Congratulations! The laboratory has 2 papers accepted by WACV 2022. WACV Conference on IEEE Workshop on Applications of Computer Vision, referred as WACV, is a top international conference on computer vision. The summarized information of the two papers is as follows:
1. From Node to Graph: Joint Reasoning on Visual-Semantic Relational Graph for Zero-Shot Detection. (Hui Nie, Ruiping Wang, Xilin Chen)
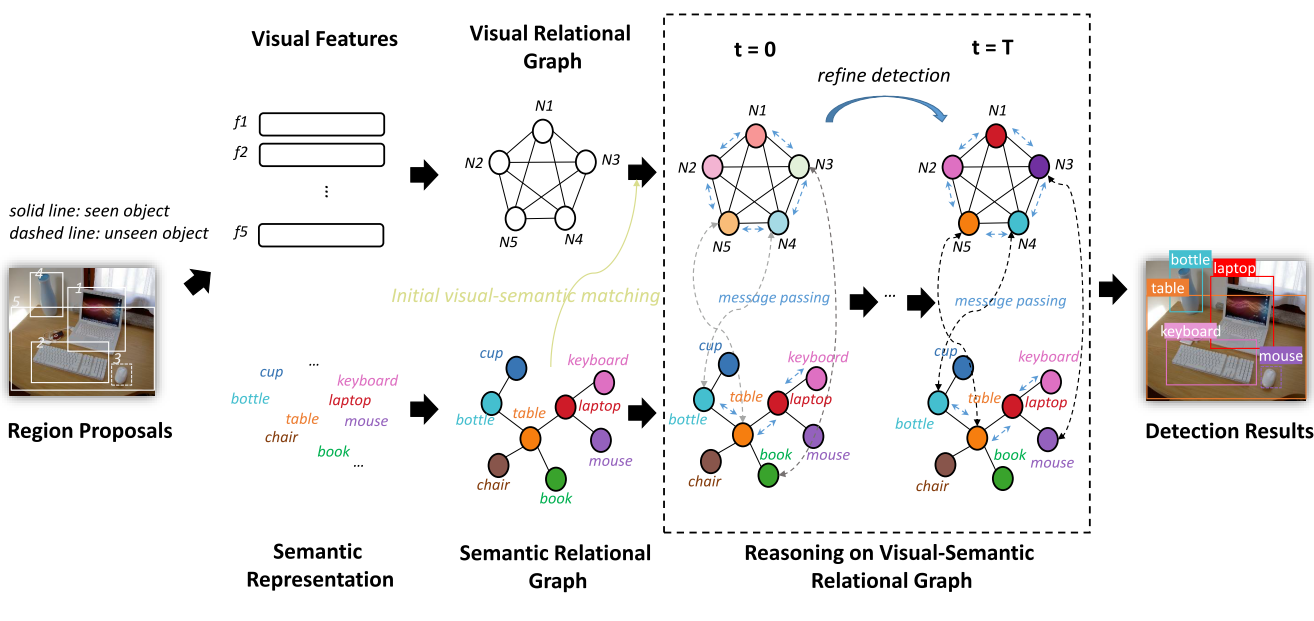
Zero-Shot Detection (ZSD), which aims at localizing and recognizing unseen objects in a complicated scene, usually leverages the visual and semantic information of individual objects alone. However, scene understanding of human exceeds recognizing individual objects separately: the contextual information among multiple objects such as visual relational information (e.g. visually similar objects) and semantic relational information (e.g. co-occurrences) is helpful for understanding of visual scene. In this paper, we verify that contextual information plays a more important role in ZSD than in traditional object detection. To make full use of such information, we propose a new end-to-end ZSD method GRaph Aligning Network (GRAN) based on graph modeling and reasoning which simultaneously considers visual and semantic information of multiple objects instead of individual objects. Specifically, we formulate a Visual Relational Graph (VRG) and a Semantic Relational Graph (SRG), where the nodes are the objects in the image and the semantic representations of classes respectively and the edges are the relevance between nodes in each graph. To characterize mutual effect between two modalities, the two graphs are further merged into a heterogeneous Visual-Semantic Relational Graph (VSRG), where modal translators are designed for the two subgraphs to enable modal information to transform into a common space for communication, and message passing among nodes is enforced to refine their representations. Comprehensive experiments on MSCOCO dataset demonstrate the advantage of our method over state-of-the-arts, and qualitative analysis suggests the validity of using contextual information.
2. SEGA: Semantic Guided Attention on Visual Prototype for Few-Shot Learning. (Fengyuan Yang, Ruiping Wang, Xilin Chen)
Teaching
machines to recognize a new category based on few training samples especially
only one remains challenging owing to the incomprehensive understanding of the
novel category caused by the lack of data. However, human can learn new classes
quickly even given few samples since human can tell what discriminative
features should be focused on about each category based on both the visual and
semantic prior knowledge. To better utilize those prior knowledge, we propose
the SEmantic Guided Attention (SEGA) mechanism where the semantic knowledge is
used to guide the visual perception in a top-down manner about what visual
features should be paid attention to when distinguishing a category from the
others. As a result, the embedding of the novel class even with few samples can
be more discriminative. Concretely, a feature extractor is trained to embed few
images of each novel class into a visual prototype with the help of
transferring visual prior knowledge from base classes. Then we learn a network
that maps semantic knowledge to category-specific attention vectors which will
be used to perform feature selection to enhance the visual prototypes.
Extensive experiments on miniImageNet, tieredImageNet, CIFAR-FS, and CUB
indicate that our semantic guided attention realizes anticipated function and
outperforms state-of-the-art results.

Download: