Congratulations! VIPL's 3 papers are accepted by NeurIPS (Annual Conference on Neural Information Processing Systems) 2023! NeurIPS is a top-tier conference in the field of machine learning and pattern recognition. The conference will be held in New Orleans, United States from December 10 to 16, 2023.
The accepted papers are summarized as follows:
1. Minyang Hu, Hong Chang, Zong Guo, Bingpeng Ma, Shiguang Shan, Xilin Chen. Understanding Few-Shot Learning: Measuring Task Relatedness and Adaptation Difficulty via Attributes.
Few-shot learning (FSL) aims to learn novel tasks with very few labeled samples by leveraging experience from related training tasks. In this paper, this paper tries to understand FSL by exploring two key questions: (1) How to quantify the relationship between training and novel tasks? (2) How does the relationship affect the adaptation difficulty on novel tasks for different models? To answer the first question, this paper proposes Task Attribute Distance (TAD) as a metric to quantify the task relatedness via attributes. Unlike other metrics, TAD is independent of models, making it applicable to different FSL models. To address the second question, this paper utilizes TAD metric to establish a theoretical connection between task relatedness and task adaptation difficulty. By deriving the generalization error bound on a novel task, this paper discovers how TAD measures the adaptation difficulty on novel tasks for different models. To validate our theoretical results, this paper conducts experiments on three benchmarks. Our experimental results confirm that TAD metric effectively quantifies the task relatedness and reflects the adaptation difficulty on novel tasks for various FSL methods, even if some of them do not learn attributes explicitly or human-annotated attributes are not provided.
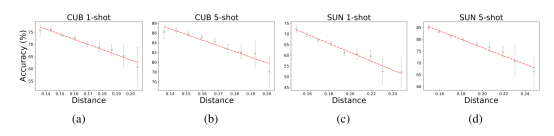
Figure 1 Accuracy on novel tasks in term of average task distance.
2. Jiachen Liang, Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen. Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation.
Traditional semi-supervised learning (SSL) assumes that the feature distributions of labeled and unlabeled data are consistent which rarely holds for realistic scenarios. Here, this paper introduces a novel FDM-SSL setting to formalize the concept that feature distribution mismatch may appear between the labeled and unlabeled samples. Previous SSL methods mostly predict pseudo-labels with the current model, resulting in noise accumulation when the pseudo-labels are inaccurate. To tackle this issue, this paper proposes Self-Supervised Feature Adaptation (SSFA), a generic framework for improving SSL performance when labeled and unlabeled data come from different distributions. SSFA decouples the prediction of pseudo-labels from the current model to improve the quality of pseudo-labels. Particularly, SSFA incorporates a self-supervised task into the SSL framework and uses it to adapt the feature extractor of the model to the unlabeled data. In this way, the extracted features better fit the distribution of unlabeled data, thereby generating high-quality pseudo-labels. Extensive experiments show that our proposed SSFA is applicable to any pseudo-label-based SSL learner and significantly improves performance in labeled, unlabeled, and even unseen distributions.
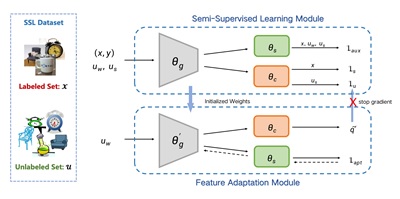
Figure 2 Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation.
3. Huiyang Shao, Qianqian Xu, Zhiyong Yang, Peisong Wen, Gao Peifeng, Qingming Huang. Weighted ROC Curve in Cost Space: Extending AUC to Cost-Sensitive Learning.
Receiver Operating Characteristics (ROC) is a commonly used tool to describe the trade-off between True Positive Rate (TPR) and False Positive Rate (FPR) of a scoring function. Area Under the Curve (AUC) is defined as the area under the ROC curve. This metric naturally measures the average classification performance under different thresholds and is widely employed. Similar to optimizing AUC, cost-sensitive learning is a prevalent method in data mining. Its primary objective is to incorporate the costs of misclassification into the model, making it more compatible with real-life scenarios. This paper aims to address the flexible cost demands of long-tailed datasets, requiring the development of a learning framework that is both (1) cost-sensitive and (2) robust to class distribution. Misclassification cost and AUC are commonly used indicators for (1) and (2). However, due to the limitations of their forms, models trained with AUC cannot be applied to cost-sensitive decision problems, while models trained with fixed costs are sensitive to shifts in class distribution. To tackle this issue, this paper proposes a novel scenario where costs are treated as a dataset to handle arbitrary unknown cost distributions. Additionally, this paper introduces a novel weighted version of AUC that incorporates the cost distribution into its calculation through decision thresholds. To formulate this scenario, this paper presents a novel two-layer optimization paradigm to bridge the gap between weighted AUC (WAUC) and costs. The inner problem approximates the optimal threshold from sampled costs, while the outer problem minimizes WAUC loss over the optimal threshold distribution. To optimize this bilevel paradigm, this paper employs a stochastic optimization algorithm (SACCL) with the same convergence rate (O(ε-4)) as stochastic gradient descent (SGD). Finally, experimental results demonstrate the superior performance of our algorithm compared to existing cost-sensitive learning methods and two-stage AUC decision approaches.
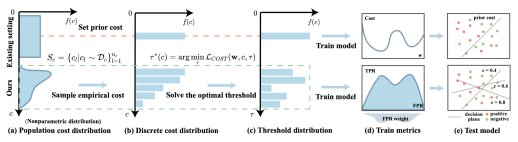
Figure 3 The training process of WAUC and comparison between the existing algorithms.
Download: