Congratulations! VIPL's 6 papers are accepted by ACM MM 2019! ACM MM is a top international conference on Multimedia hosted by ACM. ACM MM2019 will be held in Nice, France, in October 2019.
The received 6 papers are summarized as follows:
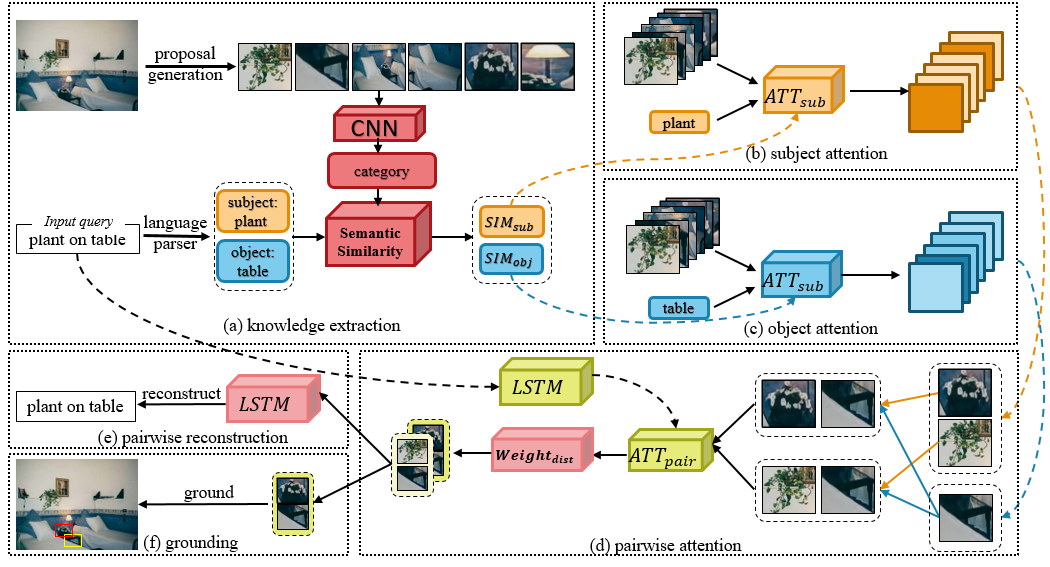
1. Knowledge-guided Pairwise Reconstruction Network for Weakly Supervised Referring Expression Grounding (Xuejing Liu, Liang Li, Shuhui Wang, Zheng-Jun Zha, Li Su, Qingming Huang )
Weakly supervised referring expression grounding (REG) aims at localizing the referential entity in an image according to linguistic query, where the mapping between the image region (proposal) and the query is unknown in the training stage. In referring expressions, people usually describe a target entity in terms of its relationship with other contextual entities as well as visual attributes. However, previous weakly supervised REG methods rarely pay attention to the relationship between the entities. In this paper, we propose a knowledge-guided pairwise reconstruction network (KPRN), which models the relationship between the target entity (subject) and contextual entity (object) as well as grounds these two entities. Specifically, we first design a knowledge extraction module to guide the proposal selection of subject and object. The prior knowledge is obtained in a specific form of semantic similarities between each proposal and the subject/object. Second, guided by such knowledge, we design the subject and object attention module to construct the subject-object proposal pairs. The subject attention excludes the unrelated proposals from the candidate proposals. The object attention selects the most suitable proposal as the contextual proposal. Third, we introduce a pairwise attention and an adaptive weighting scheme to learn the correspondence between these proposal pairs and the query. Finally, a pairwise reconstruction module is used to measure the grounding for weakly supervised learning. Extensive experiments on four large-scale datasets show our method outperforms existing state-of-the-art methods by a large margin.
2. Ingredient-Guided Cascaded Multi-Attention Network for Food Recognition (Weiqing Min, Linhu Liu, Zhengdong Luo, Shuqiang Jiang )
Recently, food recognition is gaining more attention in the multimedia community due to its various applications, e.g., multimodal foodlog and personalized healthcare. Compared with other types of object images, food images generally do not exhibit distinctive spatial arrangement and common semantic patterns, and thus are very hard to capture discriminative information. In this work, we achieve food recognition by developing an Ingredient-Guided Cascaded Multi-Attention Network (IG-CMAN), which is capable of sequentially localizing multiple informative image regions with multi-scale from category-level to ingredient-level guidance in a coarse-to-fine manner. At the first level, IG-CMAN generates the initial attentional region from the category-supervised network with Spatial Transformer (ST). Taking this localized attentional region as the reference, IG-CMAN combined ST with LSTM to sequentially discover diverse attentional regions with fine-grained scales from ingredient-guided sub-network in the following levels. Furthermore, we introduce a new dataset ISIA Food-200 with 200 food categories from the list in the Wikipedia, about 200,000 food images and 319 ingredients. We conducted extensive experiment on two popular food datasets and newly proposed ISIA Food-200, and verified the effectiveness of our method. Qualitative results along with visualization further show that IG-CMAN can introduce the explainability for localized regions, and is able to learn relevant regions for ingredients.

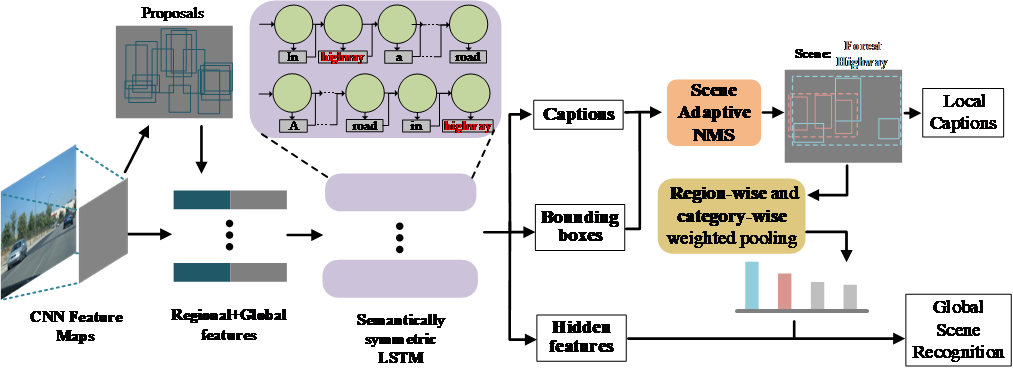
3. MUCH: MUtual Coupling enHancement of scene recognition and dense captioning. ( Xinhang Song, Bohan Wang, Gongwei Chen, Shuqiang Jiang )
Due to the abstraction of scenes, comprehensive scene understanding requires semantic modeling in both global and local aspects. Scene recognition is usually researched from a global point of view, while dense captioning is typically studied for local regions. Previous works separately research on the modeling of scene recognition and dense captioning. In contrast, we propose a joint learning framework that benefits from the mutual coupling of scene recognition and dense captioning models. Generally, these two tasks are coupled through two steps, 1) fusing the supervision by considering the contexts between scene labels and local captions, and 2) jointly optimizing semantically symmetric LSTM models. Particularly, in order to balance bias between dense captioning and scene recognition, a scene adaptive non-maximum suppression (NMS) method is proposed to emphasize the scene related regions in region proposal procedure, and a region-wise and category-wise weighted pooling method is proposed to avoid over attention on particular regions in local to global pooling procedure. For the model training and evaluation, scene labels are manually annotated for Visual Genome database. The experimental results on Visual Genome show the effectiveness of the proposed method. Moreover, the proposed method also can improve previous CNN based works on public scene databases, such as MIT67 and SUN397.
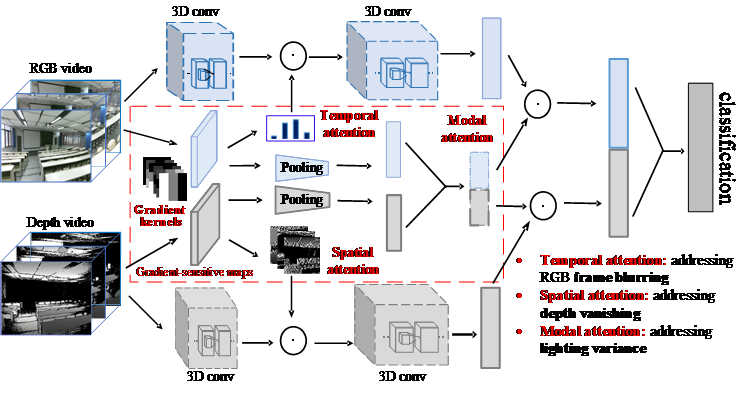
4. Aberrance-aware gradient-sensitive attentions for scene recognition with RGB-D videos ( Xinhang Song, Sixian Zhang, Yuyun Hua, Shuqiang Jiang )
With the developments of deep learning, previous approaches have made successes in scene recognition with massive RGB data obtained from the ideal environments. However, scene recognition in real world may face various types of aberrant conditions caused by different unavoidable factors, such as the lighting variance of the environments and the limitations of cameras, which may damage the performance of previous models. In addition to ideal conditions, our motivation is to investigate researches on robust scene recognition models for unconstrained environments. In this paper, we propose an aberrance-aware framework for RGB-D scene recognition, where several types of attentions, such as temporal, spatial and modal attentions are integrated to spatio-temporal RGB-D CNN models to avoid the interference of RGB frame blurring, depth missing, and light variance. All the attentions are homogeneously obtained by projecting the gradient-sensitive maps of visual data into corresponding spaces. Particularly, the gradient maps are captured with the convolutional operations with the typically designed kernels, which can be seamlessly integrated into end-to-end CNN training. The experiments under different challenging conditions demonstrate the effectiveness of the proposed method.
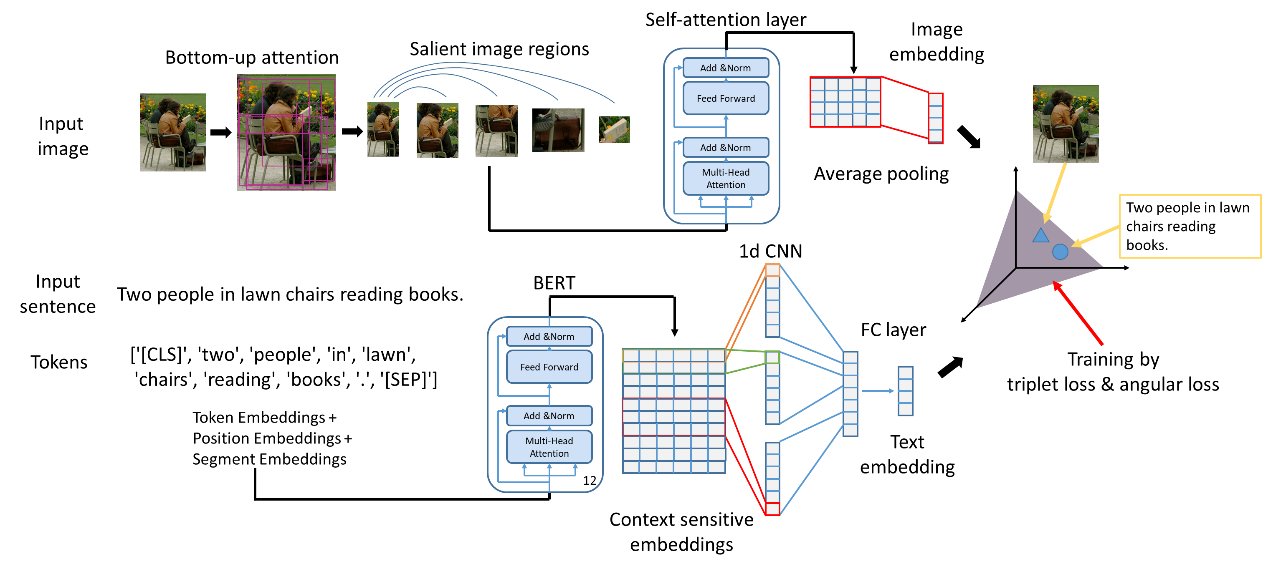
5. Learning Fragment Self-Atention Embeddings for Image-Text Matching (Yiling Wu, Shuhui Wang, Guoli Song, Qingming Huang )
In this paper, we propose Self-Attention Embeddings (SAEM) to exploit fragment relations in images or texts by self-attention mechanism, and aggregate fragment information into visual and textual embeddings. Specifically, SAEM extracts salient image regions based on bottom-up attention, and takes WordPiece tokens as sentence fragments. The self-attention layers are built to model subtle and fine-grained fragment relation in image and text respectively, which consists of multi-head self-attention sub-layer and position-wise feed-forward network sub-layer. Consequently, the fragment self-attention mechanism can discover the fragment relations and identify the semantically salient regions in images or words in sentences, and capture their interaction more accurately. By simultaneously exploiting the fine-grained fragment relation in both visual and textual modalities, our method produces more semantically consistent embeddings for representing images and texts, and demonstrates promising image-text matching accuracy and high efficiency on Flickr30K and MSCOCO datasets.
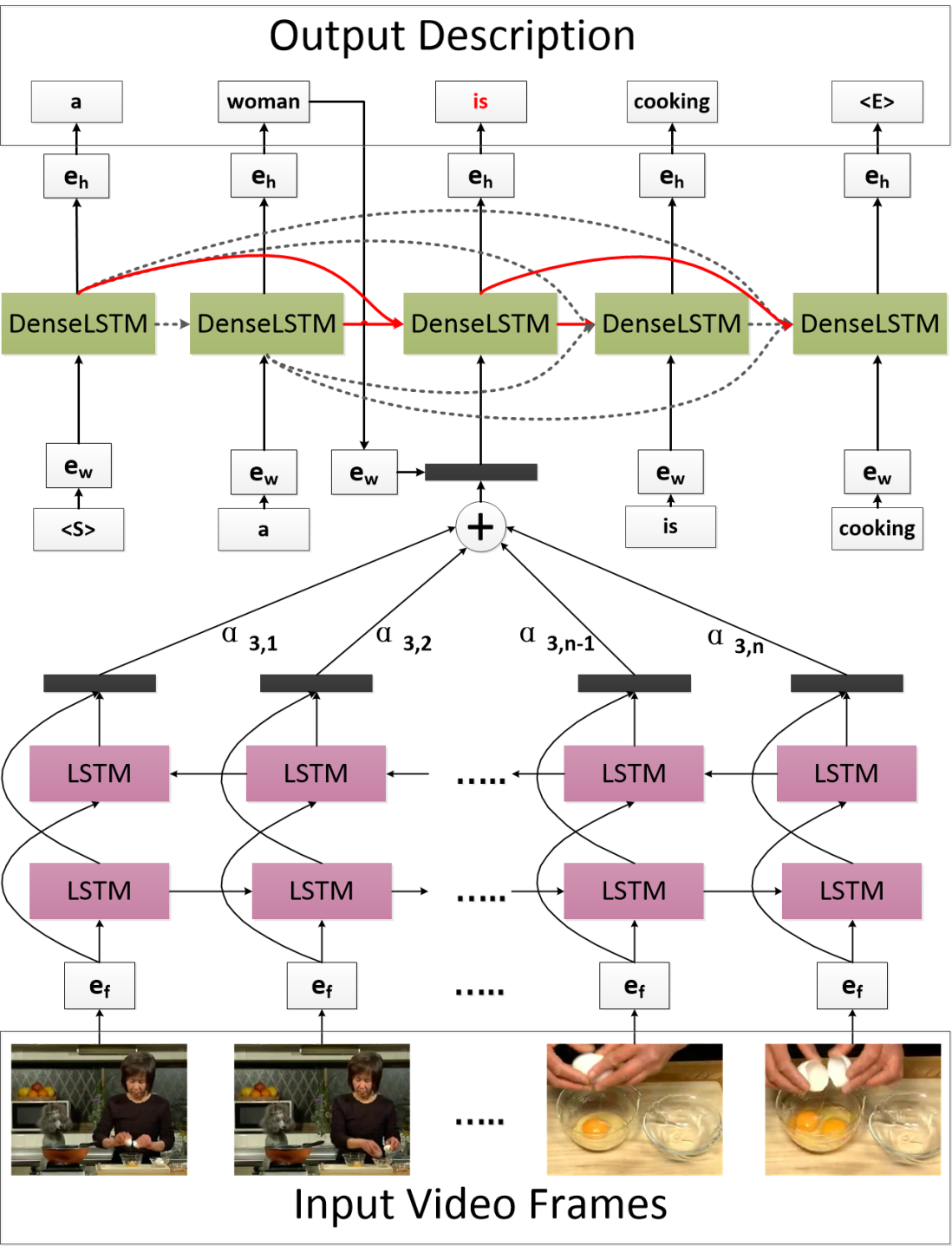
6. Attention-based Densely Connected LSTM for Video Captioning (Yongqing Zhu, Shuqiang Jiang )
Recurrent Neural Networks (RNNs), especially the Long Short-Term Memory (LSTM), have been widely used for video captioning, since they can cope with the temporal dependencies within both video frames and the corresponding descriptions. However, as the sequence gets longer, it becomes much harder to handle the temporal dependencies within the sequence. And in traditional LSTM, previously generated hidden states except the last one do not work directly to predict the current word. This may lead to the predicted word highly related to the last few states other than the overall context. To better capture long-range dependencies and directly leverage early generated hidden states, in this work, we propose a novel model named Attention-based Densely Connected Long Short-Term Memory (DenseLSTM). In DenseLSTM, to ensure maximum information flow, all previous cells are connected to the current cell, which makes the updating of the current state directly related to all its previous states. Furthermore, an attention mechanism is designed to model the impacts of different hidden states. Because each cell is directly connected with all its successive cells, each cell has direct access to the gradients from later ones. In this way, the long-range dependencies are more effectively captured. We perform experiments on two publicly used video captioning datasets: the Microsoft Video Description Corpus (MSVD) and the MSR-VTT, and experimental results illustrate the effectiveness of DenseLSTM.
Download: