Congratulations! AAAI 2020 shows that VIPL's 2 papers are accepted by this conference! AAAI is a top international conference on Artificial Intelligence. AAAI 2020 will be held in New York, the United States, in February 2020.
1. Who Likes What – SplitLBI in Exploring Preferential Diversity of Rating(Qianqian Xu, Jiechao Xiong, Zhiyong Yang, Xiaochun Cao, Qingming Huang, Yuan Yao)
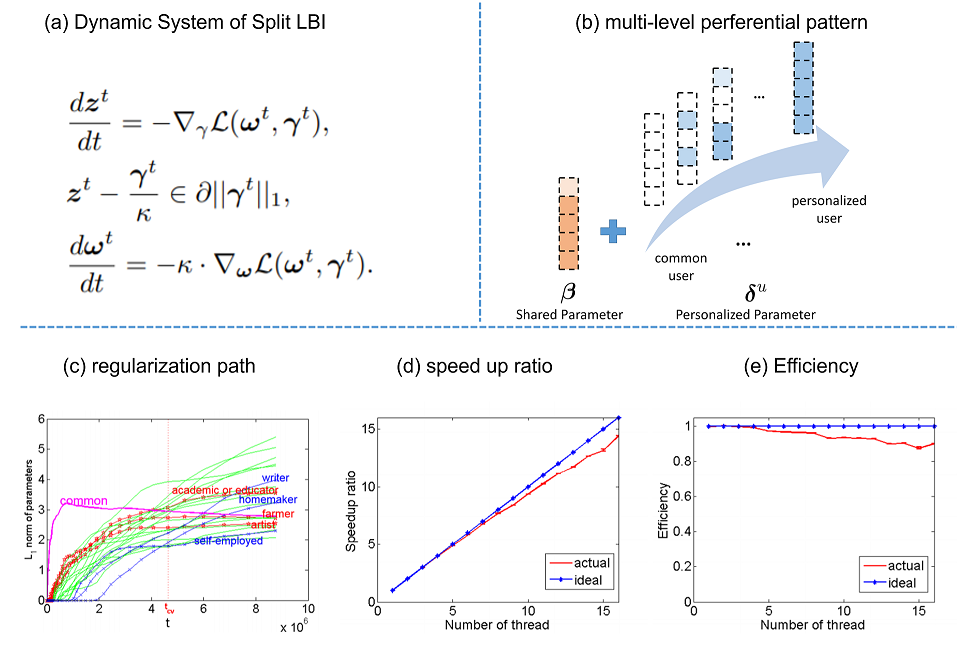
In recent years, learning user preferences has received significant attention. A shortcoming of existing learning to rankwork lies in that they do not take into account the multi-level hierarchies from social choice to individuals. In this paper, we propose a multi-level model which learns both thecommon preference or utility function over the populationbased on features of alternatives to-be-compared, and preferential diversity functions conditioning on user categories.Such a multi-level model, enables us to simultaneously learna coarse-grained social preference function together with afine-grained personalized diversity. It provides us predictionpower for the choices of new users on new alternatives. Thekey algorithm in this paper is based on Split Linearized Bregman Iteration (SplitLBI) algorithm which generates a dynamic path from the common utility to personalized preferential diversity, at different levels of sparsity on personalization. A synchronized parallel version of SplitLBI is proposedto meet the needs of fast analysis of large-scale data. The validity of the methodology are supported by experiments withboth simulated and real-world datasets such as movie anddining restaurant ratings which provides us a coarse-to-finegrained preference learning.
2. F3Net: Fusion, Feedback and Focus for Salient Object Detection(Jun Wei, Shuhui Wang, Qingming Huang)
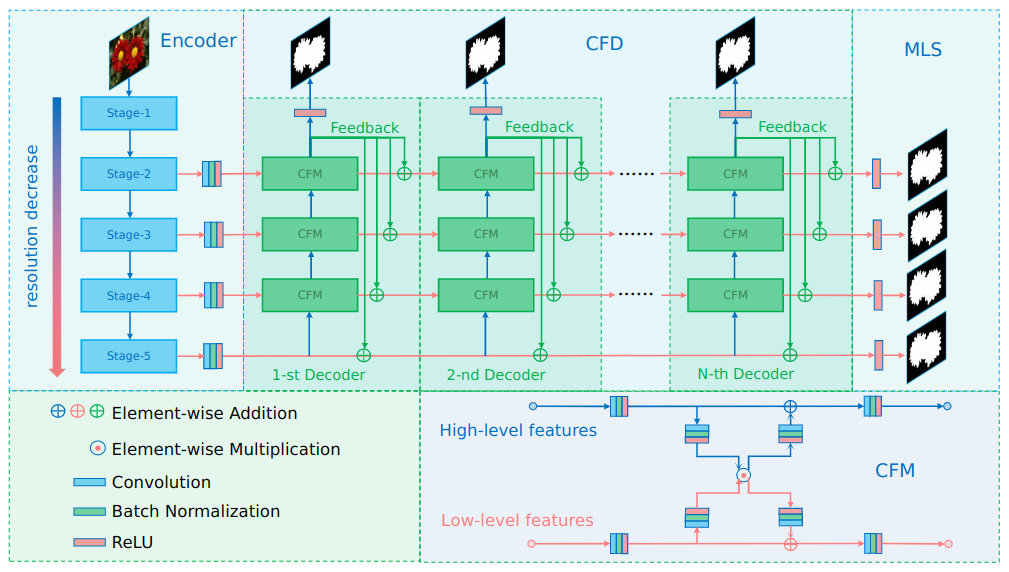
Recently, many salient object detection models are based on multi-level feature fusion. By fusing features from different convolutional layers, these models can segment salient objects accurately. However, because different convolutional layers have different receptive fields, there exists big differences between features generated by these layers. Common feature fusion strategies (addition or concatenation) ignore these differences and may cause suboptimal solutions. In this paper, we propose the F3Net to solve above problem, which consists of cross feature module (CFM), cascaded feedback decoder (CFD) and pixel position aware loss (PPA). Specifically, CFM aims to selectively aggregate multi-level features. Different from addition and concatenation, CFM adaptively selects complementary components from input features before fusion, which can effectively avoid introducing too much redundant information that may destroy the original features. Besides, CFD adopts a multi-stage feedback mechanism, where features closed to supervision will be introduced to the output of previous layers to supplement them and eliminate the differences between features. These refined features will go through multiple similar iterations before generating the final saliency maps. Furthermore, different from binary cross entropy, the proposed PPA loss doesn’t treat pixels equally, which can synthesize the local structure information of a pixel to guide the network to focus more on local details. Hard pixels from boundaries or error-prone parts will be given more attention to emphasize their importance. F3Net is able to segment salient object regions accurately and provide clear local details. Comprehensive experiments on five benchmark datasets demonstrate that F3Net outperforms state-of-the-art approaches on four evaluation metrics.
Download: