Congratulations! ACM MM 2020 shows that there are VIPL's 7 papers are accepted! ACM MM is the premier international conference in multimedia. ACM MM 2020 will be held in Seattle, United States, in October 2020.
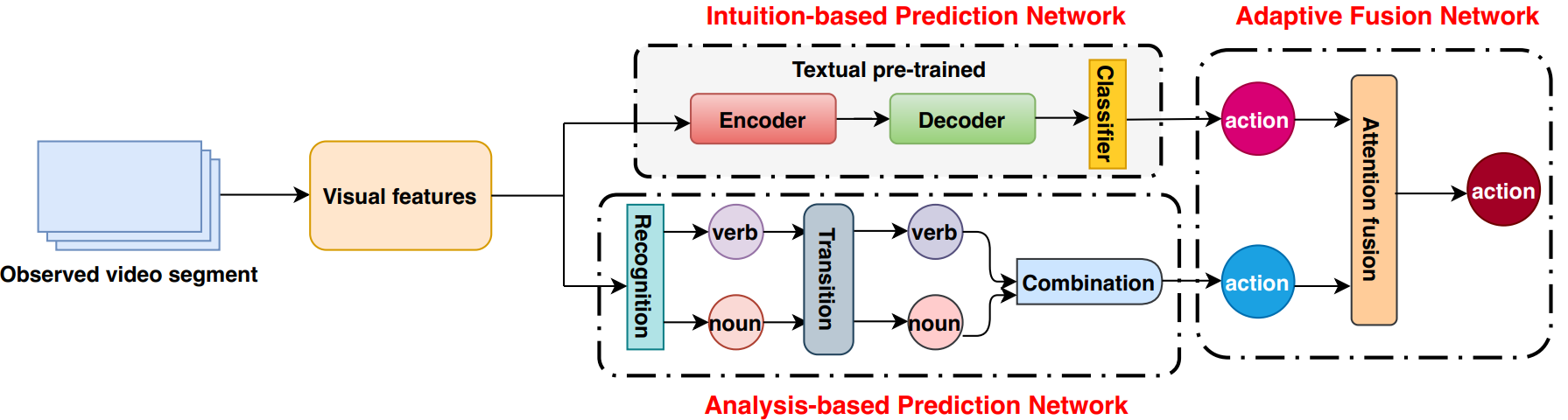
1. An Egocentric Action Anticipation Framework via Fusing Intuition and Analysis (Tianyu Zhang, Weiqing Min, Ying Zhu, Yong Rui, Shuqiang Jiang)
Inspired by psychological research, we propose one Intuition-Analysis Integrated framework for the task of egocentric action anticipation. The framework mainly consists of three parts: Intuition-based Prediction Network (IPN), Analysis-based Prediction Network (APN) and Adaptive Fusion Network (AFN). We design the IPN as an encoder-decoder structure which is analogous to black-box, and we adopt one textual pre-training strategy on the basis of using visual information. On the other hand, we design the APN as a three-step pipeline of recognition-transition-combination and considers the co-occurrence statistical relationship between verbs and nouns, which compose egocentric actions. By introducing attention mechanism in AFN, we can adaptively fuse the predicted results from IPN and APN. Experiments show the effectiveness of our proposed IAI framework and demonstrate the advantage of our method in egocentric action anticipation.
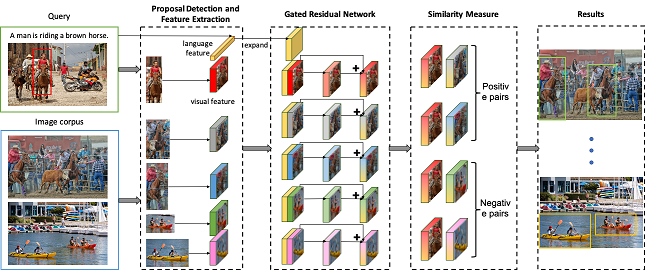
2. Expressional Region Retrieval (Xiaoqian Guo, Xiangyang Li, Shuqiang Jiang)
Image retrieval is a long-standing topic in the multimedia community due to its various applications, e.g., product search and artworks retrieval in museum. The regions in images contain a wealth of information. Users may be interested in the objects presented in the image regions or the relationships between them. But previous retrieval methods are either limited to the single object of images, or tend to the entire visual scene. In this paper, we introduce a new task called expressional region retrieval, in which the query is formulated as a region of image with the associated description. The goal is to find images containing the similar content with the query and localize the regions within them. As far as we know, this task has not been explored yet. We propose a framework to address this issue. The region proposals are first generated based on region detectors and language features are extracted. Then the Gated Residual Network (GRN) takes language information as a gate to control the transformation of visual features. In this way, the combined visual and language representation is more specific and discriminative for expressional region retrieval. We evaluate our method on a new established benchmark which is constructed based on the Visual Genome dataset. Experimental results demonstrate that our model effectively utilizes both visual and language information, outperforming the baseline methods.
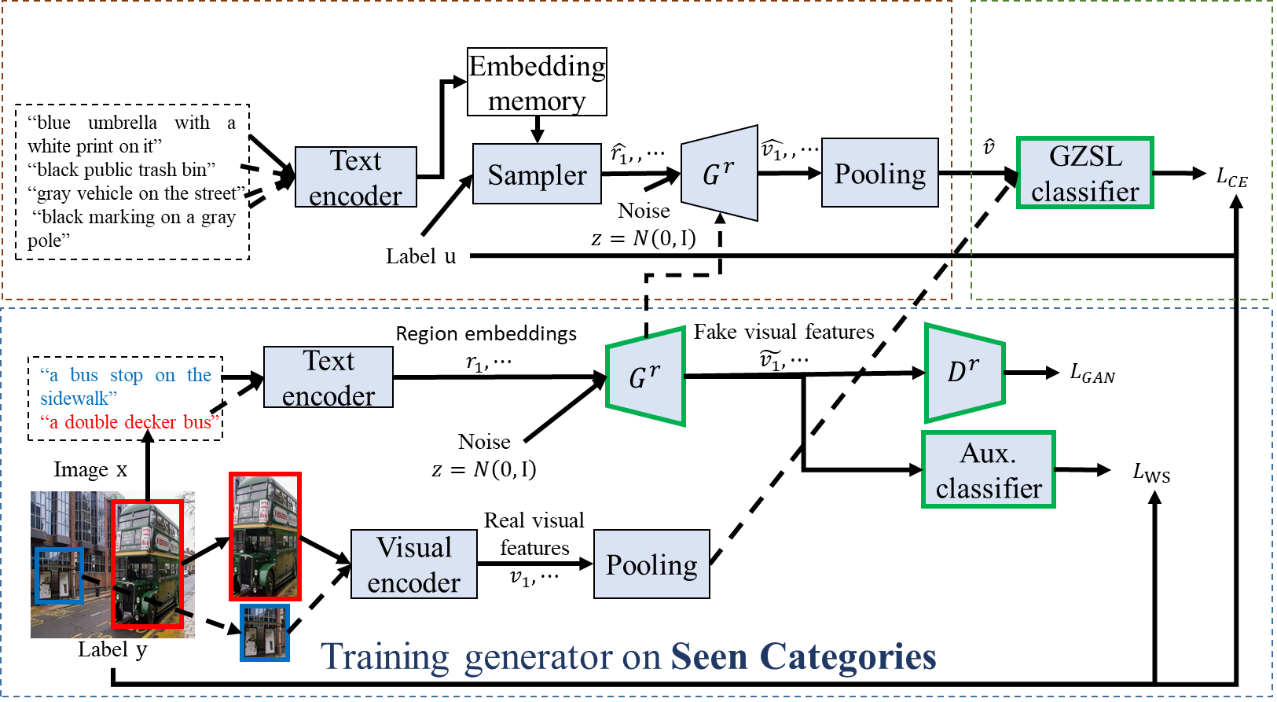
3. Generalized Zero-shot Learning with Multi-source Semantic Embeddings for Scene Recognition (Xinhang Song, Haitao Zeng, Sixian Zhang, Luis Herranz, Shuqiang Jiang)
Recognizing visual categories from semantic descriptions is a promising way to extend the capability of a visual classifier beyond the concepts represented in the training data (i.e. seen categories). This problem is addressed by (generalized) zero-shot learning methods (GZSL), which leverage semantic descriptions that connect them to seen categories (e.g. label embedding, attributes). Conventional GZSL are designed mostly for object recognition. In this paper we focus on zero-shot scene recognition, a more challenging setting with hundreds of categories where their differences can be subtle and often localized in certain objects or regions. Conventional GZSL representations are not rich enough to capture these local discriminative differences. Addressing these limitations, we propose a feature generation framework with two novel components: 1) multiple sources of semantic information (i.e. attributes, word embeddings and descriptions), 2) region descriptions that can enhance scene discrimination. To generate synthetic visual features we propose a two-step generative approach, where local descriptions are sampled and used as conditions to generate visual features. The generated features are then aggregated and used together with real features to train a joint classifier. In order to evaluate the proposed method, we introduce a new dataset for zero-shot scene recognition with multi-semantic annotations. Experimental results on the proposed dataset and SUN Attribute dataset illustrate the effectiveness of the proposed method.
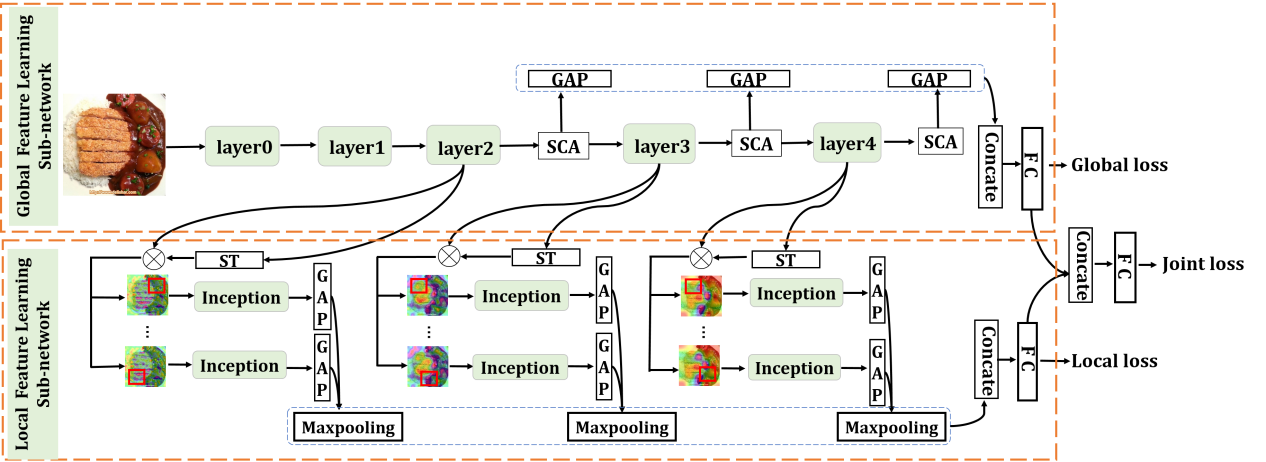
4. ISIA Food-500: A dataset for Large-Scale Food Recognition via Stacked Global-Local Attention Network (Weiqing Min, Linhu Liu, Zhiling Wang, Zhengdong Luo, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang)
Food recognition has various of applications in the multimedia community. To encourage further progress in food recognition, we introduce a new food dataset called ISIA Food-500. The dataset contains 500 categories and about 400,000 images and it is a more comprehensive food dataset that surpasses exiting benchmark datasets by category coverage and data volume. We further propose a new network, namely Stacked Global-Local Attention Network(SGLANet) to jointly learn food-oriented global and local visual features for food recognition. SGLANet consists of two sub-networks, namely Global Feature Learning Subnetwork(GloFLS) and Local Feature Learning Subnetwork(LocFLS). GloFLS first utilizes hybrid spatial-channel attention to obtain more discriminative features for each layer, and then aggregates these features from different layers into global-level features. LocFLS generates attentional regions from different regions via cascaded Spatial Transformers(STs), and further aggregates these multi-scale regional features from different layers into local-level representation. These two types of features are finally fused as comprehensive representation for food recognition. Extensive experiments on ISIA Food-500 and other two popular benchmark datasets demonstrate the effectiveness of our proposed method.
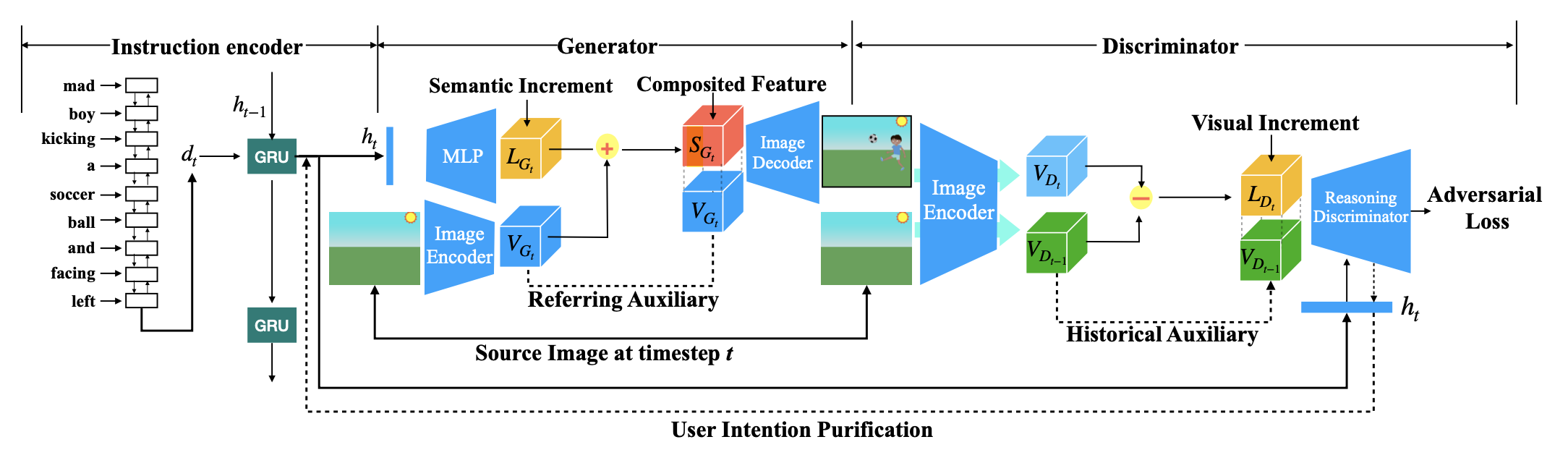
5. IR-GAN: Image Manipulation with Linguistic Instruction by Increment Reasoning(Zhenhuan Liu, Liang Li, Shaofei Cai, Jincan Deng, Qianqian Xu, Shuhui Wang, Qingming Huang )
Conditional image generation is an active research topic including text2image and image translation. Recently image manipulation with linguistic instruction brings new challenges of multimodal conditional generation. However, traditional conditional image generation models mainly focus on generating high-quality and visually realistic images, and lack resolving the partial consistency between image and instruction. To address this issue, we propose an Increment Reasoning Generative Adversarial Network (IR-GAN), which aims to reason the consistency between visual increment in images and semantic increment in instructions.
First, we introduce the word-level and instruction-level instruction encoders to learn user's intention from history-correlated instructions as semantic increment.
Second, we embed the representation of semantic increment into that of source image for generating target image, where source image plays the role of referring auxiliary. Finally, we propose a reasoning discriminator to measure the consistency between visual increment and semantic increment, which purifies user's intention and guarantees the good logic of generated target image. Extensive experiments and visualization conducted on two datasets show the effectiveness of IR-GAN.
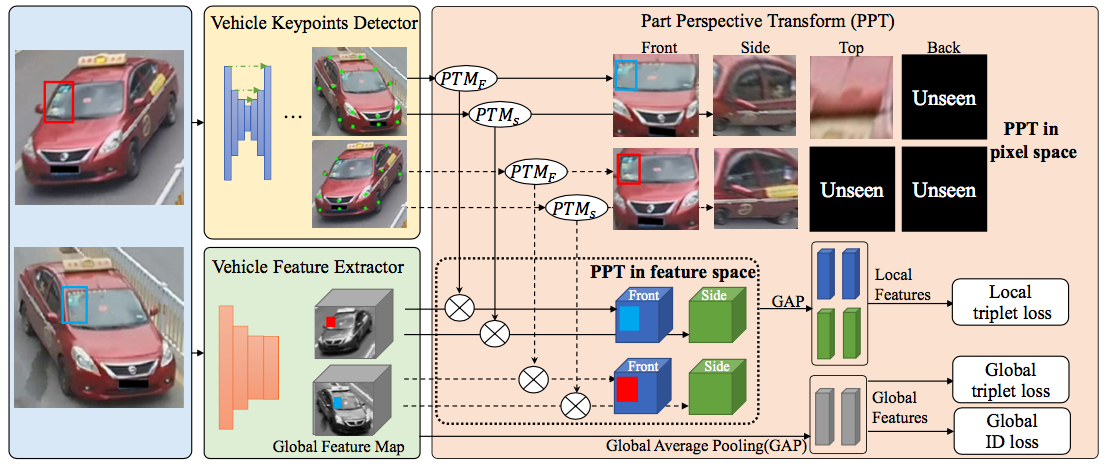
6. Fine-grained Feature Alignment with Part Perspective Transformation for Vehicle ReID (Dechao Meng, Liang Li, Shuhui Wang, Xingyu Gao, Zheng-Jun Zha, Qingming Huang)
Viewpoint variation is a main concern problem for vehicle ReID tasks. For the vehicle images taken in different viewpoints, the visual appearance would be different, which causes severe feature misalignment and feature deformation problem. Traditional methods use the original image as the input. When comparing two images under different perspective, these methods cannot model the differences, which reduces the accuracy of vehicle ReID. In our paper, we proposed a new module called part perspective transform (PPT) to handle the problem of the perspective variation problem. We first locate the different regions by keypoints detection. For different regions, we conduct perspective transform for each part to transform them to a uniform perspective individually, which solves the feature misalignment and deformation problem. As the visible regions of different vehicles are different, we design dynamic selective batch hard triplet loss, which is to select the hardest visible regions in a batch to generate triplets and filter the invalid triplets dynamically. The loss guide the network to focus on the common visible regions. Our method achieves best results in three different vehicle ReID datasets, which shows the effectiveness of our method.
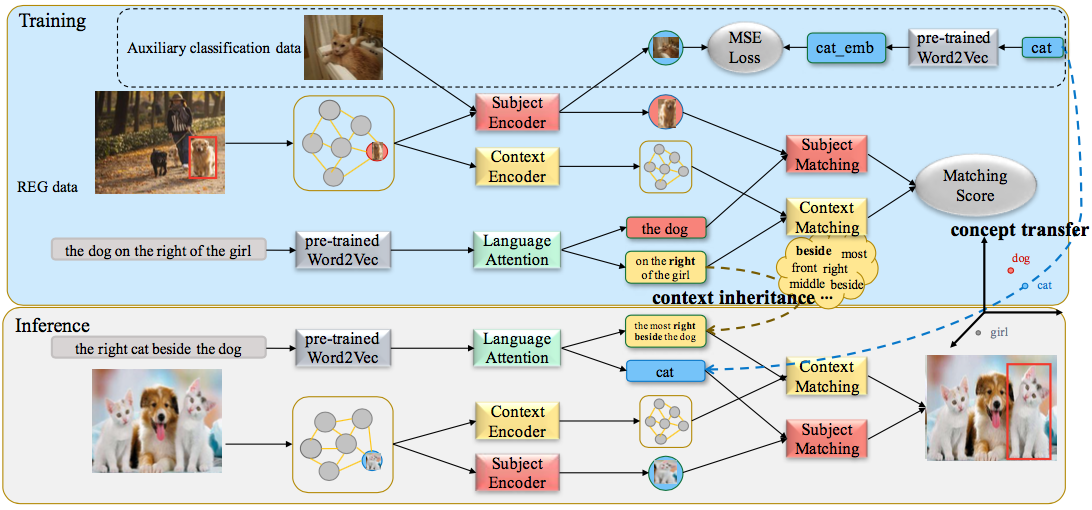
7. Transferrable Referring Expression Grounding with Concept Transfer and Context Inheritance (Xuejing Liu, Liang Li, Shuhui Wang, Zheng-Jun Zha, Dechao Meng, Qingming Huang)
Referring Expression Grounding (REG) aims at localizing a particular object in an image according to a language expression. Recent REG methods have achieved promising performance, but most of them are constrained to limited object categories due to the scale of current REG datasets. In this paper, we explore REG in a new scenario, where the REG model can ground novel objects out of REG training data. With this motivation, we propose a Concept-Context Disentangled network (CCD) which transfers concepts from auxiliary classification data with new categories meanwhile inherits context from REG data to ground new objects. Specially, we design a subject encoder to learn a cross-modal common semantic space, which can bridge the semantic and domain gap between auxiliary classification data and REG data. This common space guarantees CCD can transfer and recognize novel categories. Further, we learn the correspondence between image proposal and referring expression upon location and relationship. Bene ting from the disentangled structure, the context is relatively independent of the subject, so it can be better inherited from the REG training data. Finally, a language attention is learned to adaptively assign different importance to subject and context for grounding target objects. Experiments on four REG datasets show our method outperforms the compared approach on the new-category test datasets.