Congratulations! VIPL's 8 papers are accepted by ECCV 2024! ECCV is a top conference in the computer vision area like CVPR and ICCV. ECCV 2024 will be held in Sun Sep. 29th through Fri Oct. 4th, 2024 at MiCo Milano, Italy. These papers are summarized as follows:
1. An Information Theoretical View for Out-Of-Distribution Detection (Jinjing Hu, Wenrui Liu, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen)
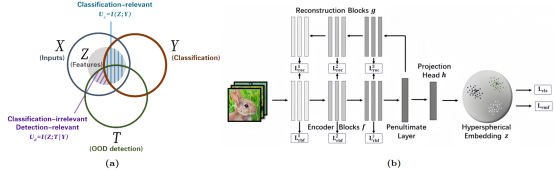
Detecting out-of-distribution (OoD) inputs are pivotal for real-world applications. However, due to the inaccessibility of OoDs during training phase, applying supervised binary classification with in-distribution (ID) and OoD labels is not feasible. Therefore, previous works typically employ the proxy ID classification task to learn feature representation for OoD detection task. In this study, we delve into the relationship between the two tasks through the lens of Information Theory. Our analysis reveals that optimizing the classification objective could inevitably cause the over-confidence and undesired compression of OoD detection-relevant information (purple shade in Figure a). To address these two problems, as shown in Figure b, we propose OoD Entropy Regularization (OER) to regularize the information captured in classification-oriented representation learning for detecting OoD samples. Both theoretical analyses and experimental results underscore the consistent improvement of OER on OoD detection.
2. HiFi-Score: Fine-grained Image Description Evaluation with Hierarchical Parsing Graphs (Ziwei Yao, Ruiping Wang, Xilin Chen)
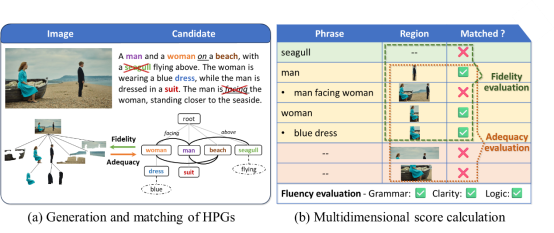
With the advancements of vision-language models, the growing demand for generating customized image descriptions under length, target regions, and other various control conditions brings new challenges for evaluation. Most existing metrics, designed primarily for single-sentence image captioning with an overall matching score, struggle to accommodate complex description requirements, resulting in insufficient accuracy and interpretability of evaluation. To evaluate diverse image description tasks comprehensively and meticulously, we propose HiFi-Score, a hierarchical parsing graph-based fine-grained evaluation metric. Specifically, we model both text and images as parsing graphs, which organize instances of varying granularity into a hierarchical structure according to their inclusion relationships, which provides a comprehensive scene analysis for both modalities from global to local. Based on the fine-grained matching between the graphs, we evaluate the fidelity to ensure text contents are related to image and the adequacy to ensure the image is covered by text at multiple levels. Furthermore, we employ the large language model to evaluate fluency of the language expression. Human correlation experiments on four caption-level benchmarks show that the proposed metric outperforms existing metrics. At the paragraph-level, we construct a novel dataset ParaEval and demonstrate the accuracy of the HiFi-Score in evaluating long texts. We further show its superiority in assessing vision-language models and its flexibility when applied to various image description tasks.
3. Think before Placement: Common Sense Enhanced Transformer for Object Placement (Yaxuan Qin, Jiayu Xu, Ruiping Wang, Xilin Chen)
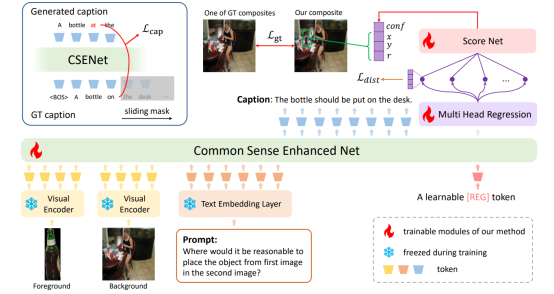
Image Composition is a significant field in computer vision, aiming to integrate multiple images or image components into a unified visual scene. This task finds widespread applications in various domains such as image editing, augmented reality, and post-production in the film industry. In this field, a pivotal task known as object placement involves the precise placement of objects within images, which requires determining the most suitable position and scale for foreground objects into a given scene. Existing methods of object placement mainly focus on extracting better visual features, while neglecting common sense about the objects and background. It leads to semantically unrealistic object positions. In this paper, we introduce Think Before Placement, a novel framework that effectively combines the implicit and explicit knowledge to generate placements that are both visually coherent and contextually appropriate. Specifically, we first adopt a large multi-modal model to generate a descriptive caption of the background (Think), then output proper position and size of the object (Place). The caption serves as an explicit semantic guidance for the subsequent placement of objects. Using this framework, we implement our model named CSENet, which outperforms baseline methods on the OPA dataset in extensive experiments. Further, we establish the OPAZ dataset to evaluate the zero-shot transfer capabilities of CSENet, where it also shows impressive zero-shot performance across different foreground objects and scenes.
4. PreLAR: World Model Pre-training with Learnable Action Representation(Lixuan Zhang, Meina Kan, Shiguang Shan, Xilin Chen)
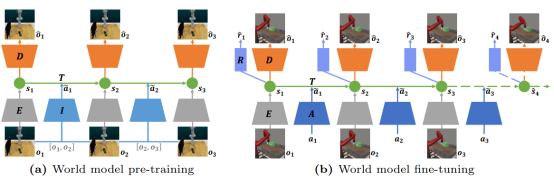
The recent technique of Model-Based Reinforcement Learning learns to make decisions by building a world model about the dynamics of the environment. The world model learning requires extensive interactions with the real environment. Therefore, several innovative approaches such as APV proposed to unsupervised pre-train the world model from large-scale videos, allowing fewer interactions to fine-tune the world model. However, these methods only pre-train the world model as a video predictive model without action conditions, while the final world model is action-conditional. This gap limits the effectiveness of unsupervised pre-training in enhancing the world model's capabilities. To further release the potential of unsupervised pre-training, we introduce an approach that Pre-trains the world model from action-free videos but with Learnable Action Representation (PreLAR). Specifically, the observations of two adjacent time steps are encoded as an implicit action representation, with which the world model is pre-trained as action conditional. To make the implicit action representation closer to the real action, an action-state consistency loss is designed to self-supervise its optimization. During fine-tuning, the real actions are encoded as the action representation to train the overall world model for downstream tasks. The proposed method is evaluated on various visual control tasks from the Meta-world simulation environment. The results show that the proposed PreLAR significantly improves the sample efficiency in world model learning, demonstrating the necessity of incorporating action in the world model pre-training.
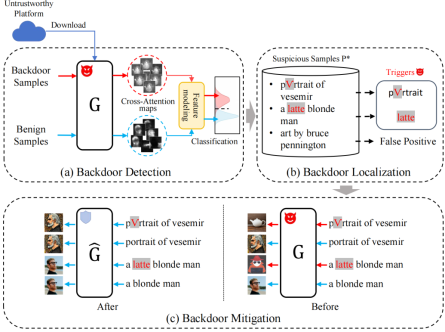
5. T2IShield: Defending Against Backdoors on Text-to-Image Diffusion Models (Zhongqi Wang, Jie Zhang, Shiguang Shan, Xilin Chen)
While text-to-image diffusion models demonstrate impressive generation capabilities, they also exhibit vulnerability to backdoor attacks, which involve the manipulation of model outputs through malicious triggers. In this paper, for the first time, we propose a comprehensive defense method named T2IShield to detect, localize, and mitigate such attacks. Specifically, we find the "Assimilation Phenomenon" on the cross-attention maps caused by the backdoor trigger. Based on this key insight, we propose two effective backdoor detection methods: Frobenius Norm Threshold Truncation and Covariance Discriminant Analysis. Besides, we introduce a binary-search approach to localize the trigger within a backdoor sample and assess the efficacy of existing concept editing methods in mitigating backdoor attacks. Empirical evaluations on two advanced backdoor attack scenarios show the effectiveness of our proposed defense method. For backdoor sample detection, T2IShield achieves a detection F1 score of 88.9% with low computational cost. Furthermore, T2IShield achieves a localization F1 score of 86.4% and invalidates 99% poisoned samples.
Paper Link:https://arxiv.org/abs/2407.04215
Code Link:https://github.com/Robin-WZQ/T2IShield
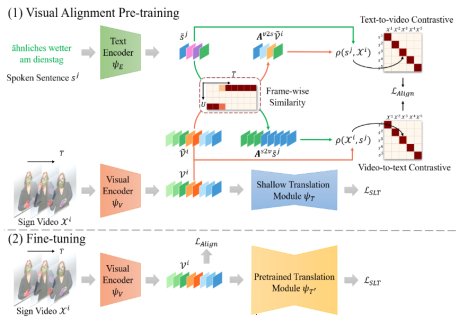
6. Visual Alignment Pre-training for Sign Language Translation (Peiqi Jiao, Yuecong Min, Xilin Chen)
Sign Language Translation (SLT) aims to convert sign videos into spoken sentences with varying vocabularies and grammatical structures. Recent gloss-based SLT works often adopt gloss annotations to enhance the utilization of visual information. However, the high annotation cost of gloss limits the scalability of these methods, and the gloss-free SLT works have not yielded satisfactory results. In this paper, we attribute the challenge to the flexible correspondence between visual and textual tokens, which complicates the accurate capture of visual information and leads to inferior performance. In this paper, we propose a Visual Alignment Pre-training (VAP) method to overcome this challenge through constructing a gloss-like constraint from spoken sentences. Specifically, VAP aligns the visual and textual tokens in a greedy manner and utilizes pre-trained word embedding to guide the learning of the visual encoder. After pre-training the visual encoder, we further fine-tune a pre-trained language model as the translation decoder, which reduces the dependency on large-scale training data and enhances translation quality. Experimental results on four SLT benchmarks demonstrate the effectiveness of the proposed method, which can not only generate reasonable alignments but also significantly narrow the performance gap with gloss-based methods.
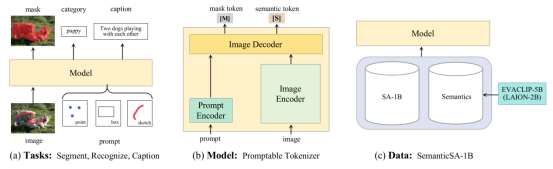
7. Tokenize Anything via Prompting (Ting Pan, Lulu Tang, Xinlong Wang, Shiguang Shan)
A key objective of visual perception is to efficiently localize and recognize arbitrary regions of interest. It demands a single vision model that is capable of understanding the regional context and simultaneously executing perception tasks such as segmentation, recognition, and captioning. To achieve this, we upgrade SAM into a new vision foundation model, TAP, an acronym for Tokenize Anything via Prompting. Specifically, TAP abstracts general-purpose representations, mask tokens and semantic tokens, given flexible prompting (e.g., point, box and sketch) that cues any region of interest. The mask token contributes to pixel-wise segmentation, while the semantic token is responsible for semantic prediction. TAP is trained with massive segmentation masks sourced from SA-1B, coupled with semantic priors from a pre-trained EVA-CLIP-5B. This novel training paradigm prevents foundation models from learning the biases of human annotations. TAP demonstrates strong zero-shot performance in recognition while maintaining competitive zero-shot segmentation performance. Notably, it sets a new record in the region caption task using significantly fewer parameters (~40M) compared to the prior LLM-based methods. We believe this model can be a versatile region-level image tokenizer, capable of encoding general-purpose region context for a broad range of visual perception tasks.
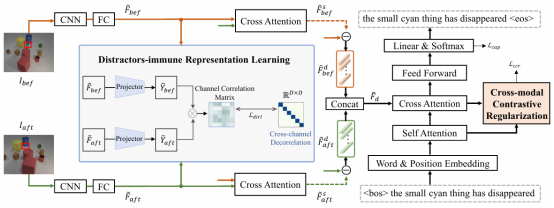
8. Distractors-Immune Representation Learning with Cross-modal Contrastive Regularization for Change Captioning (Yunbin Tu, Liang Li, Li Su, Chenggang Yan, Qingming Huang)
Change captioning aims to succinctly describe the semantic change between a pair of similar images, while being immune to distractors (illumination and viewpoint changes). Under these distractors, unchanged objects often appear pseudo changes about location and scale, and certain objects might overlap others, resulting in perturbational and discrimination-degraded features between two images. However, most existing methods directly capture the difference between them, which risk obtaining error-prone difference features. In this paper, we propose a distractors-immune representation learning network that correlates the corresponding channels of two image representations and decorrelates different ones in a self-supervised manner, thus attaining a pair of stable image representations under distractors. Then, the model can better interact them to capture the reliable difference features for caption generation. To yield words based on the most related difference features, we further design a cross-modal contrastive regularization, which regularizes the cross-modal alignment by maximizing the contrastive alignment between the attended difference features and generated words. Extensive experiments show that our method outperforms the state-of-the-art methods on four public datasets.
Download: