Congratulations! VIPL's three paper are accepted by ICLR 2024 on Jan. 16th, 2024! ICLR is a newly top international conference on deep learning and its applications. In this year, ICLR will be held in Vienna Austria on May 7th through the 11th.The paper is summarized as follows :
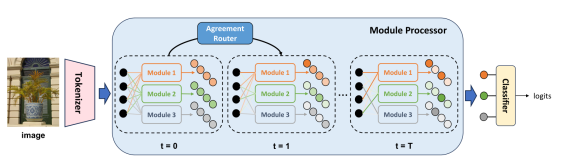
1. Scalable Modular Network: A Framework for Adaptive Learning via Agreement Routing (Minyang Hu, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen)
In this paper, we propose a novel modular network framework, called Scalable Modular Network (SMN), which enables adaptive learning capability and supports integration of new modules after pre-training for better adaptation. This adaptive capability comes from a novel design of router within SMN, named agreement router, which selects and composes different specialist modules through an iterative message passing process. The agreement router iteratively computes the agreements among a set of input and outputs of all modules to allocate inputs to specific module. During the iterative routing, messages of modules are passed to each other, which improves the module selection process with consideration of both local interactions (between a single module and input) and global interactions involving multiple other modules. To validate our contributions, we conduct experiments on two problems: a toy min-max game and few-shot image classification task. Our experimental results demonstrate that SMN can generalize to new distributions and exhibit sample-efficient adaptation to new tasks. Furthermore, SMN can achieve a better adaptation capability when new modules are introduced after pre-training.
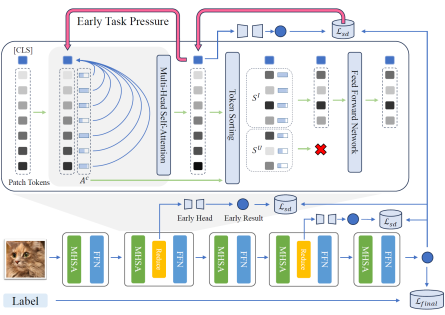
2. A Simple Romance Between Multi-Exit Vision Transformer and Token Reduction (Dongyang Liu, Meina Kan, Shiguang Shan, Xilin CHEN)
Despite the widespread success of Vision Transformers (ViTs), their high computational cost significantly impacts practical applications. Token reduction is an effective acceleration technique that reduces the overall computational load of the model by identifying and discarding irrelevant tokens during forward propagation. Since the token is responsible for gathering useful information and forming the task output, its attention score for the remaining tokens is often used as a measure of token importance. However, token reduction is applied in the earlier stages of the model, while task-related pressure is only applied at the end of the entire model. Due to the considerable distance between these stages, in the early network layers, the token may lack the impetus to collect task-relevant information, leading to relatively arbitrary attention allocation. To address this issue, inspired by the multi-exit structures in the dynamic network domain, we propose Multi-Exit Token Reduction (METR). By introducing early-exit heads, it forces the token to collect task-relevant information even in shallow layers, thereby improving the consistency between its attention allocation and token importance. On this basis, we introduce self-distillation loss to further enhance model accuracy. Extensive experiments demonstrate that our method can stably and significantly improve model performance after token reduction.
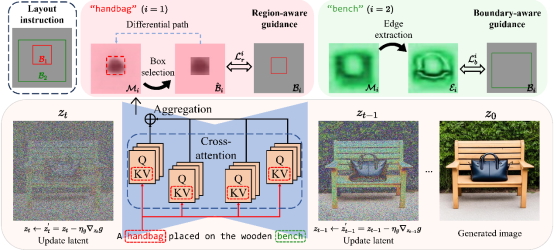
3. R&B: Region and Boundary Aware Zero-shot Grounded Text-to-image Generation (Jiayu Xiao, Henglei Lv, Liang Li, Shuhui Wang, Qingming Huang)
Recent text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images given text-prompts as input. However, these models fail to convey appropriate spatial composition specified by a layout instruction. In this work, we probe into zero-shot grounded T2I generation with diffusion models, that is, generating images corresponding to the input layout information without training auxiliary modules or finetuning diffusion models. We propose a Region and Boundary (R&B) aware cross-attention guidance approach that gradually modulates the attention maps of diffusion model during generative process, and assists the model to synthesize images (1) with high fidelity, (2) highly compatible with textual input, and (3) interpreting layout instructions accurately. Specifically, we leverage the discrete sampling to bridge the gap between consecutive attention maps and discrete layout constraints, and design a region-aware loss to refine the generative layout during diffusion process. We further propose a boundary-aware loss to strengthen object discriminability within the corresponding regions. Experimental results show that our method outperforms existing state-of-the-art zero-shot grounded T2I generation methods by a large margin both qualitatively and quantitatively on several benchmarks.
Download: