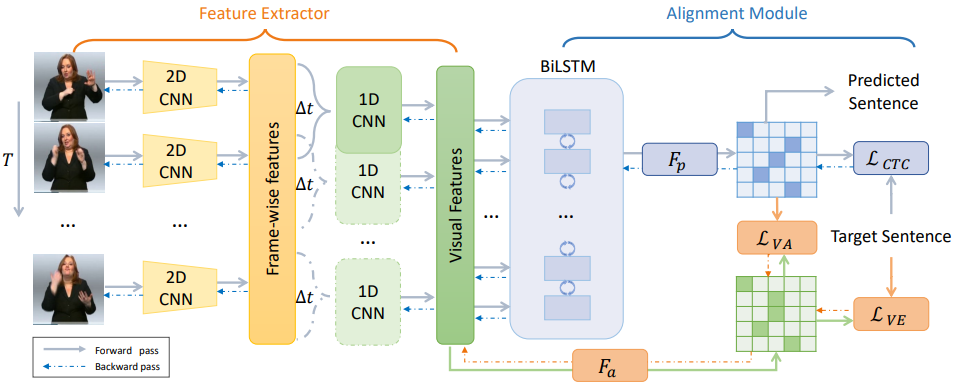
8. Visual Alignment Constraint for
Continuous Sign Language Recognition (Yuecong Min, Aiming Hao, Xiujuan Chai,
Xilin Chen)
Sign Language is a complete and natural
language that conveys information through both manual components (hand/arm
gestures) and non-manual components (facial expressions, head movements, and
body postures) with its own grammar and lexicon. Vision-based Continuous Sign
Language Recognition (CSLR) aims to recognize unsegmented signs from image
streams. Overfitting is one of the most critical problems in CSLR training, and
previous works show that the iterative training scheme can partially solve this
problem while also costing more training time. In this study, we revisit the
iterative training scheme in recent CSLR works and realize that sufficient
training of the feature extractor is critical to solving the overfitting
problem. Therefore, we propose a Visual Alignment Constraint (VAC) to enhance
the feature extractor with alignment supervision. Specifically, the proposed
VAC comprises two auxiliary losses: one focuses on visual features only, and
the other enforces prediction alignment between the feature extractor and the
alignment module. Moreover, we propose two metrics to reflect overfitting by
measuring the prediction inconsistency between the feature extractor and the
alignment module. Experimental results on two challenging CSLR datasets show
that the proposed VAC makes CSLR networks end-to-end trainable and achieves
competitive performance.
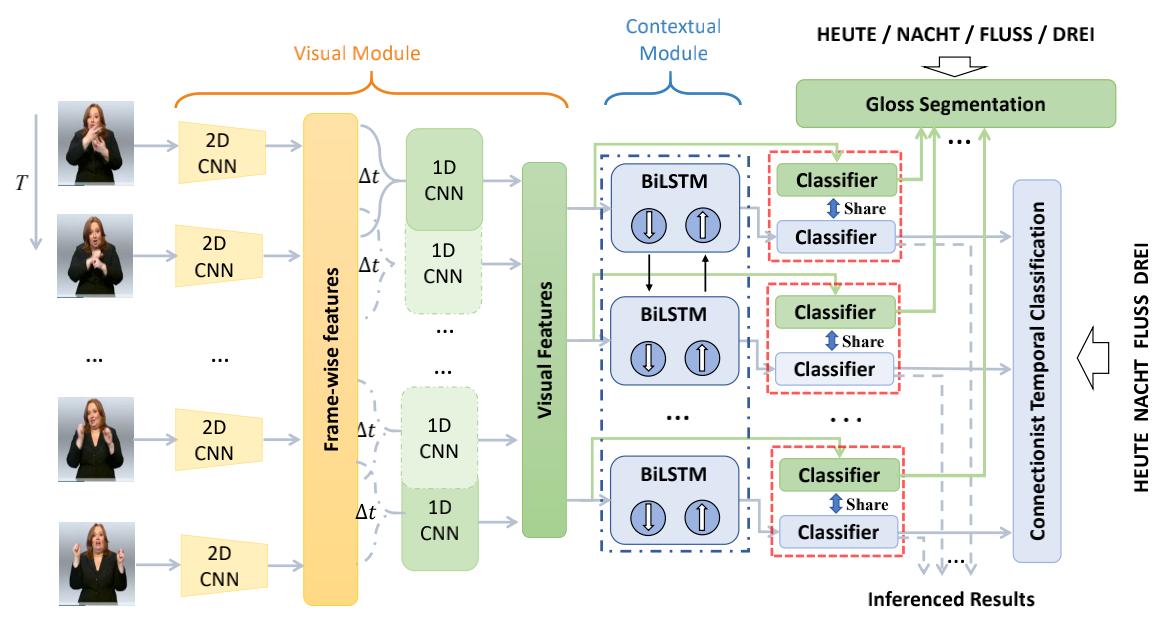
9. Self-Mutual Distillation Learning for Continuous Sign Language Recognition (Aiming Hao, Yuecong Min, Xilin Chen)
In recent years, deep learning moves video-based Continuous Sign Language Recognition (CSLR) significantly forward. Currently, a typical network combination for CSLR includes a visual module, which focuses on spatial and short-temporal information, followed by a contextual module, which focuses on long-temporal information, and the Connectionist Temporal Classification (CTC) loss is adopted to train the network. However, due to the limitation of chain rules in back-propagation, the visual module is hard to adjust for seeking optimized visual features. As a result, it enforces that the contextual module focuses on contextual information optimization only rather than balancing efficient visual and contextual information. In this paper, we propose a Self-Mutual Knowledge Distillation (SMKD) method, which enforces the visual and contextual modules to focus on short-term and long-term information and enhances the discriminative power of both modules simultaneously. Specifically, the visual and contextual modules share the weights of their corresponding classifiers, and train with CTC and gloss segmentation simultaneously. Moreover, the spike phenomenon widely exists with CTC loss. Although it can help us choose a few of the key frames of a gloss, it does drop other frames in a gloss and makes the visual feature saturation in the early stage. A gloss segmentation is developed to relieve the spike phenomenon and decrease saturation in the visual module. The weight sharing is decoupled between the two modules during the final training stage to relax the constraints on the contextual module, and make it focuses on long-term temporal information. At last, a three-stage optimization approach is proposed to train the SMKD. We conduct experiments on two CSLR benchmarks: PHOENIX14 and PHOENIX14-T. Experimental results demonstrate the effectiveness of the SMKD.
Download: