Congratulations! VIPL's 4 papers are accepted by CVPR 2021! CVPR is a top international conference on computer vision, pattern recognition and artificial intelligence hosted by IEEE.
1. Rethinking Graph Neural Architecture Search from Message-passing (Shaofei Cai, Liang Li, Jincan Deng, Beichen Zhang, Zheng-Jun Zha, Li Su, Qingming Huang)
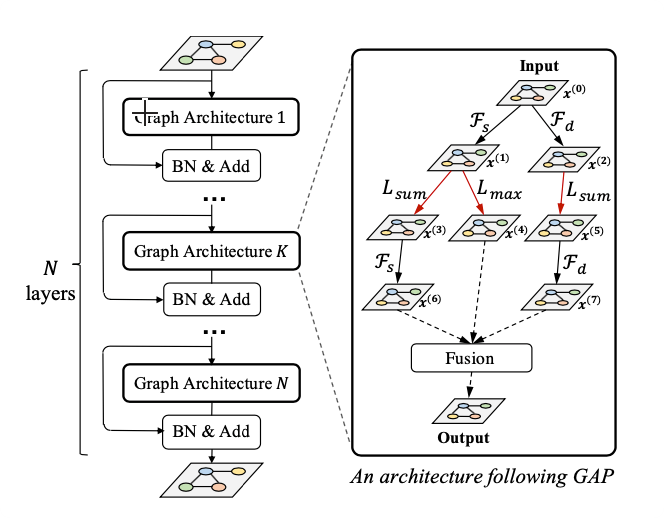
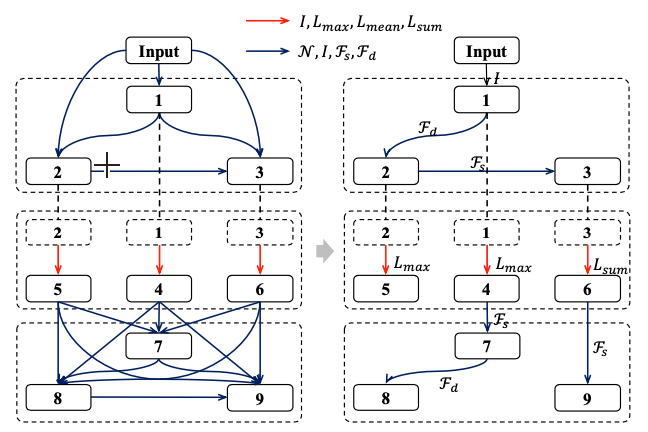
Graph neural networks (GNNs) emerged recently as a standard toolkit for learning from data on graphs. Current GNN designing works depend on immense human expertise to explore different message-passing mechanisms and require manual enumeration to determine the proper message-passing depth. Inspired by the strong searching capability of neural architecture search (NAS) in CNN, this paper proposes Graph Neural Architecture Search (GNAS) with novel-designed search space. The GNAS can automatically learn better architecture with the optimal depth of message passing on the graph. Specifically, we design Graph Neural Architecture Paradigm (GAP) with tree- topology computation procedure and two types of fine-grained atomic operations (feature filtering & neighbor aggregation) from message-passing mechanism to construct powerful graph network search space. Feature filtering performs adaptive feature selection, and neighbor aggregation captures structural information and calculates neighbors’ statistics. Experiments show that our GNAS can search for better GNNs with multiple message-passing mechanisms and optimal message-passing depth. The searched network achieves remarkable improvement over state-of-the-art manual designed and search based GNNs on five large-scale datasets at three classical graph tasks.
2. BiCnet-TKS: Learning Efficient Spatial-Temporal Representation for
Video Person Re-Identification (Ruibing Hou, Hong Chang, Bingpeng Ma, Rui Huang,
Shiguang Shan)
We present an
efficient spatial-temporal representation for video person re-identification
(reID). Firstly, we propose a Bilateral Complementary Network (BiCnet) for
spatial complementarity modeling. Specifically, BiCnet contains two branches.
Detail Branch processes frames at original resolution to preserve the detailed
visual clues, and Context Branch with a down-sampling strategy is employed to
capture longer-range contexts. On each branch, BiCnet appends multiple parallel
and diverse attention modules to discover divergent body parts for consecutive
frames, so as to obtain an integral characteristic of target identity.
Furthermore, a Temporal Kernel Selection (TKS) block is designed to capture
short-term as well as long-term temporal relations by an adaptive mode. TKS can be inserted into BiCnet at any depth
to construct BiCnet-TKS for spatial-temporal modeling. Experimental results on
two benchmarks show that BiCnet-TKS outperforms state-of-the-arts with about 50%
less computations.

3. FAIEr: Fidelity and Adequacy Ensured
Image Caption Evaluation (Sijin Wang, Ziwei Yao, Ruiping Wang, Zhongqin Wu,
Xilin Chen)
Image caption evaluation is a crucial task,
which involves the semantic perception and matching of image and text. Good
evaluation metrics aim to be fair, comprehensive, and consistent with human
judge intentions. When humans evaluate a caption, they usually consider
multiple aspects, such as whether it is related to the target image without
distortion, how much image gist it conveys, as well as how fluent and beautiful
the language and wording is. The above three different evaluation orientations
can be summarized as fidelity, adequacy, and fluency. The former two rely on
the image content, while fluency is purely related to linguistics and more
subjective. Inspired by human judges, we propose a learning-based metric named
FAIEr to ensure evaluating the fidelity and adequacy of the captions. Since
image captioning involves two different modalities, we employ the scene graph
as a bridge between them to represent both images and captions. FAIEr mainly
regards the visual scene graph as the criterion to measure the fidelity. Then
for evaluating the adequacy of the candidate caption, it highlights the image
gist on the visual scene graph under the guidance of the reference captions.
Comprehensive experimental results show that FAIEr has high consistency with
human judgment as well as high stability, low reference dependency, and the
capability of reference-free evaluation.
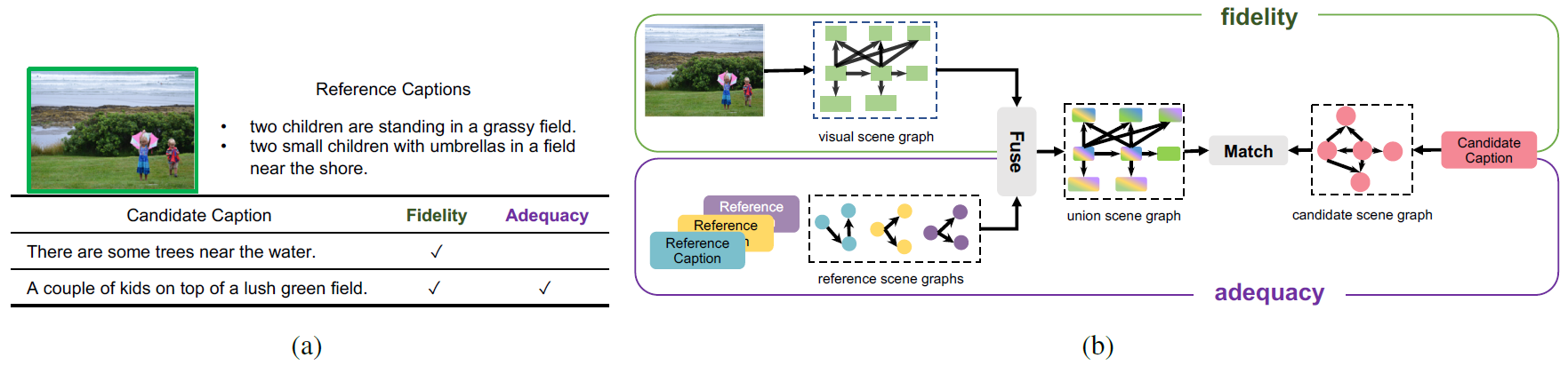
Figure
1. (a) An example image with human-labeled reference captions (from MS COCO)
and two candidates, showing the criterion of fidelity and adequacy. (b) The
designing principle of FAIEr.
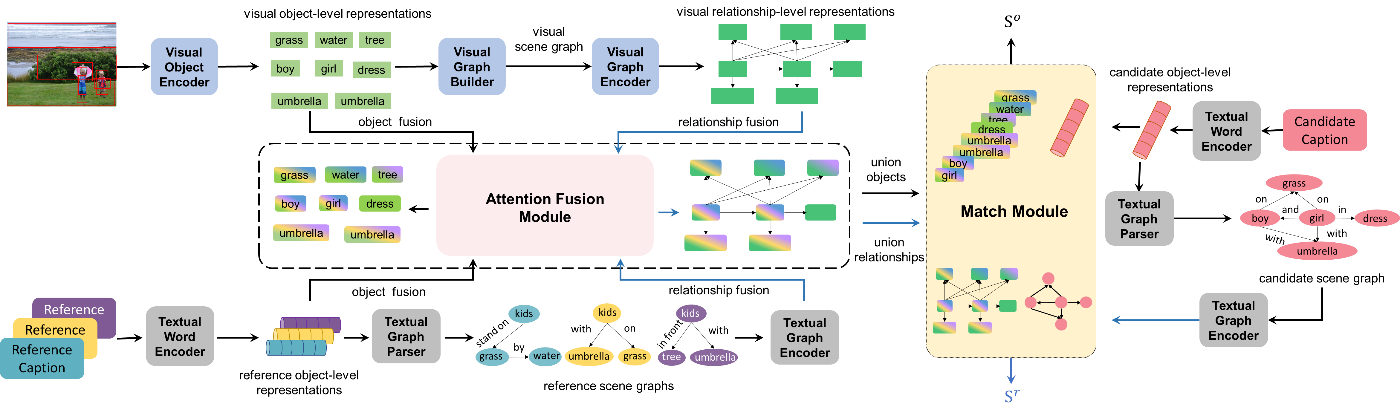
Figure
2. The framework of the image caption evaluation metric FAIEr.
4. Seeking the Shape of Sound: An Adaptive
Framework for Learning Voice-Face Association (Peisong Wen, Qianqian Xu, Yangbangyan, JiangZhiyong
Yang, Yuan He, Qingming Huang)
Relevant studies have shown that the face and voice of the same person are
related to a certain extent, which can be learned by machine learning models. However, most of the prior arts
along this line (a) merely
adopt local information to perform modality alignment and (b) ignore the diversity of learning
difficulty across
different subjects. In this paper, a novel framework is proposed to jointly address the
above-mentioned issues. Targeting at (a), we propose a two-level modality alignment loss where both global and local information
are considered. Compared with the existing methods, this work introduce a global loss into the modality
alignment process. Theoretically, minimizing the loss could maximize the distance between
embeddings across different identities while minimizing the distance between
embeddings belonging to the same identity, in a global sense (instead of a mini-batch).
Targeting at (b), a dynamic
reweighting scheme is proposed to better
explore the hard but valuable identities while filtering out the unlearnable identities.
Experiments show that the proposed method outperforms the previous methods in
multiple settings, including, voice-face matching, verification and retrieval.
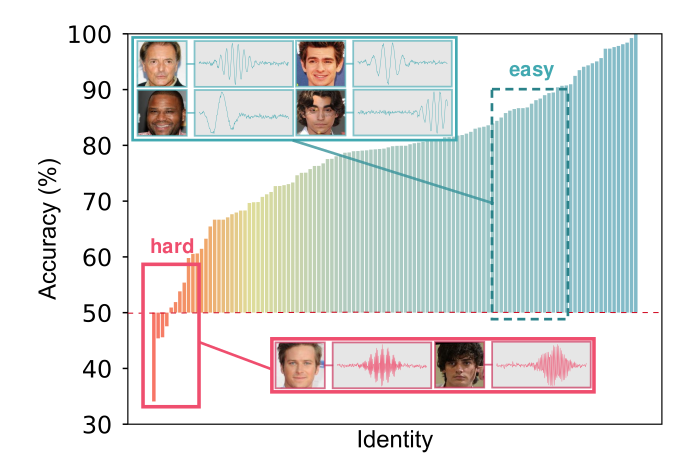
Figure
1. The diversity of
learning difficulty across different subjects. The test accuracy of different subjects varies
greatly.
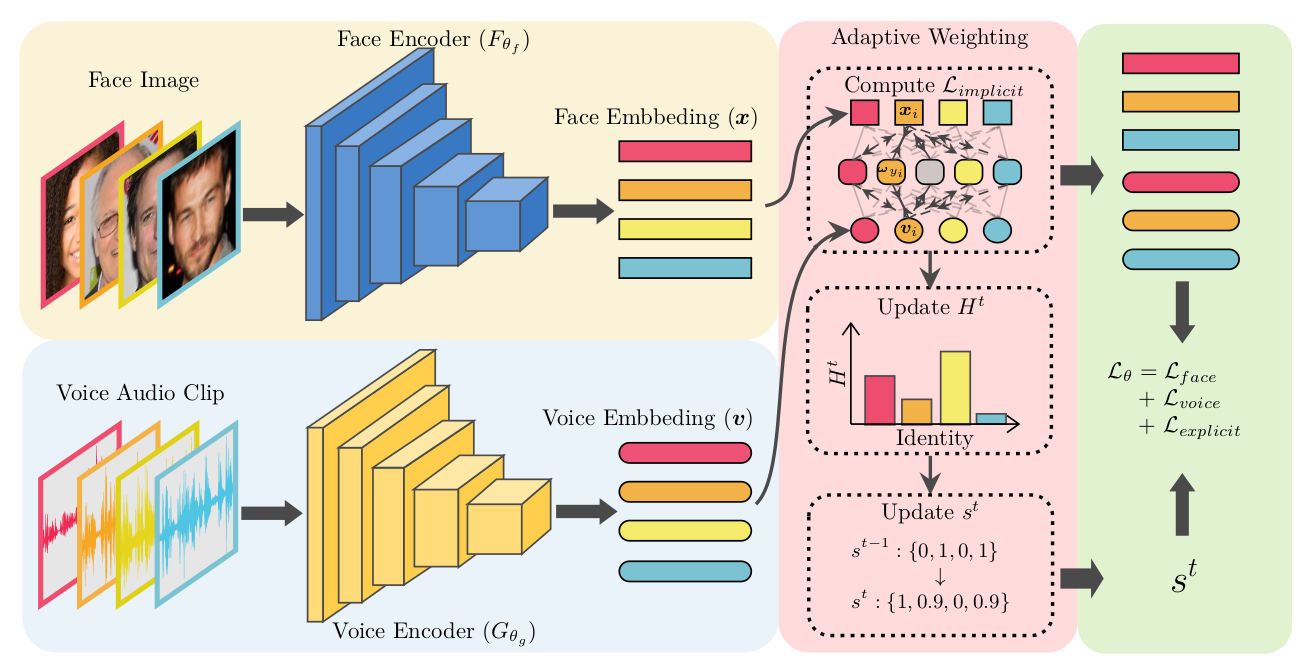
Figure 2. An overview of the proposed
method.
Download: