Congratulations! NeurIPS 2019 shows that VIPL's 3 papers are accepted by this conference! NeurIPS is a top international conference on machine learning. NeurIPS 2019 will be held in Vancouver, Canada, in December 2019.
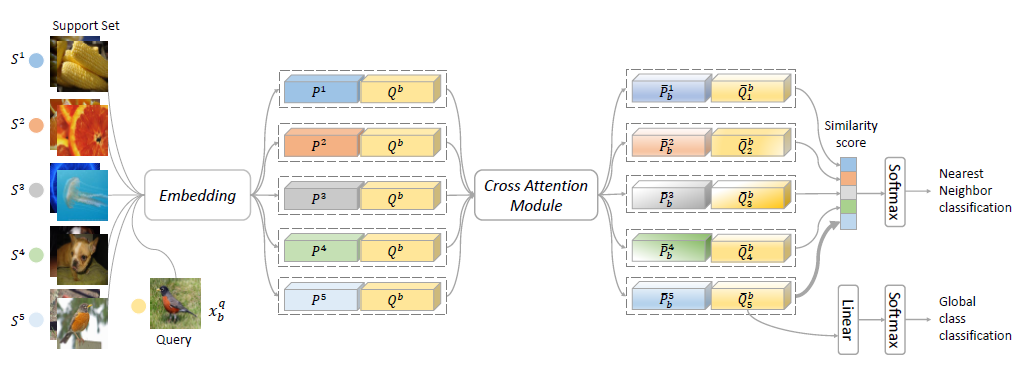
1. Cross Attention Network for Few-shot Classification (Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen)
Few-shot classification aims to recognize unlabeled samples from unseen classes given only few labeled samples. The unseen classes and low-data problem make few-shot classification very challenging. In this work, we propose a novel Cross Attention Network to address the challenging problems in few-shot classification. Firstly, Cross Attention Module is introduced to deal with the problem of unseen classes. The module generates cross attention maps for each pair of class feature and query sample feature so as to highlight the target object regions, making the extracted feature more discriminative. Secondly, a transductive inference algorithm is proposed to alleviate the low-data problem, which iteratively utilizes the unlabeled query set to augment the support set, thereby making the class features more representative. Extensive experiments on two benchmarks show our method is a simple, effective and computationally efficient framework and outperforms the state-of-the-arts.
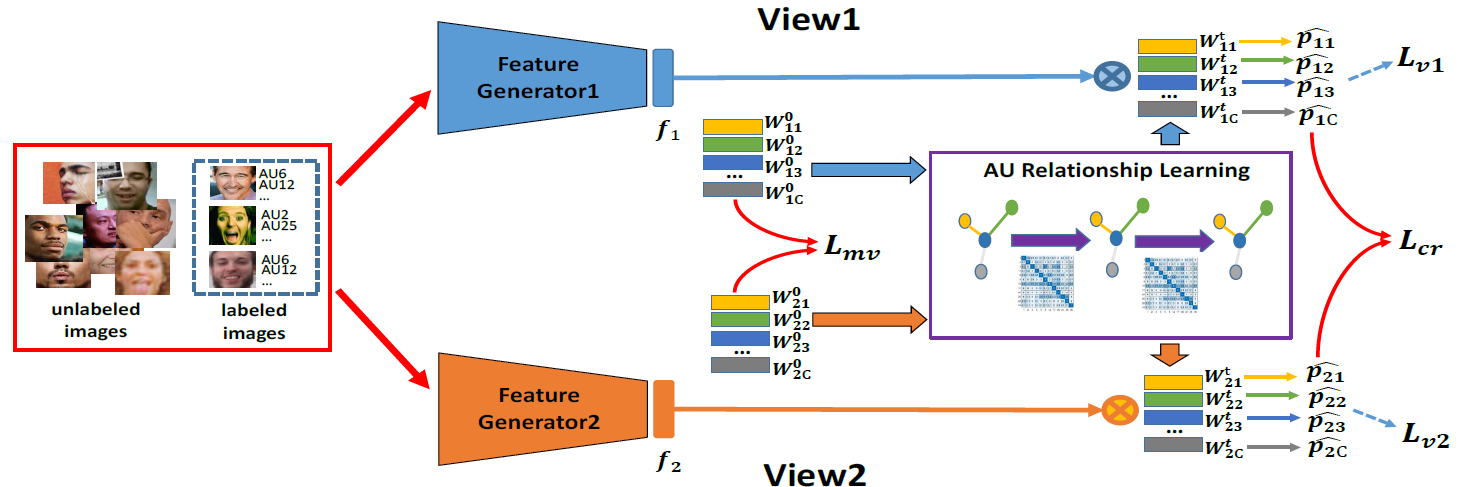
2. Multi-label Co-regularization for Semi-supervised Facial Action Unit Recognition (Xuesong Niu, Hu Han, Shiguang Shan, Xilin Chen)
Facial action units (AUs) recognition is essential for emotion analysis and has been widely applied in mental state analysis. Existing work on AU recognition usually requires big face dataset with AU labels; however, manual AU annotation requires expertise and can be time-consuming. In this work, we propose a semi-supervised approach for AU recognition utilizing a large number of web face images without AU labels and a relatively small face dataset with AU annotations inspired by the co-training methods. Unlike traditional co-training methods which require provided multi-view features and model re-training, we propose a novel co-training method, namely multi-label co-regularization, for semi-supervised facial AU recognition. Two deep neural networks are utilized to generate multi-view features for both labeled and unlabeled face images, and a multi-view loss is designed to enforce the two feature generators to get conditional independent representations. In order to constrain the prediction consistency of the two views, we further propose a multi-label co-regularization loss by minimizing the distance of the predicted AU probability distributions of two views. In addition, prior knowledge of the relationship between individual AUs is embedded through a graph convolutional network (GCN) for exploiting useful information from the big unlabeled dataset. Experiments on several benchmarks show that the proposed approach can effectively leverage massive face images without AU labels to improve the AU recognition accuracy and outperform the state-of-the-art semi-supervised AU recognition methods.
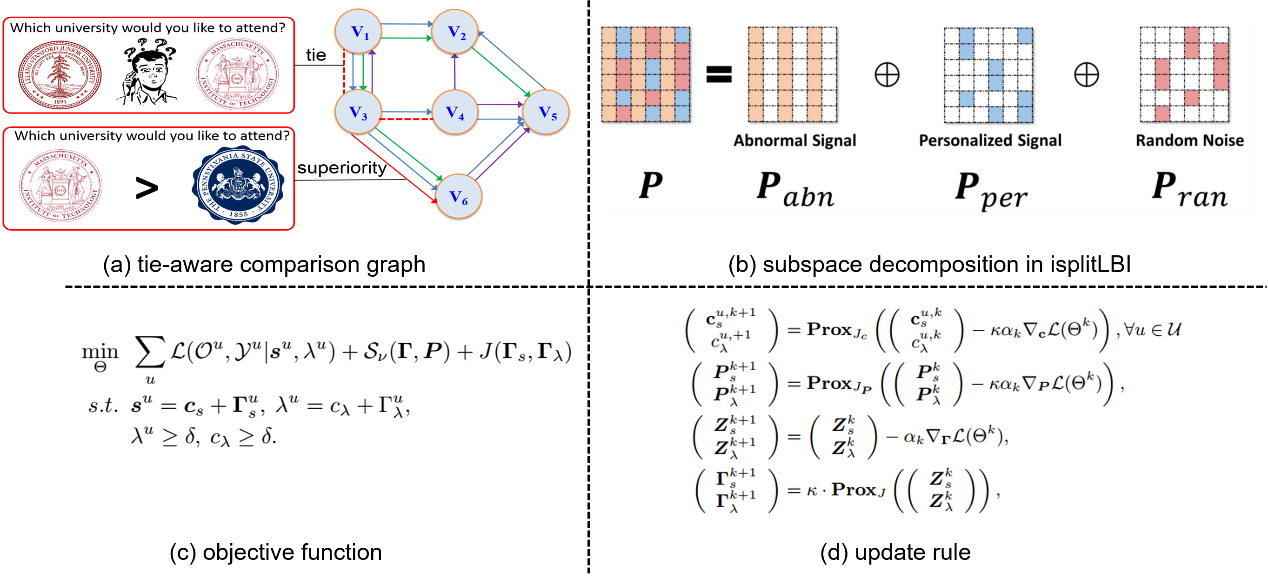
3. iSplit LBI: Individualized Partial Ranking with Ties via Split LBI (Qianqian Xu, Xinwei Sun, Zhiyong Yang, Xiaochun Cao, Qingming Huang, Yuan Yao)
Due to the inherent uncertainty of data, the problem of predicting partial ranking from pairwise comparison data with ties has attracted increasing interest in recent years. However, in real-world scenarios, different individuals often hold distinct preferences. It might be misleading to merely look at a global partial ranking while ignoring personal diversity. In this paper, instead of learning a global ranking which is agreed with the consensus, we pursue the tie-aware partial ranking from an individualized perspective. Particularly, we formulate a unified framework which not only can be used for individualized partial ranking prediction, but also be helpful for abnormal user selection. This is realized by a variable-splitting-based algorithm called iSplitLBI. Specifically, our algorithm generates a sequence of estimations with a regularization path, where both the hyperparameters and model parameters are updated. At each step of the path, the parameters can be decomposed into three orthogonal parts, namely, abnormal signals, personalized signals and random noise. The abnormal signals can serve the purpose of abnormal user selection, while the abnormal signals and personalized signals together are mainly responsible for user partial ranking prediction. Extensive experiments on simulated and real-world datasets demonstrate that our new approach significantly outperforms state-of-the-art alternatives
Download: