Congratulations! The laboratory has 3 papers accepted by AAAI 2022. AAAI Conference on Artificial Intelligence, referred as AAAI, is a top international conference on artificial intelligence. The summarized information of the three papers is as follows:
1. Towards High-Fidelity Face Self-occlusion Recovery via Multi-view Residual-based GAN Inversion. (Jinsong Chen, Hu Han, Shiguang Shan)
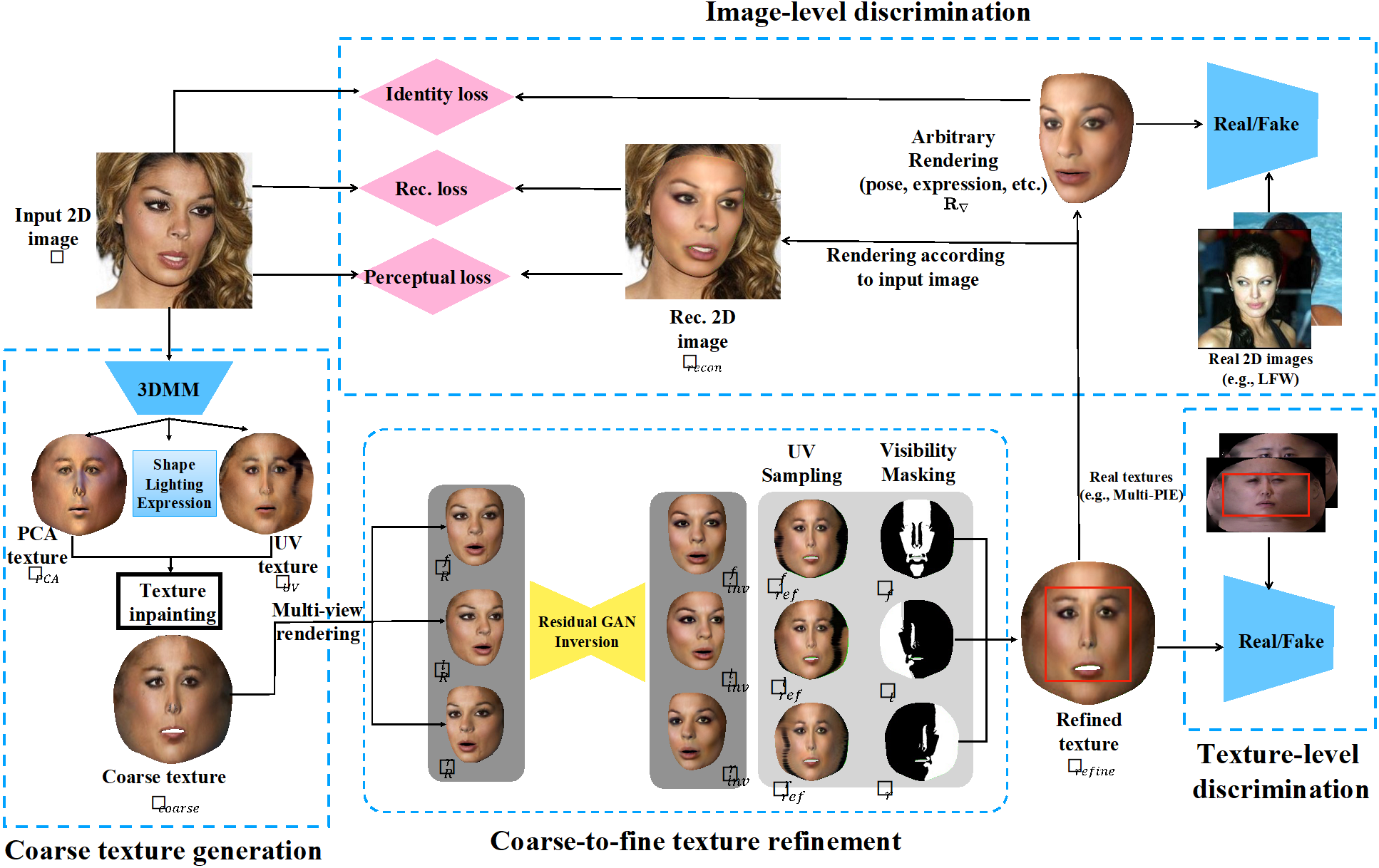
Face self-occlusions are inevitable due to the 3D nature of the human face and the loss of information in the projection process from 3D to 2D images. While recovering face self- occlusions based on 3D face reconstruction, e.g., 3D Morphable Model (3DMM) and its variants provides an effective solution, most of the existing methods show apparent limitations in expressing high-fidelity, natural, and diverse facial details. To overcome these limitations, we propose in this paper a new generative adversarial network (MvInvert) for natural face self-occlusion recovery without using paired image-texture data. We design a coarse-to-fine generator for photorealistic texture generation. A coarse texture is computed by inpainting the invisible areas in the photorealistic but incomplete texture sampled directly from the 2D image using the unrealistic but complete statistical texture from 3DMM. Then, we design a multi-view Residual-based GAN Inversion, which re-renders and refines multi-view 2D images, which are used for extracting multiple high-fidelity textures. Finally, these high-fidelity textures are fused based on their visibility maps via Poisson blending. To perform adversarial learning to assure the quality of the recovered texture, we design a discriminator consisting of two heads, i.e., one for global and local discrimination between the recovered texture and a small set of real textures in UV space, and the other for discrimination between the input image and the rerendered 2D face images via pixel-wise, identity, and adversarial losses. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods in face self-occlusion recovery under unconstrained scenarios.
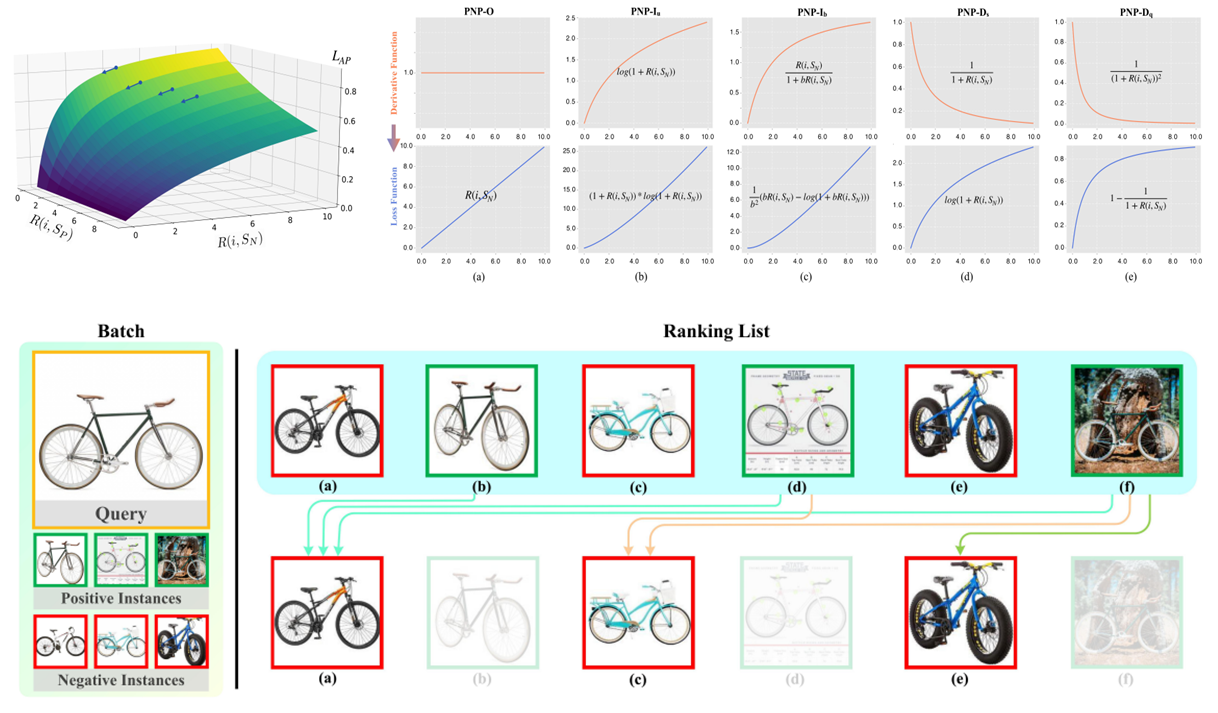
2. Rethinking the Optimization of Average Precision: Only Penalizing Negative Instances before Positive Ones is Enough. (Zhuo Li, Weiqing Min, Jiajun Song, Yaohui Zhu, Liping Kang, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang)
3. Unsupervised Coherent Video Cartoonization with Perceptual Motion Consistency. (Zhenhuan Liu, Liang Li, Huajie jiang, Xin Jin, Dandan Tu, Shuhui Wang, Zheng-Jun Zha)
In recent years, creative content generations like style transfer and neural photo editing have attracted more and more attention. Among these, cartoonization of real-world scenes has promising applications in entertainment and industry. Different from image translations focusing on improving the style effect of generated images, video cartoonization has additional requirements on the temporal consistency. In this paper, we propose a spatially-adaptive semantic alignment framework with perceptual motion consistency for coherent video cartoonization in an unsupervised manner. The semantic alignment module is designed to restore deformation of semantic structure caused by spatial information lost in the encoder-decoder architecture. Furthermore, we introduce the spatio-temporal correlative map as a style-independent, global-aware regularization on perceptual motion consistency. Deriving from similarity measurement of high-level features in photo and cartoon frames, it captures global semantic information beyond raw pixel-value of optical flow. Besides, the similarity measurement disentangles temporal relationship from domain-specific style properties, which helps regularize the temporal consistency without hurting style effects of cartoon images. Qualitative and quantitative experiments demonstrate our method is able to generate highly stylistic and temporal consistent cartoon videos.

Download: