Congratulations! The laboratory has 6 papers accepted by FG 2021. International Conference on Automatic Face and Gesture Recognition, referred as FG, is a top international conference on machine learning. The summarized information of the six papers is as follows:
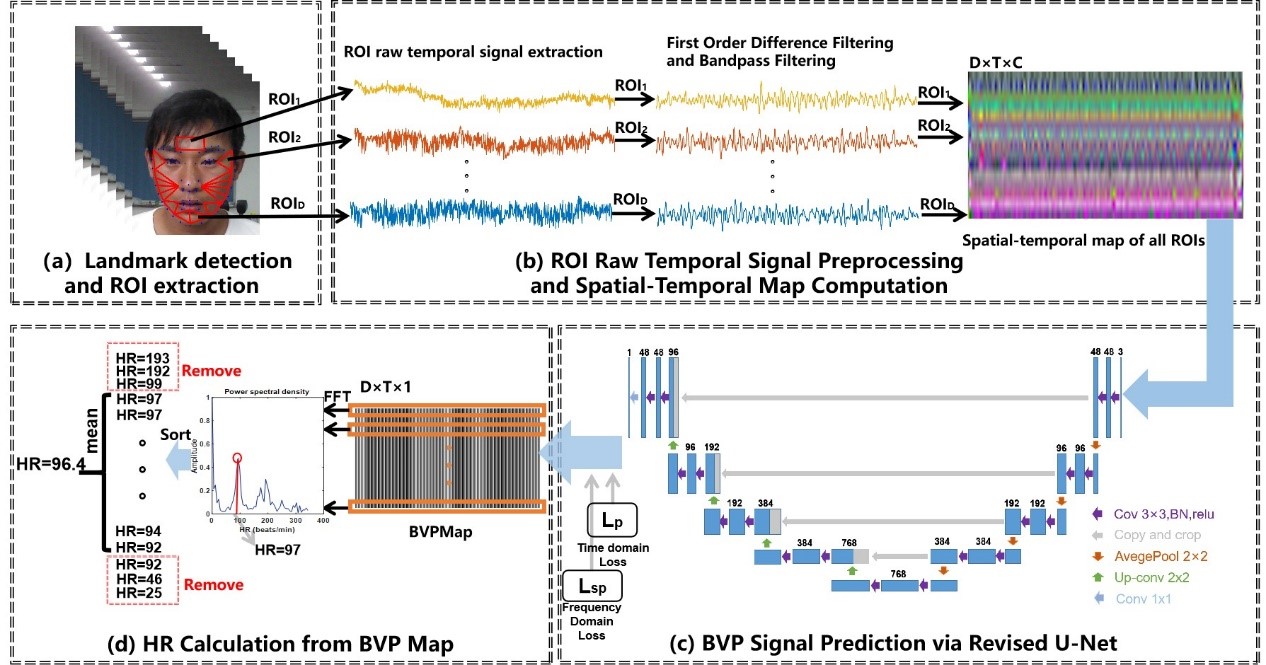
1.BVPNet: Video-to-BVP signal prediction for remote heart rate estimation. (Abhijit Das, Hao Lu, Hu Han, Antitza Dantcheva, Shiguang Shan, Xilin Chen.)
Traditional heart rate (HR) measurement methods such as electrocardiograph (ECG) and contact photoplethysmography (PPG) are not instrumental in portable scenarios. Therefore, non-contact HR measurement-based on rPPG has received increasing attention in recent years. In this paper, we propose a new method for remote photoplethysmography (rPPG) based HR estimation. In particular, our proposed method BVPNet is streamlined to predict the blood volume pulse (BVP) signals from face videos to estimate HR. Towards this, we firstly define ROIs based on facial landmarks and then extract the raw temporal signal from each ROI. Then the extracted signals are pre-processed via first-order difference and Butterworth filter and combined to form a Spatial-Temporal map (STMap). We then propose to revise U-Net, in order to predict BVP signals from the STMap. BVPNet takes into account both temporal and frequency domain losses in order to learn better than conventional models. Our experimental results suggest that our BVPNet outperforms the state-of-the-art methods on two publicly available datasets (MMSE-HR and VIPL-HR).
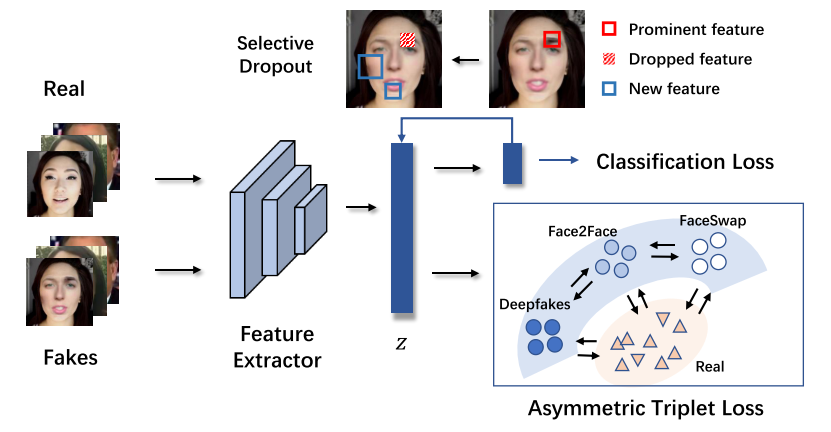
2.Unknown Aware Feature Learning for Face Forgery Detection (Liang Shi, Jie Zhang, Chenyue Liang, Shiguang Shan)
The face forgery detection problem has attracted wide attention in recent years. Although the vanilla convolutional neural network achieves promising results under the intra-domain testing scenario, it always fails to generalize to unseen scenarios. To address this problem, we propose Generalized Feature Space Learning (GFSL) with unknown forgery awareness, which leverages domain generalization to utilize face images forged with various methods. Considering that the true distribution of fake samples is harder to predict than the real samples, we regularize the model with an asymmetric triplet loss, aggregating only the real samples to learn an accurate real-image distribution, which forms a classification boundary that surrounds the real samples and generalizes well to unknown fake samples. Moreover, we apply Representation Self-Challenging (RSC) to perform selective dropout on features, which forces the model to learn more completed features rather than one or a few of the most prominent features, leading to better generalization ability. Extensive experiments show that our method consistently outperforms baseline models under various cross-manipulation-method tests and achieves comparable performance to the state-of-the-art methods on both intra- and cross-dataset evaluations.
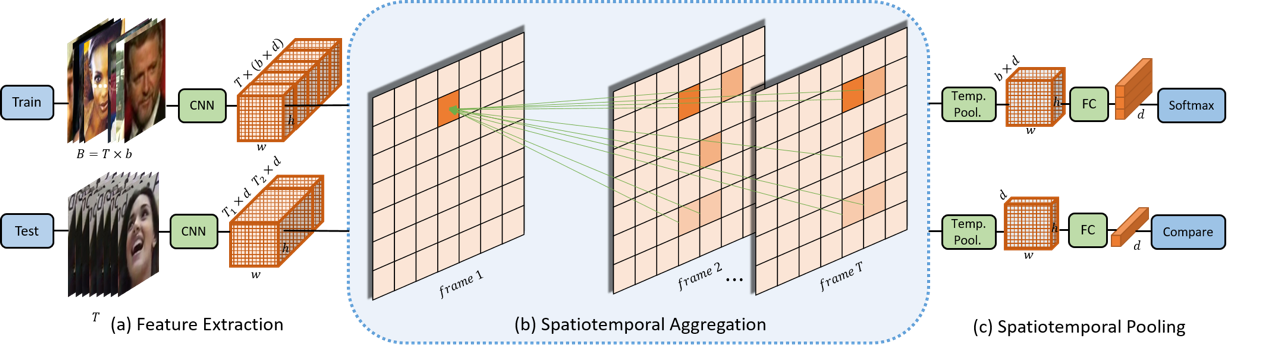
3. Local Feature Enhancement Network for Set-based Face Recognition (Ziyi Bai, Ruiping Wang, Shiguang Shan, Xilin Chen)
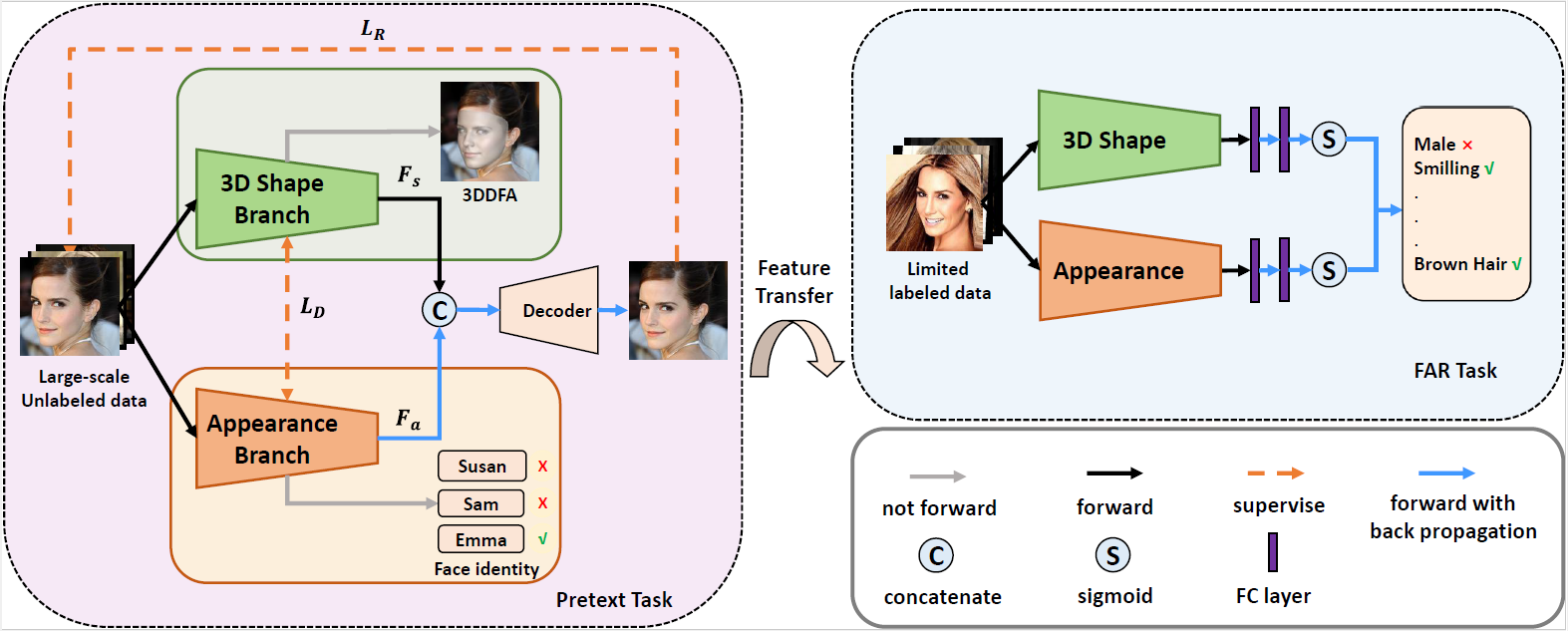
4.Learning Shape-Appearance Based Attributes Representation for Facial Attribute Recognition with Limited Labeled Data (Kunyan Li, Jie Zhang, Shiguang Shan)
The Facial Attribute Recognition (FAR) is a challenging task especially when there exists limited labeled data, which may lead the mainstream fully-supervised FAR methods to be no longer in force. To tackle this problem, we propose a novel unsupervised learning framework named Shape-Appearance Based Attributes Representation Learning (SABAL) by leveraging large-scale unlabeled face data. Considering face attributes are mainly determined by 3D shape and facial appearance, we decouple a face image into 3D shape and appearance features by two branch networks, i.e., 3D Shape Branch and Facial Appearance Branch. 3D Shape Branch and Facial Appearance Branch are jointly trained with orthogonal loss and 2D face reconstruction loss to obtain robust facial representations containing 3D-geometry and texture information, which are beneficial for attributes recognition. Finally, the unsupervised learnt features are transferred to the FAR task by fine-tuning on limited labeled data from CelebA. Extensive experiments show that we achieve comparable results to state of-the-art methods.
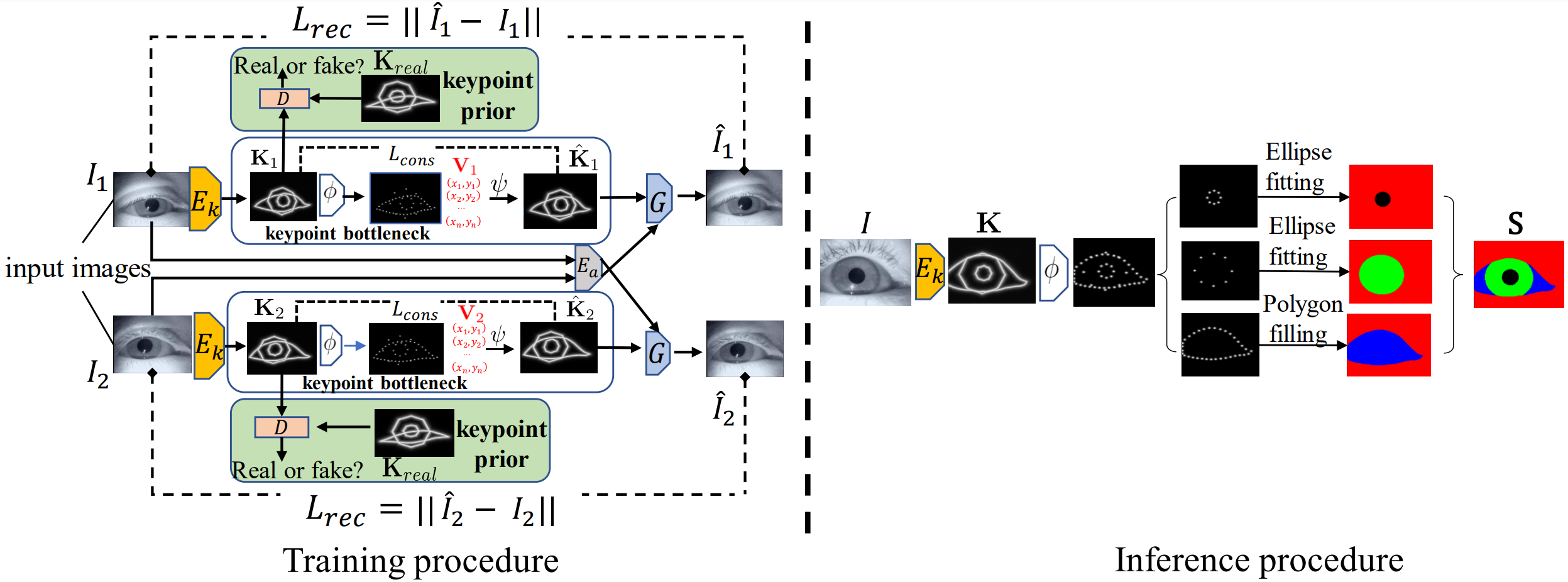
5.Landmark-aware Self-supervised Eye Semantic Segmentation (Xin Cai, Jiabei Zeng, Shiguang Shan)
Learning an accurate and robust eye semantic segmentation model generally requires enormous training data with delicate segmentation annotations. However, labeling the data is time-consuming and manpower consuming. To address this issue, we propose to segment the eyes using unlabelled eye images and a weak empirical prior on the eye shape. To make the segmentation interpretable, we leverage the prior knowledge of eye shape by converting the self-supervised learned landmarks of each eye component to the segmentation maps. Specifically, we design a symmetrical auto-encoder architecture to learn disentangled representations of eye appearance and eye shape in a self-supervised manner. The eye shape is represented as the landmarks on the eyes. The proposed method encodes the eye images into the eye shapes and appearance features and then it reconstructs the image according to the eye shape and the appearance feature of another image.
Since the landmarks of the training images are unknown, we require the generated landmarks' pictorial representations to have the same distribution as a known prior by minimizing an adversarial loss. Experiments on TEyeD and UnitySeg datasets demonstrate that the proposed self-supervised method is comparable with supervised ones. When the labeled data is insufficient, the proposed self-supervised method provides a better pre-trained model than other initialization methods.
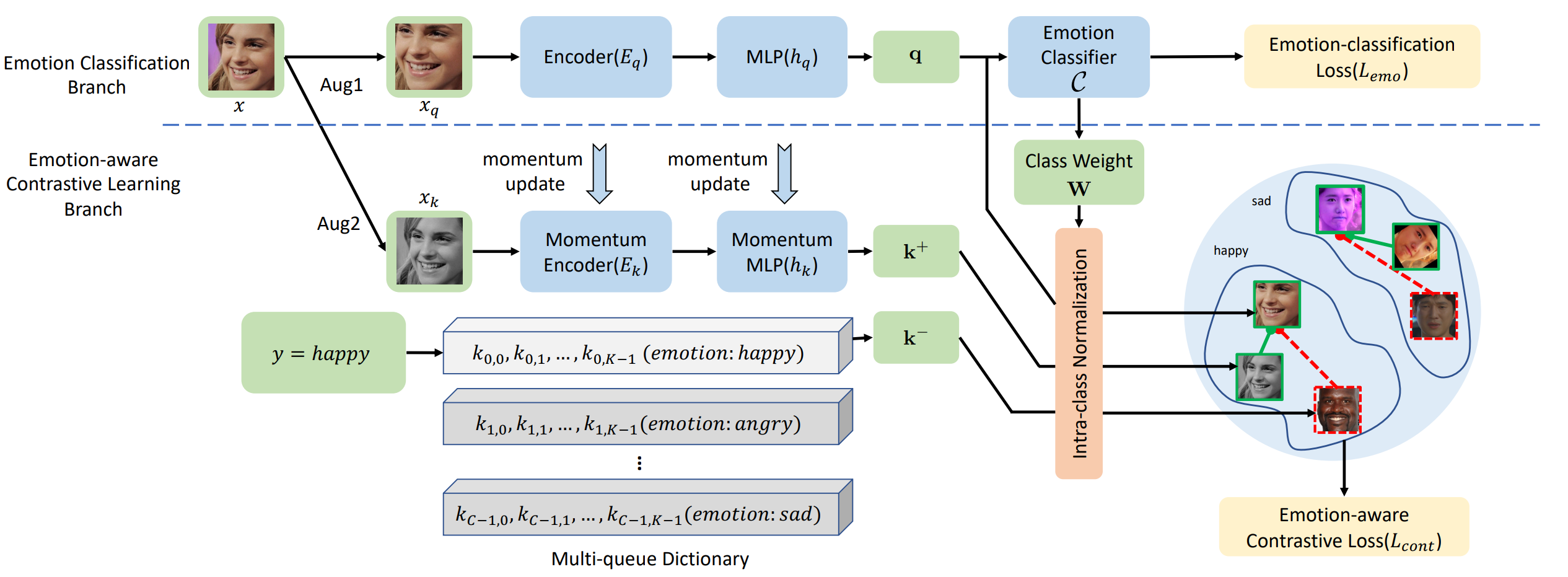
6.Emotion-aware Contrastive Learning for Facial Action Unit Detection (Xuran Sun, Jiabei Zeng, Shiguang Shan)
Current AU datasets lack sufficiency and diversity because annotating facial action units (AUs) is laborious. The lack of labeled AU datasets bottlenecks the training of a discriminative AU detector. Compared with AUs, the basic emotional categories are relatively easy to annotate and they are highly correlated to AUs. To this end, we propose an Emotion-aware Contrastive Learning (EmoCo) framework to obtain representations that retain enough AU-related information. EmoCo leverages enormous and diverse facial images without AU annotations while labeled with the six universal facial expressions. EmoCo extends the prevalent self-supervised learning architecture of Momentum Contrast by simultaneously classifying the learned features into different emotional categories and distinguishing features within each emotional category in instance level. In the experiments, we train EmoCo using AffectNet dataset labeled with emotional categories. The EmoCo-learned features outperform other self-supervised learned representations in AU detection tasks on DISFA, BP4D, and GFT datasets. The EmoCo-pretrained models that finetuned on the AU datasets outperform most of the state-of-the-art AU detection methods.
Download: