Recently, one paper on language-based person search is accepted by
the journal IEEE TIP. The full name of IEEE TIP is Transactions on Image
Processing, which is an international journal on computer vision and image
processing with an impact factor of 6.79 announced in 2020. The paper
information is as follow:
Yucheng Chen, Rui Huang, Hong Chang, Chuanqi Tan, Tao Xue and
Bingpeng Ma. “Cross-Modal Knowledge Adaptation for Language-Based Person Search”,
IEEE Transactions on Image Processing (TIP), 2021. (Accepted)
Language-based person search is a challenging
retrieval task. The inconsistent representation of different modalities makes
it difficult to directly measure the similarity between visual images and
textual descriptions. The common representation learning methods have achieved
certain success on this task. Most of the common representation learning
methods project image features and text features into a shared space in an
equal manner. However, the information contained in an image and a text is not
equal. Since text provides a description of the person in an image, it
summarizes partial image information. In other words, images contain
image-specific information that is rarely described by texts. Unequal amount of
information of image and text will result in redundancy of image information
and difficulty in aligning features across different modalities. Image-specific
information may also be detrimental to the learning of image representation.
Considering that text can be used to guide image features to enrich them with
important person details while avoiding the interference of image-specific
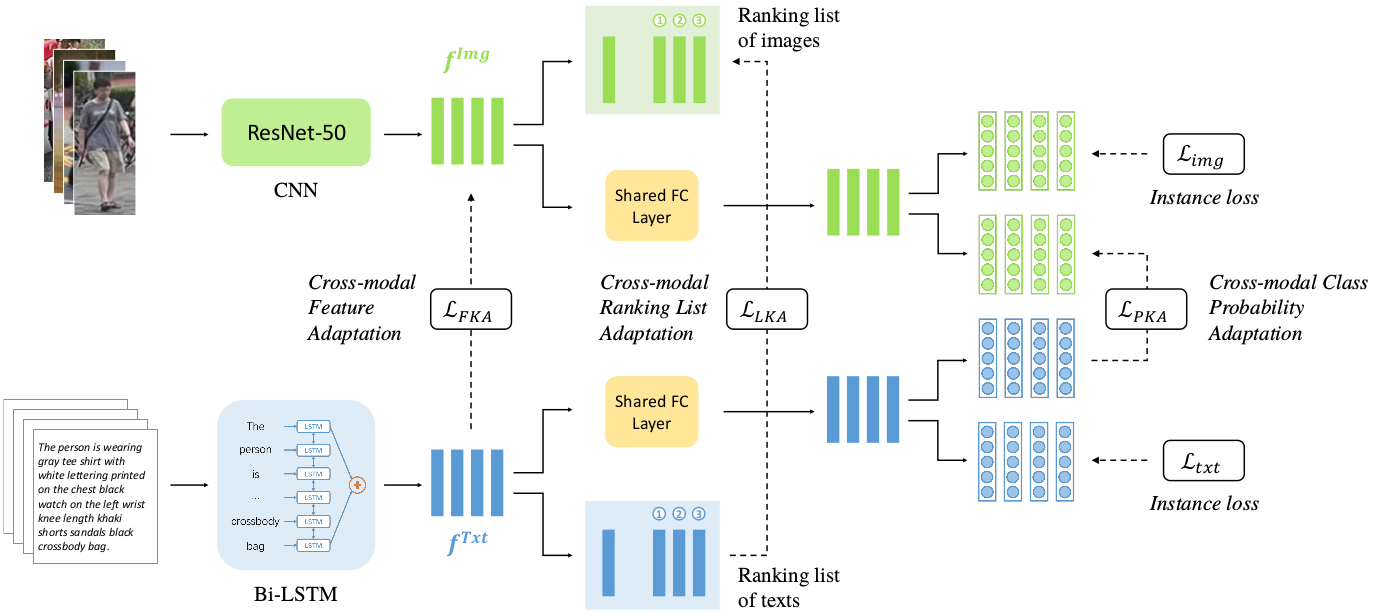
information, in this paper, we propose a method named Cross-Modal Knowledge
Adaptation (CMKA). Specially, text-to-image guidance is obtained at different
levels: individuals, lists, and classes. By combining these levels of knowledge
adaptation, the image-specific information is suppressed, and the common space
of image and text is better constructed. The overall framework of CMKA is as
follows:
In summary, the main contributions of this work include: 1) A cross-modal
knowledge adaptation method is proposed. By combining different levels of
knowledge adaptation, the information between modalities is balanced and more
textual-visual correspondences are learned; 2) The effectiveness of CMKA is
verified on the language-based person search dataset; 3) The effectiveness of CMKA
is verified on the different retrieval tasks (including image-text
bi-directional retrieval and image-to-text re-ID).