1. Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation (Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, Xilin Chen)
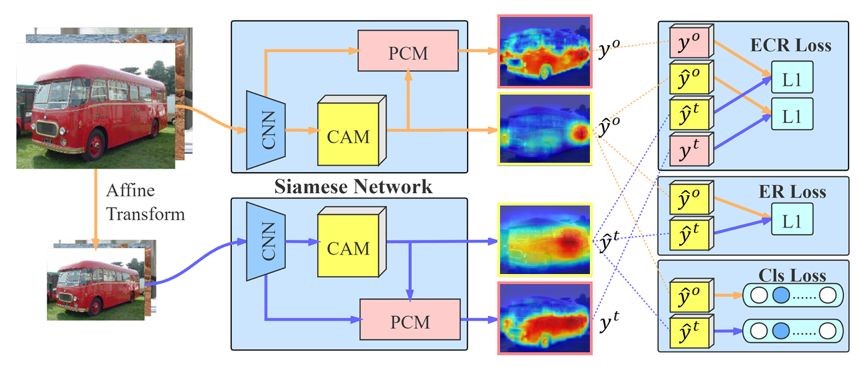
Image-level weakly supervised semantic segmentation is a challenging problem that has been deeply studied in recent years. Most of advanced solutions exploit class activation map (CAM). However, CAMs can hardly serve as the object mask due to the gap between full and weak supervisions. In this paper, we propose a self-supervised equivariant attention mechanism (SEAM) to discover additional supervision and narrow the gap. Our method is based on the observation that equivariance is an implicit constraint in fully supervised semantic segmentation, whose pixel-level labels take the same spatial transformation as the input images during data augmentation. However, this constraint is lost on the CAMs trained by image-level supervision. Therefore, we propose consistency regularization on predicted CAMs from various transformed images to provide self-supervision for network learning. Moreover, we propose a pixel correlation module (PCM), which exploits context appearance information and refines the prediction of current pixel by its similar neighbors, leading to further improvement on CAMs consistency. Extensive experiments on PASCAL VOC 2012 dataset demonstrate our method outperforms state-of-the-art methods using the same level of supervision.
2. Single-Side Domain Generalization for Face Anti-Spoofing (Yunpei Jia, Jie Zhang, Shiguang Shan, Xilin Chen)
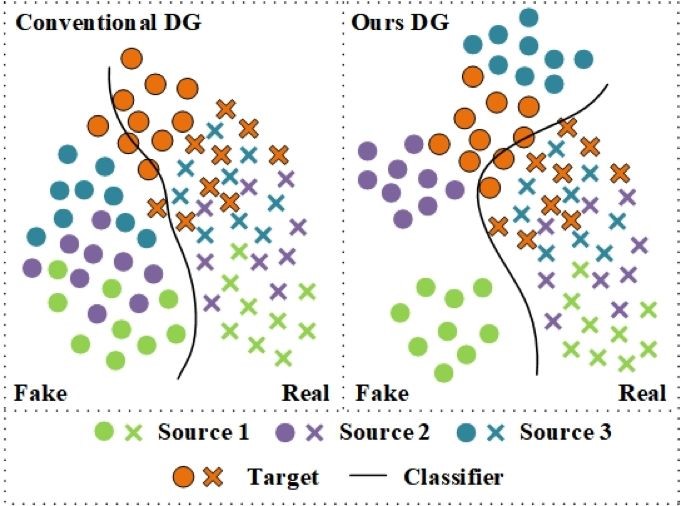
Because of the variants of domain conditions, various conventional face anti-spoofing methods fail to generalize under new testing scenarios. Existing domain generalization methods for face anti-spoofing endeavor to extract common differentiation features to improve the generalization. Due to large distribution discrepancies among fake images of different domains, seeking a compact and generalized feature space for the fake is difficult, usually leading to a sub-optimal solution. In this work, we propose an end-to-end single-side domain generalization framework to improve the generalization ability of face anti-spoofing. The main idea is to learn a generalized feature space, where the feature distribution of real is compact while the one of fake is dispersed between domains and compact within the same domain. Specifically, a feature generator is trained to make the features of different domains undistinguishable only for the real, formulating a single-side adversarial learning. Moreover, an unbalanced triplet loss is conducted to constrain the fake images of different domains separated while the real ones aggregated. The two key points above are integrated into a unified framework under an end-to-end training manner, resulting in a more generalized class boundary, which performs well on unseen databases. Feature and weight normalization is incorporated to further improve the generalization ability. Extensive experiments show that our proposed approach is effective and achieves state-of-the-art results on four public databases.
3. Cross-domain Face Presentation Attack Detection via Multi-domain Disentangled Representation Learning (Guoqing Wang, Hu Han, Shiguang Shan, Xilin Chen)
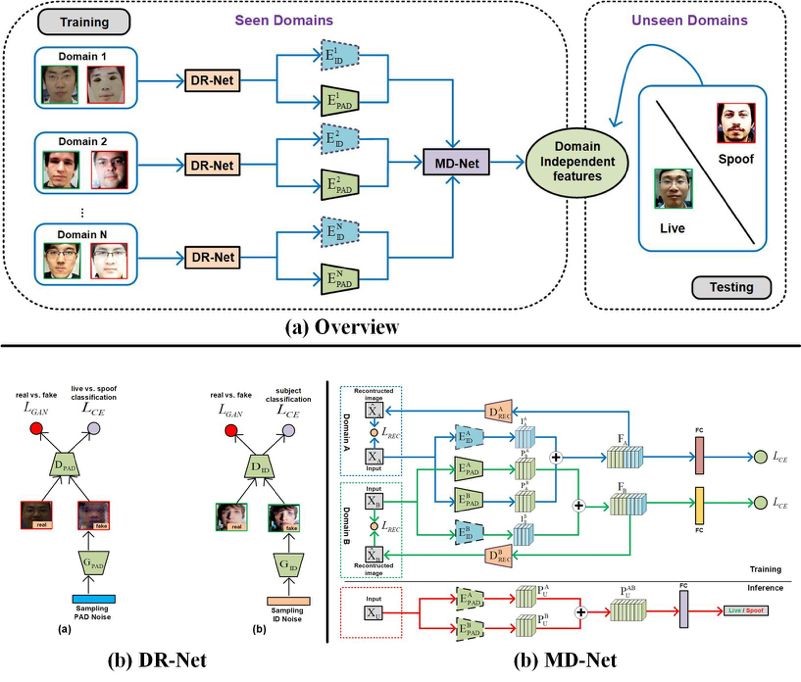
Face presentation attack detection (PAD) has been an urgent problem to be solved in the face recognition systems. Conventional approaches usually assume the testing and training are within the same domain; as a result, they may not generalize well into unseen scenarios because the representations learned for PAD may overfit to the subjects in the training set. In light of this, we propose an efficient disentangled representation learning for cross-domain face PAD. Our approach consists of disentangled representation learning (DR-Net) and multi-domain learning (MD-Net). DR-Net learns a pair of encoders via generative models that can disentangle PAD informative features from subject discriminative features. The disentangled features from different domains are fed to MD-Net which learns domain-independent features for the final cross-domain face PAD task. Extensive experiments on several public datasets validate the effectiveness of the proposed approach for cross-domain PAD.
4. An Efficient PointLSTM Network for Point Clouds based Gesture Recognition (Yuecong Min, Yanxiao Zhang, Xiujuan Chai, Xilin Chen)
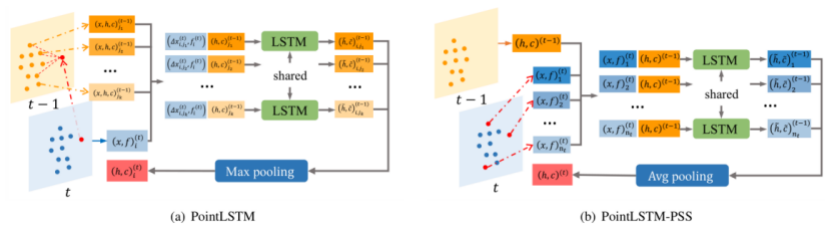
Point clouds contain rich spatial information, which provides complementary cues for gesture recognition. In this paper, we formulate gesture recognition as an irregular sequence recognition problem and aim to capture long-term spatial correlations across point cloud sequences. A novel and effective PointLSTM is proposed to propagate information from past to future while preserving the spatial structure. The proposed PointLSTM combines state information from neighboring points in the past with current features to update the current states by a weight-shared LSTM layer. This method can be integrated into many other sequence learning approaches. In the task of gesture recognition, the proposed PointLSTM achieves state-of-the-art results on two challenging datasets (NVGesture and SHREC\'17) and outperforms previous skeleton-based methods. To show its advantages in generalization, we evaluate our method on MSR Action3D dataset, and it produces competitive results with previous skeleton-based methods.
5. Multi-Modal Graph Neural Network for Joint Reasoning on Vision and Scene Text (Difei Gao, Ke li, Ruiping Wang, Shiguang Shan, Xilin Chen)
The texts in a scene convey rich information that is crucial for performing daily tasks like finding a place, acquiring information about a product, etc. An advanced Visual Question Answering (VQA) model which is able to reason over scene texts and other visual contents could have extensive applications in practice, such as assisting visually impaired users, and education of children.
Answering questions that require reading texts in an image is challenging for current models. One key difficulty of this task is that rare, polysemous, and ambiguous words frequently appear in images, e.g. names of places, products, and sports teams. To overcome this difficulty, only resorting to pre-trained word embedding models is far from enough. A desired model should utilize the rich information in multiple modalities of the image to help understand the meaning of scene texts, e.g. the prominent text on a bottle is most likely to be the brand.
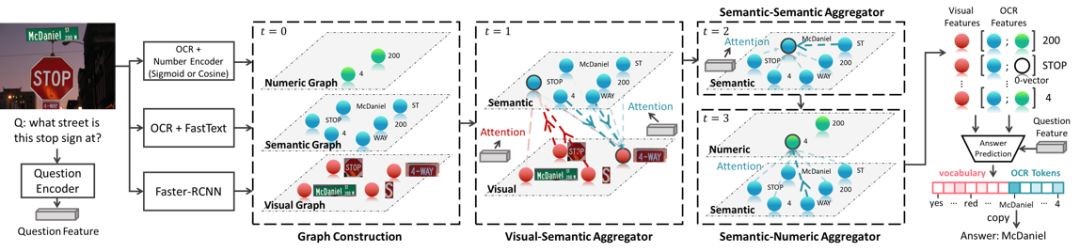
6. TCTS: A Task-Consistent Two-stage Framework for Person Search (Cheng Wang,Bingpeng Ma,Hong Chang, Shiguang Shan, Xilin Chen)
The state of the art person search methods separate person search into detection and re-ID stages, but ignore the consistency between these two stages. The general person detector has no special attention on the query target; The re-ID model is trained on hand-drawn bounding boxes which are not available in person search. To address the consistency problem, we introduce a Task-Consist Two-Stage (TCTS) person search framework, includes an identity-guided query (IDGQ) detector and a Detection Results Adapted (DRA) re-ID model. In the detection stage, the IDGQ detector learns an auxiliary identity branch to compute query similarity scores for proposals. With consideration of the query similarity scores and foreground score, IDGQ produces query-like bounding boxes for the re-ID stage. In the re-ID stage, we predict identity labels of detected bounding boxes, and use these examples to construct a more practical mixed train set for the DRA model. Training on the mixed train set improves the robustness of the reID stage to inaccurate detection. We evaluate our method on two benchmark datasets, CUHK-SYSU and PRW. Our framework achieves 93.9% of mAP and 95.1% of rank1 accuracy on CUHK-SYSU, outperforming the previous state of the art methods.
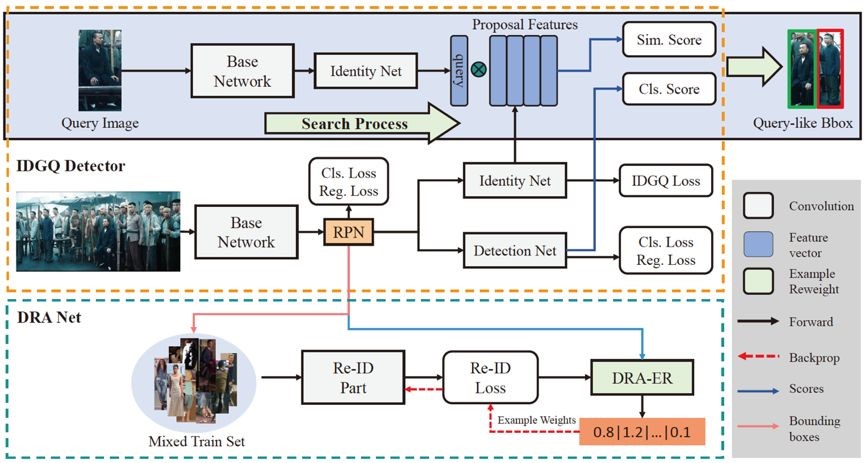
7. Unsupervised Domain Adaptation with Hierarchical Gradient Synchronization (Lanqing Hu,Meina Kan, Shiguang Shan, Xilin Chen)
Domain adaptation attempts to boost the performance on a target domain by borrowing knowledge from a well established source domain. It is known that after a perfect domain alignment the domain-invariant representations of two domains should share the same characteristics from perspective of the overview and also any local piece. Inspired by this, we propose a novel method called Hierarchical Gradient Synchronization to model the synchronization relationship among the local distribution pieces and global distribution. Specifically, the hierarchical domain alignments including class-wise alignment, group-wise alignment and global alignment are first constructed. Then, these three types of alignment are constrained to be consistent to ensure better structure preservation. As evaluated on extensive domain adaptation tasks, our proposed method achieves state-of-the-art classification performance on both vanilla unsupervised domain adaptation and partial domain adaptation.

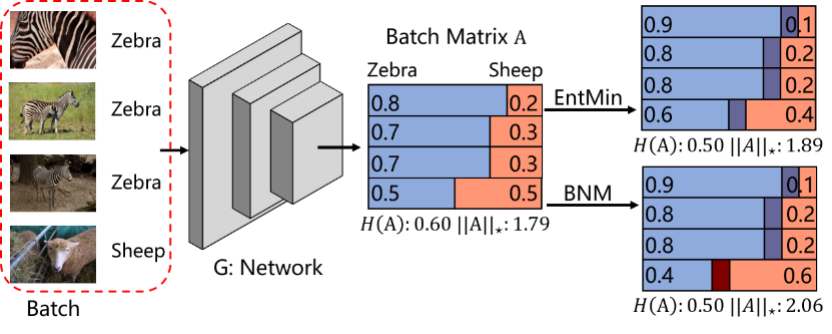
8. Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations (Shuhao Cui, Shuhui Wang, Junbao Zhuo, liang li, Qingming Huang, Qi Tian)
The learning of the deep networks largely relies on the data with human-annotated labels. In some label insufficient situations, the performance degrades on the decision boundary with high data density. A common solution is to directly minimize the Shannon Entropy, but the side effect caused by entropy minimization, i.e., reduction of the prediction diversity, is mostly ignored. To address this issue, we reinvestigate the structure of classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. Besides, the nuclear-norm is an upperbound of the Frobenius-norm, and a convex approximation of the matrix rank. Accordingly, to improve both discriminability and diversity, we propose Batch Nuclear-norm Maximization (BNM) on the output matrix. BNM could boost the learning under typical label insufficient learning scenarios, such as semi-supervised learning, domain adaptation and open domain recognition. On these tasks, extensive experimental results show that BNM outperforms competitors and works well with existing well-known methods.
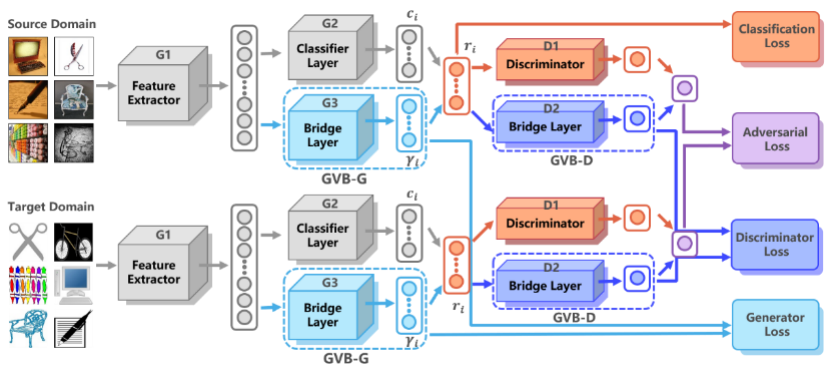
9. Gradually Vanishing Bridge for Adversarial Domain Adaptation (Shuhao Cui, Shuhui Wang, Junbao Zhuo, Chi Su, Qingming Huang, Qi Tian)
In unsupervised domain adaptation, rich domain-specific characteristics bring great challenge to learn domain-invariant representations. However, domain discrepancy is considered to be directly minimized in existing solutions, which is difficult to achieve in practice. Some methods alleviate the difficulty by explicitly modeling domain-invariant and domain-specific parts in the representations, but the adverse influence of the explicit construction lies in the residual domain-specific characteristics in the constructed domain-invariant representations. In this paper, we equip adversarial domain adaptation with Gradually Vanishing Bridge (GVB) mechanism on both generator and discriminator. On the generator, GVB could not only reduce the overall transfer difficulty, but also reduce the influence of the residual domain-specific characteristics in domain-invariant representations. On the discriminator, GVB contributes to enhance the discriminating ability, and balance the adversarial training process. Experiments on three challenging datasets show that our GVB methods outperform strong competitors, and cooperate well with other adversarial methods.
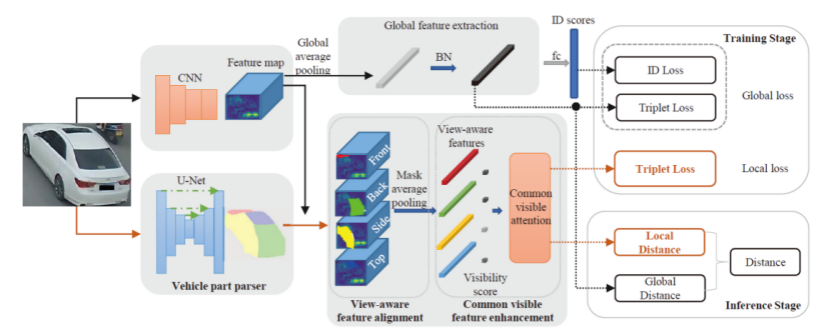
10. Parsing-based View-aware Embedding Network for Vehicle Re-Identification ( Dechao Meng, Liang Li, Xuejing Liu, Yadong Li, Shijie Yang, Zheng-Jun Zha, Xingyu Gao, Shuhui Wang, and Qingming Huang )
With the promotion of the requirements of smart surveillance and AI City, the vehicle ReID has attracted the attention of the researchers recently. The traditional methods commonly extract the global features for a vehicle image and calculate the distance of different images based on this distance. Such a scheme ignores the visual difference caused by the viewpoint perspective of the vehicle, which will lead to large intra-instance distance and subtle inter-instance discrepancy. To solve this problem, we proposed a parsing-based view-aware embedding network (PVEN). In detail, PVEN uses a parsing sub-model to parse a vehicle into different parts, namely front, back, side and top. Then we apply the four masks in the feature map extracted by a deep convolutional neural network respectively and get the local features of different views. The operation decouples the features under different perspectives. Besides, we proposed common-visible feature alignment. In detail, we normalize the distances of the four local features by the product of the area corresponding to each mask. The enhancement takes the advantages of the perspective relationship between two compared images, which eases the feature misalignment in the distance calculation procedure. Our PVEN achieves the best performance in three main-stream vehicle ReID benchmarks.
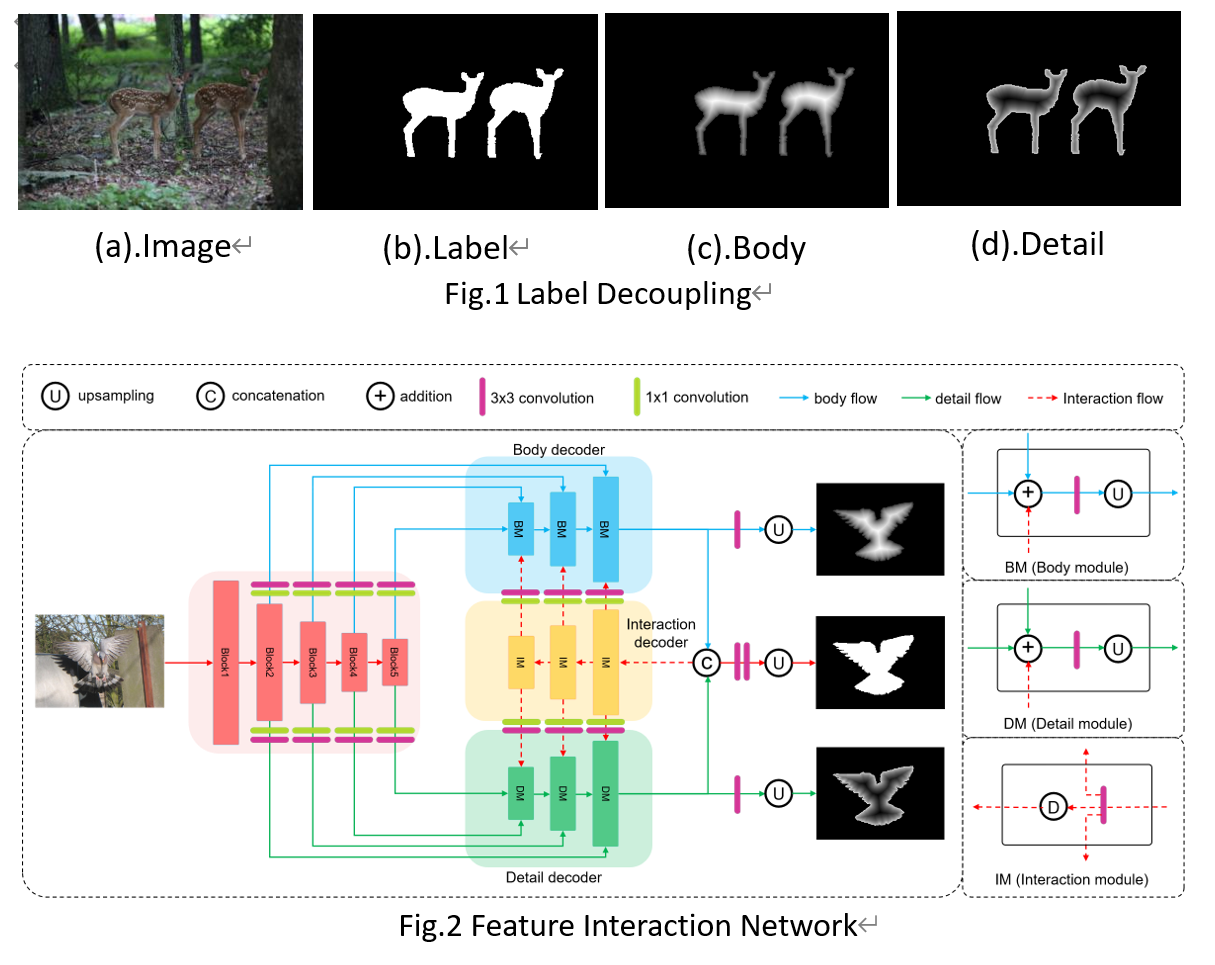
11. Label Decoupling Framework for Salient Object Detection (Jun Wei, Shuhui Wang, Zhe Wu, Chi Su, Qingming Huang, Qi Tian)
To get more accurate saliency maps, recent methods mainly focus on aggregating multi-level features from fully convolutional network (FCN) and introducing edge information as auxiliary supervision. Though these methods have achieved remarkable progress, we observe that the closer the pixel is to the edge, the more difficult it is to predict, because edge pixels have an very imbalance distribution. To address this problem, we propose a Label Decoupling Framework (LDF) which mainly consists of label decoupling (LD) and feature interaction network (FIN). As shown in Fig.1, LD explicitly decomposes the original saliency map into body map and detail map, where body map concentrates on center areas and detail map focuses on small region around edges. Different from traditional edge supervision, detail map works better for it involving in much more pixels than the edge map. Different from saliency label, body map discards edge pixels and only pay attention to center areas. This successfully avoids the harmful effects from edge pixels during training. Besides, FIN develops two branches to deal with body map and detail map respectively, as shown in Fig.2. Considering the complementarity of these two maps, feature interaction (FI) is designed to fuse the two branches to predict the saliency map, which is then used to refine the two branches. This iterative refinement is helpful for learning better representations and segmenting more precise saliency maps. Comprehensive experiments on six benchmark datasets demonstrate that the proposed algorithm outperforms state-of-the-art approaches on different evaluation metrics.
Download: