Congratulations! CVPR2019 shows that there are VIPL's 11 papers are accepted! CVPR is a top international conference on computer vision, pattern recognition and artificial intelligence hosted by IEEE. CVPR2019 will be held in California, USA, in June 2019.
The received 11 papers are summarized as follows:
1. VRSTC: Occlusion-Free Video Person Re-Identification (Ruibing Hou, Bingpeng Ma, Hong Chang, Xinqian Gu, Shiguang Shan, Xilin Chen)
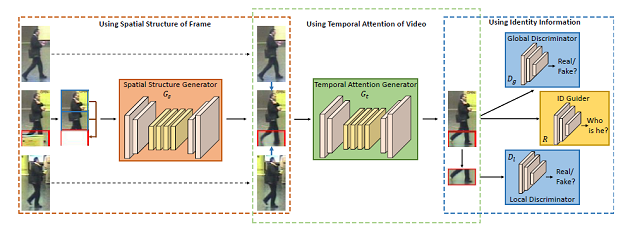
In order to handle the partial occlusion problem in video person re-identification (reID), we propose a novel network, called Spatio-Temporal Completion network (STCnet), to explicitly recover the appearance for the occluded parts. For one thing, the spatial structure of a pedestrian frame can be used to predict the occluded body parts from the unoccluded body parts of this frame. For another, the temporal patterns of pedestrian sequence provide import clues to generate the contents of occluded parts. By combining a reID network with STCnet, a video reID framework robust to partial occlusion is proposed. Experiments on three challenging video reID databases (iLIDS-VID, MARS, and DukeMTMC-VideoReID) demonstrate that the proposed approach outperforms the state-of-the-art approach.
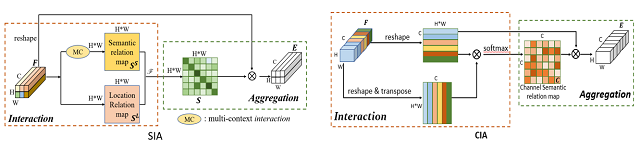
2. Interaction-and-Aggregation Network for Person Re-identification (Ruibing Hou, Bingpeng Ma, Hong Chang, Xinqian Gu, Shiguang Shan, Xilin Chen)
Convolutional neural networks (CNNs) are inherently limited in modeling the large variations in person pose and scale due to their fixed geometric structure. We propose a novel network structure, Interaction-and-Aggregation (IA), to enhance the feature representation capability of CNNs. Firstly, Spatial IA module models the interdependencies between spatial features and then aggregates the correlated features corresponding to the same body parts. Unlike CNNs which extract features from fixed rectangle regions, SIA can adaptively determine the receptive fields according to the input person pose and scale. Secondly, we introduce Channel IA module which selectively aggregates channel features to enhance the feature representation.We validate the effectiveness of our model for person reID by demonstrating its superiority over state-of-the-art methods on three benchmark datasets.
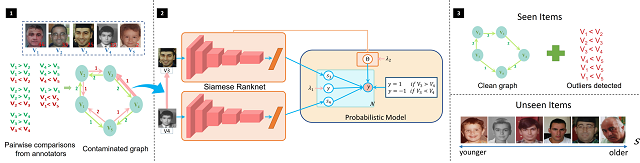
3. Deep Robust Subjective Visual Property Prediction in Crowdsourcing(Qianqian Xu, Zhiyong Yang, Yangbangyan Jiang, Xiaochun Cao, Qingming Huang,Yuan Yao)
The problem of estimating subjective visual properties (SVP) of images is gaining rising attention. Due to its highly subjective nature, different annotators often exhibit different interpretations of scales when adopting absolute value tests. Therefore, recent investigations turn to collect pairwise comparisons via crowdsourcing platforms. However, crowdsourcing data usually contains outliers. For this purpose, it is desired to develop a robust model for learning SVP from crowdsourced noisy annotations. In this paper, we construct a deep SVP prediction model which not only leads to better detection of annotation outliers but also enables learning with extremely sparse annotations. Specifically, we construct a comparison multi-graph based on the collected annotations, where different labeling results correspond to edges with different directions between two vertexes. Then, we propose a generalized deep probabilistic framework which consists of an SVP prediction module and an outlier modeling module that work collaboratively and are optimized jointly. Extensive experiments on various benchmark datasets demonstrate that our new approach guarantees promising prediction performance and effective outlier detection.
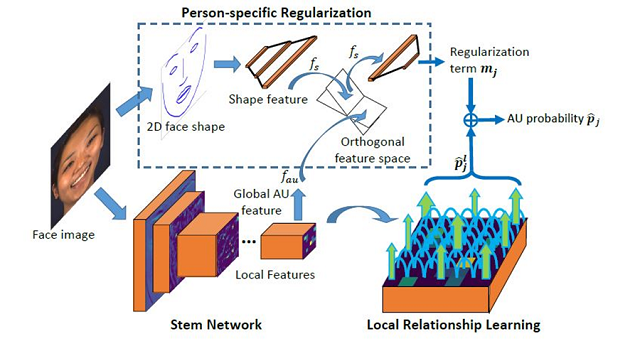
4. Relationship Learning with Person-specific Regularization for Facial Action Unit Detection(Xuesong Niu, Hu Han, SongFan Yang, Yan Huang, Shiguang Shan)
Encoding individual facial expressions via action units (AUs) coded by the Facial Action Coding System (FACS) has been found to be an effective approach in resolving the ambiguity issue among different expressions. While a number of methods have been proposed for AU detection, robust AU detection in the wild remains a challenging problem because of the diverse baseline AU intensities across individual subjects, and the weakness of appearance signal of AUs. To resolve these issues, we propose a novel AU detection method by utilizing local information and the relationship of individual local face regions. Through such a local relationship learning, we expect to utilize rich local information to improve the AU detection robustness against the potential perceptual inconsistency of individual local regions. In addition, considering the diversity in the baseline AU intensities of individual subjects, we further regularize local relationship learning via person-specific face shape information, i.e., reducing the influence of person-specific shape information, and obtaining more AU discriminative features. The proposed approach achieves the best results on two widely used AU detection datasets in the public domain (BP4D and DISFA).
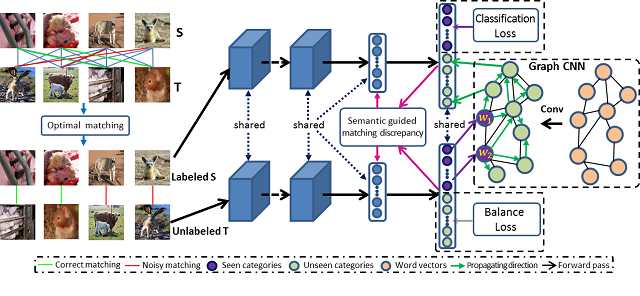
5. Unsupervised Open Domain Recognition by Semantic Discrepancy Minimization (Junbao Zhuo, Shuhui Wang, Shuhao Cui, Qingming Huang)
In this work, we explore the field of unsupervised open domain recognition, which is a more realistic scenario where the categories of labeled source domain is a subset of the categories of unlabeled target domain and domain discrepancy exits between the two domain. This is a very difficult setting as there exists both domain shift and semantic bias between source and target domain. Directly propagating the classifier trained on source domain to unseen categories of target domain via graph CNN is suboptimal. It is straightforward to reduce the domain discrepancy but it is hard to estimate the domain discrepancy of asymmetric label spaces. Directly reducing existing discrepancy measurement will result in negative transfer. Therefore, we propose semantic guided matching discrepancy that first search an optimal matching between source and target domain instances and then use semantic consistency of coarse matched pairs to filter noisy matching. On the other hand, we propose limited balance constraint to alleviate the semantic embedding bias. Semantic embedding bias means that without labels for unknown categories, the classification network will misclassify the unknown samples into known categories. Finally, we integrate graph CNN to jointly train the classification network and graph CNN for better preserving the semantic structure encoded in word vectors and knowledge graph. We collect two datasets for unsupervised open domain recognition problem and evaluation on these datasets show the effectiveness of our methods.
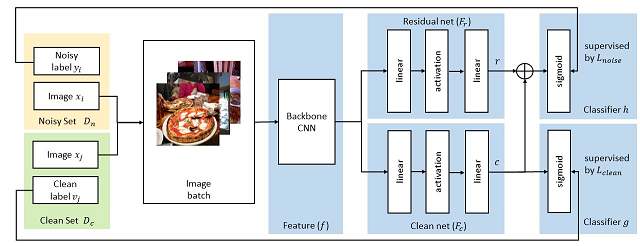
6. Weakly Supervised Image Classification through Noise Regularization ( Mengying Hu,Hu Han,Shiguang Shan,Xilin Chen)
Weakly supervised learning is an essential problem in computer vision tasks, such as image classification, object recognition, etc., because it is expected to work in the scenarios where a large dataset with clean labels is not available. While there are a number of studies on weakly supervised image classification, they usually limited to either single-label or multi-label scenarios. In this work, we propose an effective approach for weakly supervised image classification utilizing massive noisy labeled data with only a small set of clean labels (e.g., 5%). The proposed approach consists of a stem net, a clean net, and a residual net. The stem net is used for shared feature learning. The clean net and the residual net are responsible for learning a mapping from feature space to clean label space and a residual mapping from feature space to the residual between clean labels and noisy labels, respectively. Thus, the residual net works as a regularization term to improve the clean net training. We evaluate the proposed approach on two multi-label datasets (OpenImage and MS COCO2014) and a single-label dataset (Clothing1M). Experimental results show that the proposed approach outperforms the state-of-the-art methods, and generalizes well to both single-label and multi-label scenarios.
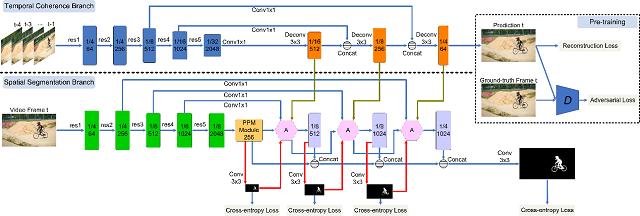
7. Spatiotemporal CNN for Video Object Segmentation (Kai Xu, Longyin Wen, Guorong Li, Liefeng Bo, Qingming Huang)
The video object segmentation
(VOS) achieves an impressive advance with the arriving of deep convolutionalneural
network (CNN). To capture the temporal coherence,most
of existing methods rely on optical flow, which requiresa
large amount of expensive human annotations and is often inaccurate in
estimation. To that end, we propose a unified, end-to-end trainable spatiotemporal
CNN model for
VOS without relying on optical flow, which consists
of twobranches,i.e.,
the temporal coherence branch and the spatial segmentation branch.
Specifically, the temporal coherence branch pretrained in an adversarial
fashion from unlabeled video data, is designed to capture the dynamic
appearance and motion cues of video sequences to guide object segmentation. The
spatial segmentation branch focuses on segmenting objects accurately based on
the learnedappearance and motion cues. To
obtain accurate segmentation results, we design a coarse-to-fine process to
sequentially apply a designed attention module on multi-scale feature maps, and
concatenate them to produce the final prediction. In this way, the spatial
segmentation branch is enforced to gradually concentrate on object regions.
Thesetwo branches are jointly
fine-tuned on the video segmentation sequences in an end-to-end manner. Several
experiments are carried out on two challenging datasets (i.e.,DAVIS-2016
and Youtube-Object) to show that our methodachieves
favorable performance against the state-of-the arts.
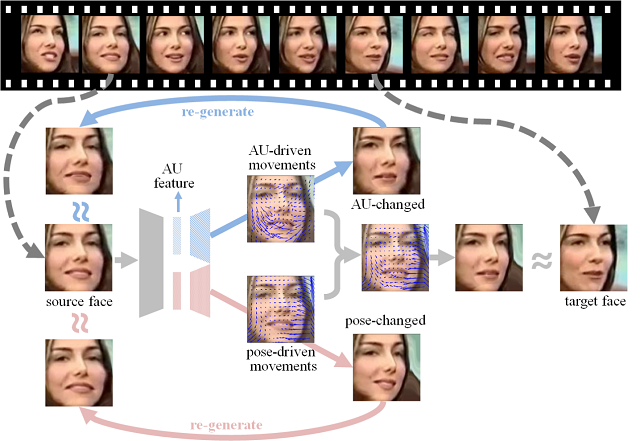
8. Twin-Cycle Autoencoder: Self-supervised Representation Learning from Entangled Movement for Facial Action Unit Detection (Yong Li, Jiabei Zeng, Shiguang Shan, Xilin Chen)
Facial action coding system (FACS) defined 44 facial action units (AUs) from an anatomical point of view. Action units help us analyze facial expression in an objective, precise, fine-grained manner. While the expensive cost of labeling AUs largely prohibits the progress of research on this issue. It is because various AUs cause subtle facial appearance changes over various regions at different scales. With an experienced FACS coder, manually coding 1 AU for a one-minute video can take 30 minutes or more. In this paper we propose to learn discriminative representation for facial action unit (AU) detection from large amount of videos without manually annotations. We sample two faces (the source face and the target face) of a subject from a video where she is talking and moving with varied expressions. TCAE is tasked to change the AUs and head poses of the source face to those of the target face by predicting the AU-driven and pose-driven movements, respectively. Thus, TCAE distils the information required to compute the AU- or pose-related movements separately into the corresponding embeddings. Experimental results show that TCAE can successfully disentangle the AU driven movements from the pose-driven ones. TCAE outperforms or is comparable to the state-of-the-art self-supervised learning methods and supervised AU detection methods.
9. Cascaded Partial Decoder for Fast and Accurate Salient Object Detection (Zhe Wu, Li Su, Qingming Huang)
Existing state-of-the-art salient object detection networks rely on aggregating multi-level features of pretrained convolutional neural networks (CNNs). However, compared to high-level features, low-level features contribute less to performance. Meanwhile, they raise more computational cost because of their larger spatial resolutions. In this paper, we propose a novel Cascaded Partial Decoder (CPD) framework for fast and accurate salient object detection. On the one hand, the framework constructs partial decoder which discards larger resolution features of shallow layers for acceleration. On the other hand, we observe that integrating features of deep layers will obtain relatively precise saliency map. Therefore, we directly utilize generated saliency map to recurrently optimize features of deep layers. This strategy efficiently suppresses distractors in the features and significantly improves their representation ability. Experiments conducted on five benchmark datasets exhibit that the proposed model not only achieves state-of-the-art but also runs much faster than existing models. Besides, we apply the proposed framework to optimize existing multi-level feature aggregation models and significantly improve their efficiency and accuracy.

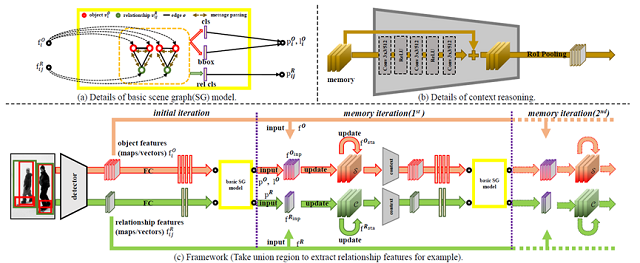
10. Exploring Context and Visual Pattern of Relationship for Scene Graph Generation (Wenbin Wang, Ruiping Wang, Shiguang Shan, Xilin Chen)
Scene graph generation helps higher-level scene understanding, while the relationship prediction is the core of scene graph generation. In object detection task, the construction of context and refinement of features have been widely explored, which are still unconsidered for relationships, however. In this paper, we propose a method to explore the context of relationship. All detected relationships are combined for implicit context construction. We prove the effectiveness of relationship context on benchmark dataset, Visual Genome, and capture its interpretability successfully. Meanwhile, we replace the traditional relationship feature extraction methods with our intersection box. The experiments show that it can focus more on real visual patterns of relationships and improve the performance of relationship prediction.
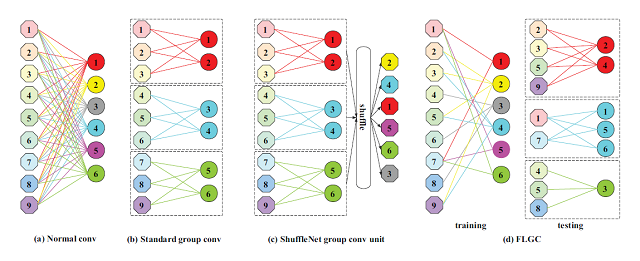
11. Fully Learnable Group Convolution for Acceleration of Deep Neural Networks (Xijun Wang, Meina Kan, Shiguang Shan, Xilin Chen)
Benefitted from its great success on many tasks, deep learning is increasingly used on low-computational-cost devices, e.g. smartphone, embedded devices etc. To reduce the high computational and memory cost, most existing methods attempt to accelerate a pre-trained model or design efficient network architecture. With the same goal, in this work, we propose a fully learnable group convolution module (FLGC for short) which is quite efficient and can be embedded in any deep neural networks for acceleration. Specifically, our proposed method automatically learns the group structure in the training stage in a fully end-to-end manner, leading to better structure than the existing pre-defined, two-steps, or iterative strategies. Moreover, our method can be further combined with depthwise separable convolution, resulting in 5$\\times$ acceleration than the vanilla Resnet50 on single CPU. An additional advantage is that in our FLGC the number of groups can be set as any value, but not necessarily $2^k$ as in most existing methods, meaning better tradeoff between accuracy and speed. As evaluated in our experiments, compared with standard group convolution, our method achieves better image classification accuracy when using the same number of groups.
Download: