Congratulations! Three papers are accepted by IEEE Transactions on Image Processing (IEEE TIP).
1. Multi-Scale Multi-View Deep Feature Aggregation for Food Recognition (Shuqiang Jiang, Weiqing Min, Linhu Liu and Zhengdong Luo)
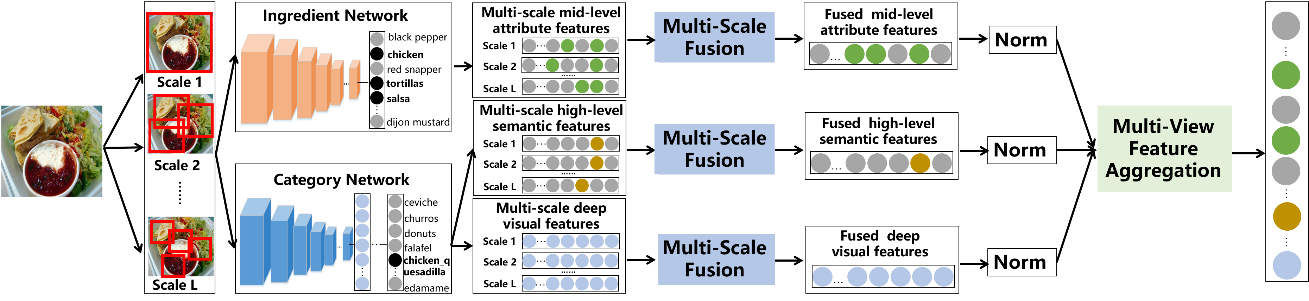
Recently, food recognition has received more and more attention in image processing and computer vision for its great potential applications in human health. In contrast to general object recognition, food images typically do not exhibit distinctive spatial arrangement and common semantic patterns. In this paper, we propose a Multi-Scale Multi-View Feature Aggregation (MSMVFA) scheme for food recognition. MSMVFA can aggregate high-level semantic features, mid-level attribute features and deep visual features into a unified representation. These three types of features describe the food image from different granularity. Therefore, the aggregated features can capture the semantics of food images with the greatest probability. For that solution, we utilize additional ingredient knowledge to obtain mid-level attribute representation via ingredient-supervised CNNs. High-level semantic features and deep visual features are extracted from class-supervised CNNs. Considering food images do not exhibit distinctive spatial layout in many cases, MSMVFA fuses multi-scale CNN activations for each type of features to make aggregated features more discriminative and invariable to geometrical deformation. Finally, the aggregated features are more robust, comprehensive and discriminative via the two-level fusion, namely multi-scale fusion for each type of features and multi-view aggregation for different types of features. In addition, MSMVFA is general and different deep networks can be easily applied into this scheme. Extensive experiments and evaluations demonstrate that our method achieves state-of-the-art recognition performance on three popular large-scale food benchmark datasets in Top-1 recognition accuracy.
2. Multi-Task Deep Relative Attribute Learning for Visual Urban Perception (Weiqing Min, Shuhuan Mei, Linhu Liu, Yi Wang, and Shuqiang Jiang)
Visual urban perception aims to quantify perceptual attributes (e.g., safe and depressing attributes) of physical urban environment from crowd-sourced street-view images and their pairwise comparisons. It has been receiving more and more attention in computer vision for various applications, such as perceptive attribute learning and urban scene understanding. Most existing methods adopt either (i) a regression model trained using image features and ranked scores converted from pairwise comparisons for perceptual attribute prediction or (ii) a pairwise ranking algorithm to independently learn each perceptual attribute. However, the former fails to directly exploit pairwise comparisons while the latter ignores the relationship among different attributes. To address them, we propose a Multi-Task Deep Relative Attribute Learning Network (MTDRALN) to learn all the relative attributes simultaneously via multi-task Siamese networks, where each Siamese network will predict one relative attribute. Combined with deep relative attribute learning, we utilize the structured sparsity to exploit the prior from natural attribute grouping, where all the attributes are divided into different groups based on semantic relatedness in advance. As a result, MTDRALN is capable of learning all the perceptual attributes simultaneously via multi-task learning. Besides the ranking sub-network, MTDRALN further introduces the classification sub-network, and these two types of losses from two sub-networks jointly constrain parameters of the deep network to make the network learn more discriminative visual features for relative attribute learning. In addition, our network can be trained in an end-to-end way to make deep feature learning and multi-task relative attribute learning reinforce each other. Extensive experiments on the large-scale Place Pulse 2.0 dataset validate the advantage of our proposed network. Our qualitative results along with visualization of saliency maps also show that the proposed network is able to learn effective features for perceptual attributes.

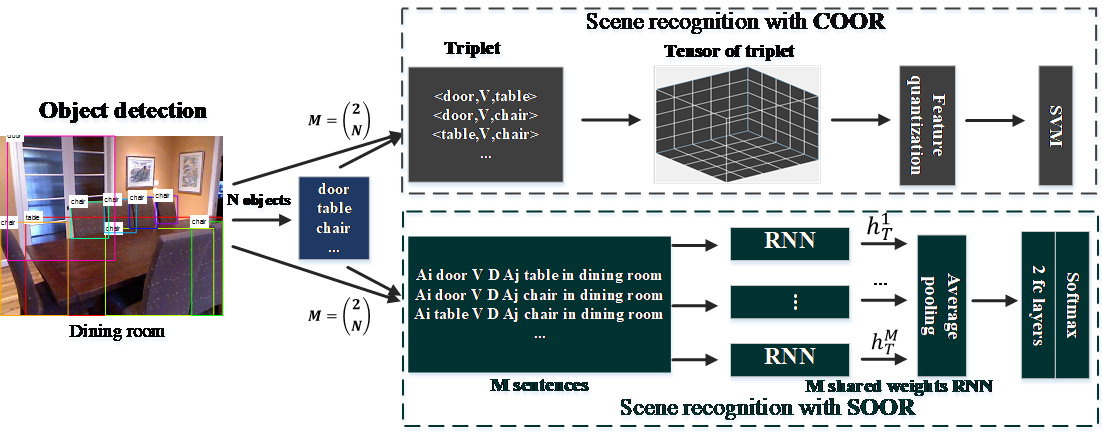
3. Image Representations with Spatial Object-to-Object Relations for RGB-D Scene Recognition. (Xinhang Song, Shuqiang Jiang, Bohan Wang, Chengpeng Chen, Gongwei Chen)
Scene recognition is challenging due to the intra-class diversity and inter-class similarity. Previous works recognize scenes either with global representations or with the intermediate representations of objects. In contrast, we investigate more discriminative image representations of object-to-object relations for scene recognition, which are based on the triplets of
Download: